












































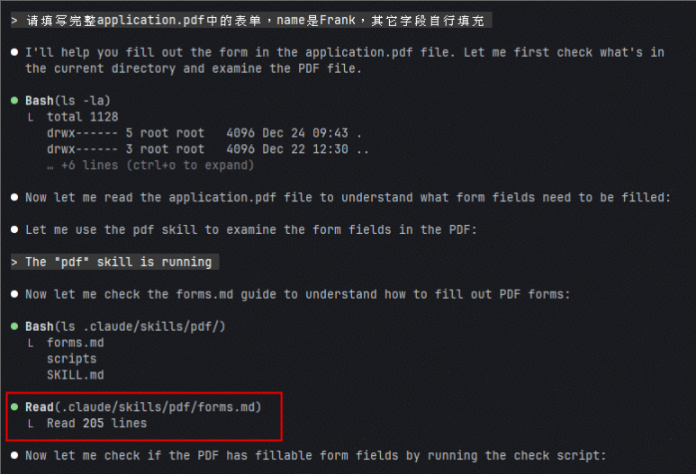
【导读】当AI Agent从“聊天”走向“做事”,上下文窗口很快被文件内容、搜索结果与多轮工具日志塞满,Context bloat problem随之成为工程瓶颈。近期,Claude Skills与LangChain SubAgents给出两条路径:前者用Skills把专业能力模块化,并通过progressive disclosure实现按需加载;后者用SubAgentMiddleware把高噪声任务隔离到子代理执行,主代理只接收结果。它们背后共同指向一个朴素但有效的设计哲学:分而治之。
一、从“全科医生困境”看传统Agent的三类痛点
以往大量基于prompt的对话式AI,常被当作“一个角色 + 一段超长指令”的通用系统:模型被期待既能写代码、又能读文档、还能查资料并生成报告。这个范式在简单问题上可用,但任务复杂度上来后,常暴露出三类硬伤。
第一类是上下文容量被快速挤爆。当Agent开始调用网络搜索、文件读取、数据库查询等工具,中间过程与raw data会持续注入上下文窗口。即便模型具备更长的context length,成本也会线性增长,而且噪声越多,越容易把关键约束“挤出”注意力范围。
第二类是专业深度被稀释。一个prompt想覆盖所有领域与边界条件,往往只能写成“百科式要求”,但落到具体任务(例如PDF表单填写、批量解析与校验)时,缺少领域化的流程约束、脚本工具与异常处理策略,结果要么不稳定,要么需要反复补prompt。
第三类是效率与可维护性瓶颈。当复杂任务需要多步推理与多次工具调用,模型会在同一上下文里来回“翻找”信息:既要记住目标,又要处理海量中间结果,还要遵循流程。对工程团队而言,这意味着prompt越来越长、越改越脆,调参成本高且难以复用。
Claude Skills与SubAgents分别从“知识/能力如何加载”和“过程/中间结果如何隔离”两个方向,尝试把这些问题拆开治理。
二、Claude Skills:把能力做成可发现的模块,并用progressive disclosure保持context clean
Claude Skills可以理解为一种面向Agent的能力封装规范:把某一类专业任务(如PDF处理)沉淀成可复用的技能包,并让Agent在需要时加载对应材料与工具权限,而不是把所有细节常驻在系统提示词中。
2.1 一个PDF Skills的目录形态:从SKILL.md到脚本集合
在实践中,一个skills通常以目录的方式存在,并以SKILL.md作为入口文件。典型流程是先在项目目录创建:
- .claude/skills/pdf/
- 在其中编写SKILL.md,内容由Frontmatter(metadata)+ Instructions(操作指导)组成,例如(节选):
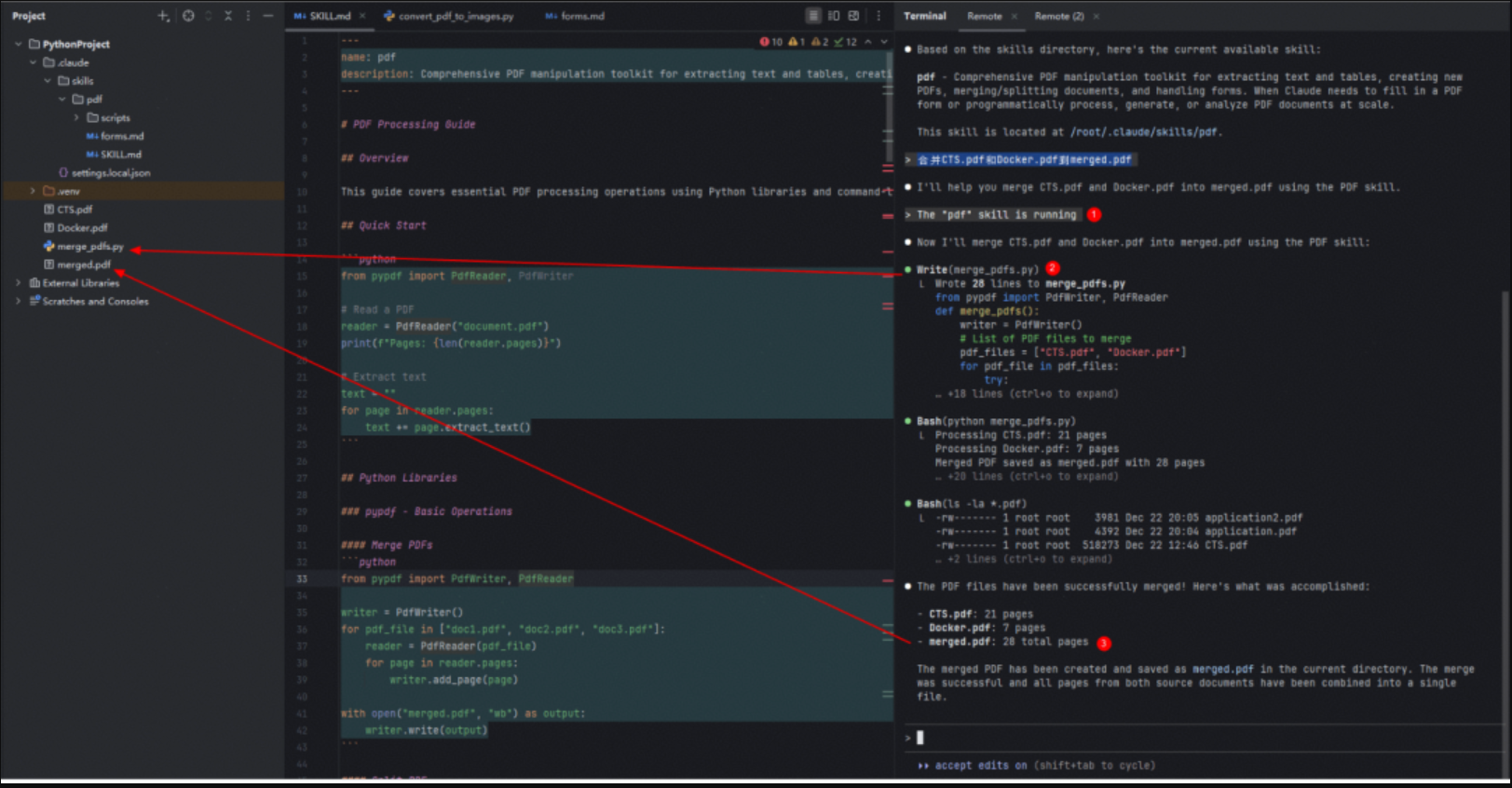
--- name: pdf description: Comprehensive PDF manipulation toolkit for extracting text and tables, creating new PDFs, merging/splitting documents, and handling forms. When Claude needs to fill in a PDF form or programmatically process, generate, or analyze PDF documents at scale. --- # PDF Processing Guide ## Overview This guide covers essential PDF processing operations using Python libraries and command-line tools. For advanced features, JavaScript libraries, and detailed examples, see reference.md. If you need to fill out a PDF form, read forms.md and follow its instructions. ## Python Libraries ### pypdf - Basic Operations #### Merge PDFs from pypdf import PdfWriter, PdfReader writer = PdfWriter() for pdf_file in ["doc1.pdf", "doc2.pdf", "doc3.pdf"]: reader = PdfReader(pdf_file) for page in reader.pages: writer.add_page(page) with open("merged.pdf", "wb") as output: writer.write(output)
当任务从“合并PDF”升级到“PDF表单填写”这种多步骤复杂流程时,skills通常还会扩展出更细的说明文件与脚本工具,例如:
