












































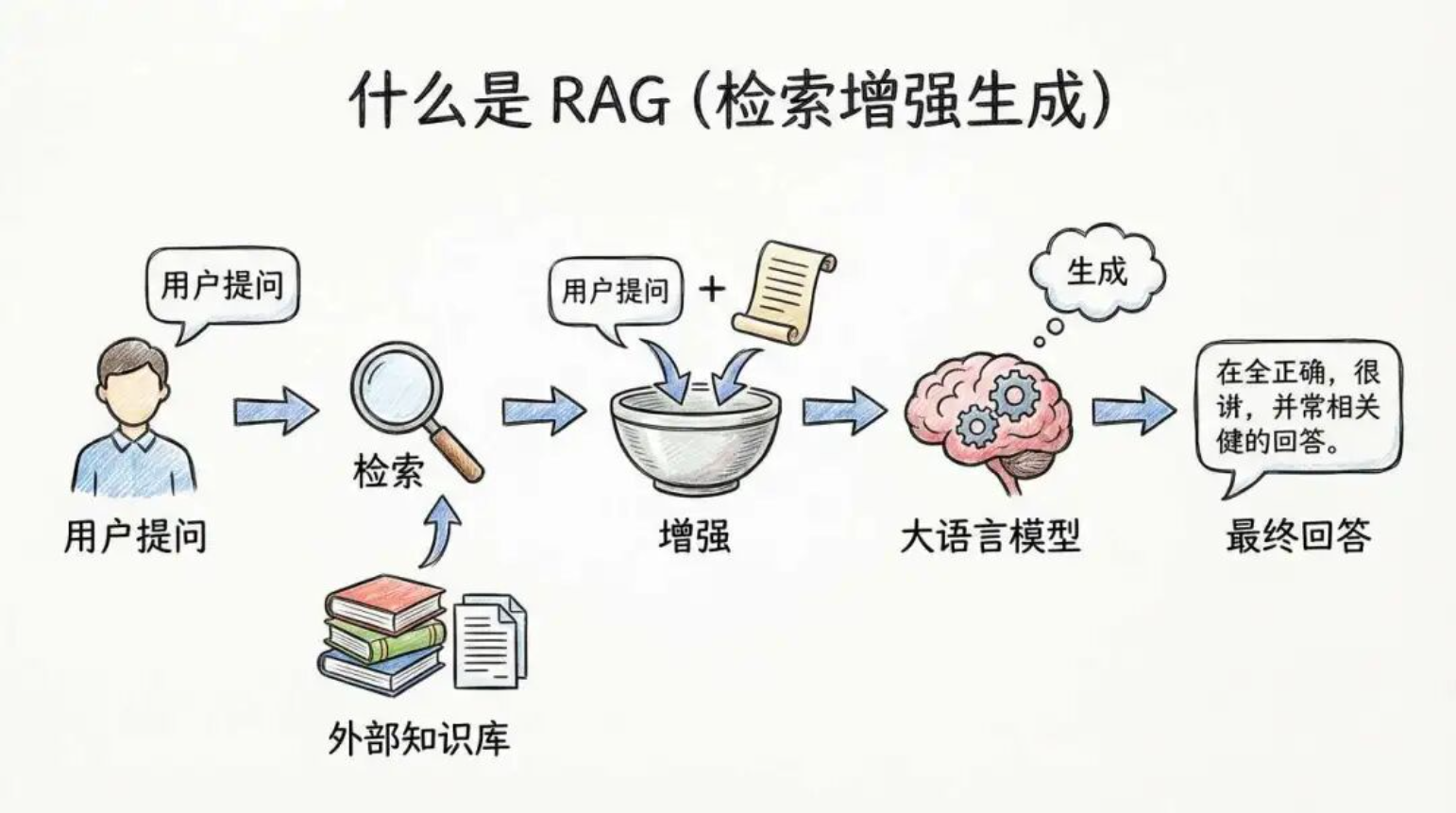
【导读】在知识库问答场景里,传统 RAG 常依赖“Chunk + Embedding + 向量召回”,效果可以做出来,但调优成本、分块策略与跨格式处理往往令人头疼。近期围绕 Agent Skills 的实践开始流行:它把检索能力封装成可调用的技能,通过渐进式加载与按需读取,让大模型参与“找什么、读多少、怎么读”的决策。用 Skills 做知识库检索,究竟能在准确性、效率与工程可控性上超越传统 RAG 吗?