.claude/ ├── skills/ │ └── pdf/ │ ├── SKILL.md │ ├── forms.md │ └── scripts/ │ ├── check_fillable_fields.py │ ├── convert_pdf_to_images.py │ ├── extract_form_field_info.py │ ├── fill_fillable_fields.py │ └── fill_pdf_form_with_annotations.py
这种组织方式的关键不在“写了多少提示词”,而在于把复杂流程拆成“入口说明 + 分支文档 + 可执行脚本”的工程化资产,便于复用与迭代。
2.2 Skills发现与最小暴露:从metadata开始,而非全量塞进prompt
Skills被Agent识别的第一步,是“发现可用skills并读取metadata”。工程上通常会有固定的发现路径(例如个人目录与项目目录),然后只抽取Frontmatter形成可用技能清单。
当这些metadata被组装进System prompt时,常见形态类似xml(示例):
<available_skills> <skill> <name>pdf-processing</name> <description>Extracts text and tables from PDF files, fills forms, merges documents.</description> <location>/path/to/skills/pdf-processing/SKILL.md</location> </skill> <skill> <name>data-analysis</name> <description>Analyzes datasets, generates charts, and creates summary reports.</description> <location>/path/to/skills/data-analysis/SKILL.md</location> </skill> </available_skills>
这一步只让模型“知道有哪些专家可以叫”,但不把每个专家的厚手册都塞进上下文,从而把context开销控制在最小可用范围。
2.3 progressive disclosure:按需加载forms.md,任务结束再清理
Skills体系的核心机制之一是渐进式披露(progressive disclosure):先暴露最少信息(metadata),当模型确认需要某技能时,再加载SKILL.md的详细指导;如果指导里进一步指向更细文档(如forms.md),则再按需加载。
以PDF表单填写为例:SKILL.md在Overview里明确指出“如果需要fill out a PDF form,请阅读forms.md并按其指引执行”。当模型进入表单填写任务,它会按导航链路进一步读取forms.md,并调用脚本完成解析字段、填充、生成新PDF等步骤。
更关键的是:任务完成后应释放上下文。也就是说,forms.md这类重内容不应常驻在对话上下文里,避免后续任务被无关材料污染,维持context concise and clean。
从工程视角看,Skills把“知识规模”与“上下文规模”解耦:技能包可以无限增长,但每次任务只按需取用。
三、LangChain SubAgents:把高噪声过程隔离在子代理里,主代理只收敛结果
如果说Skills解决的是“专业知识与流程如何被模块化并按需加载”,那么SubAgents更像在解决另一类现实问题:工具调用链条过长导致的上下文污染。
当Agent执行网络搜索、长文档读取、数据库查询时,往往产生大量中间记录。SubAgents的策略是:把这些“会生成很多过程数据的工作”交给子代理,子代理在独立上下文窗口内完成多步调用与整理,最后只把结果(而非全过程日志)回传给Main Agent。
3.1 基于SubAgentMiddleware的一个包装示例
在LangChain的实现中,SubAgents可通过Middleware机制进行声明与注入。一个常见模式是:Main Agent负责目标理解与汇总;子代理负责“搜索/抓取/对比”这类高噪声任务。
示例代码(节选)中,将internet搜索封装为一个subagent,并通过SubAgentMiddleware注册:
from typing import Literal from deepagents.middleware.subagents import SubAgentMiddleware from langchain.agents import create_agent from langchain.agents.middleware import TodoListMiddleware from langchain_core.tools import tool from tavily import TavilyClient from DeepSeek_model import llm tavily_client = TavilyClient( api_key="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") @tool def internet_search( query: str, max_results: int = 2, topic: Literal["general", "news", "finance"] = "general", include_raw_content: bool = False, ): """Run a web search""" return tavily_client.search( query, max_results=max_results, include_raw_content=include_raw_content, topic=topic, verify=False # 如果支持的话 ) agent = create_agent( model=llm, system_prompt="Use subagents for specialized tasks.", middleware = [ TodoListMiddleware( system_prompt="Use the write_todos tool to help you manage and plan complex objectives" ), SubAgentMiddleware( default_model=llm, subagents=[ { "name": "web search", "description": "search in web, if you need to access internet", "system_prompt": "Use this to run an internet search for a given query.", "tools": [internet_search], "middleware": [], } ], ) ], ) result = agent.invoke({"messages": [{"role": "user", "content": "compare china hangzhou's today's temperature with yesterday"}]}) print(result["messages"][-1].content)
这里TodoListMiddleware偏向任务分解与过程管理,而SubAgentMiddleware定义了一个“web search”子代理类型:当主代理需要互联网数据时,通过task工具启动一个ephemeral subagent去执行。
3.2 SubAgents在prompt层的落点:Function Calling + task
无论上层封装看起来多“智能”,SubAgents最终仍会落到可被模型调用的工具描述上,常见就是Function Calling的tools定义,其中会出现类似task的函数,要求传入subagent_type与description。
示例(节选):
"tools": [ { "type": "function", "function": { "name": "task", "description": "Launch an ephemeral subagent to handle complex, multi-step independent tasks with isolated context windows.....", "parameters": { "properties": { "description": { "type": "string" }, "subagent_type": { "type": "string" } }, "required": ["description", "subagent_type"] } } } ]
因此,SubAgents的“本质收益”往往有两点:
- 上下文隔离:子代理处理raw data与多轮工具调用,主代理避免被过程淹没;
- 并行与吞吐:多个子代理可并发执行独立子任务,提高整体完成速度。
在一个“比较杭州今天与昨天温度”的任务里,主代理可以并行发起两个task调用,让两个web search subagent分别检索今日与昨日数据,然后主代理汇总对比结论。

结语:技术背后的管理思考
Claude Skills与LangChain SubAgents表面上在解决上下文爆炸与工具链路复杂化,深层其实是在把“复杂工作如何被组织起来”这一命题工程化:用模块化边界管理知识,用上下文隔离管理过程噪声,再通过协作与汇总机制交付结果。对企业而言,这会直接影响组织效率与岗位能力结构——一方面,业务流程会更适合被拆解为可复用的“技能组件”(类似标准作业、脚本与模板资产);另一方面,员工能力模型也会从“一个人全做”转向“会调度、会验收、会整合”,即更强调任务分解、质量控制与跨系统协同。尤其在HR与共享服务场景中,招聘筛选、入转调离、员工问答、报表生成等流程天然具备“高重复 + 高规则 + 多系统调用”的特征,更需要通过能力封装与上下文治理来降低成本、提升一致性。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把复杂流程变成可管理的模块,让人从低效的细节处理中释放出来,专注于更高价值的决策与协作。