一、从“向量召回”到“技能调用”:Agent Skills 的检索范式变化
Agent Skills 可以被理解为一种面向 Agent 的“能力标准化封装”。在实现形态上,Skills 通常就是一个文件夹,包含:
- SKILL.md:技能说明书(输入输出、使用方式、检索步骤、回答风格等)
- references:更细的参考文档(例如 PDF/Excel 解析策略、边界条件、异常处理)
- scripts:可执行脚本(把 PDF 转 txt/Markdown、解析表格、提取页面内容、连接外部系统等)
它的关键不在“多了文档”,而在渐进式加载(progressive disclosure / incremental loading)的上下文策略:
- Agent 启动时,只把所有 Skills 的“基本描述”放进上下文(轻量、可枚举)。
- 用户提出任务后,模型先根据描述做路由:判断该调用哪个 Skill。
- 确定 Skill 后再读取该 Skill 的 SKILL.md(把流程细节补进上下文)。
- 需要处理特定文件类型时,再按需读取 references,必要时执行 scripts。
这种机制带来的直接变化是:知识检索不再以“先建好索引、再向量相似度召回”为中心,而更像“先缩小范围、再打开少量文件、逐步扩展上下文”的人类检索路径。尤其在本地目录型知识库中,Agent 往往自带基础工具能力(如 ls、glob、grep 等),Skills 进一步把这些能力组织成可重复、可约束的检索工作流。
与此同时,业界对传统固定分块策略的反思也在加强:当 Agent 能动态扩展文件周边上下文时,过度纠结 Chunk 大小与重叠窗口的边际收益会下降——检索过程更重要的是“会不会找、能不能在正确的文档里读到足够的上下文”。
二、对比传统 RAG:痛点在哪里,Skills 的“创新点”是什么
把两类方案放在同一张桌面上,差异主要落在“召回机制”“多格式处理”“调优成本”和“可控性”。
1)传统 RAG 的典型路径与常见痛点
传统 RAG(以“Chunk + Embedding”为主流范式)大体流程是:
- 文档预处理 → 分块(Chunking)→ 计算 Embedding → 写入向量数据库
- 查询时:Query Embedding → TopK 召回 → 组装上下文 → LLM 生成回答
它的优势是工程化成熟、延迟可控、线上稳定;但在落地中经常遇到这些“硬伤”:
- Chunk 策略高度敏感:块太小上下文不够,块太大召回不准;需要不断调窗口、重叠、分隔符、层级切分等。
- 跨格式资料处理繁琐:PDF、Excel、图片型文档需要额外管线;解析质量直接影响召回与答案可信度。
- 问题越复杂越难靠一次召回解决:多跳问题(先找主体再找字段、先定位报告再找章节)往往需要额外的 query rewrite、multi-query、rerank、graph/RAG fusion 才能支撑。
- “命中片段”不等于“可回答证据”:向量相似度常召回语义相近但证据不完整的片段,导致“看似相关、无法落锤”。
2)Skills 的关键优势:让大模型参与“检索决策”
基于 Agent Skills 的检索更接近 Agentic RAG:大模型不仅负责“总结”,还参与“怎么找”。典型能力体现在:
- 目录级缩小范围:先判断问题落在哪个领域目录(Financial Report Data / E-commerce Data / Safety Knowledge / AI Knowledge 等),再在局部做检索,减少无意义扫描。
- 按需打开文件,而非暴力读库:先用关键字 glob/grep 定位可能相关的文件,再读取文件的关键部分。
- 多轮递进式读取上下文:先读少量行(offset/limit),不够再扩大范围;这相当于把“分块”从离线固定切分,变成在线动态扩展。
- 跨格式的“策略分流”:Markdown/文本直接定位段落;PDF 走脚本提取页/章节;Excel 通过脚本读取表格并仅关注相关行列,避免把整表搬进上下文。
换句话说,传统 RAG 更像“把知识切成统一形态再检索”,Skills 更像“按问题临场决定用什么工具、读取哪些证据”。
3)能否“更好”?取决于你把“效果”定义成什么
如果把效果拆成更细的维度,结论会更清晰:
- 答案正确率(尤其是需要证据链的问题):在“需要逐步定位文件→定位章节→补齐上下文”的任务上,Skills 往往更占优,因为它允许多轮缩放上下文并做策略调整。
- 首次响应延迟:若命中 PDF/Excel 且需要现转现解析,首次会更慢;而传统 RAG 由于提前把文本化、embedding 化,线上延迟更可控。
- 工程复杂度:RAG 在“建库、更新、分块、embedding、向量库运维、rerank”上复杂;Skills 则把复杂度转移到“脚本工具链、权限沙箱、错误恢复、调用稳定性”上。
- 成本结构:Skills 往往更吃 Token(多轮尝试、不断扩大上下文);RAG 把成本更多放在离线索引与在线少量上下文拼接上。
因此,“能不能比传统 RAG 更好”不是绝对判断,更像是场景选择:知识形态越杂、问题越复杂、越需要多轮定位证据,Skills 的上限越高;而在高并发、低延迟、强稳定性的标准问答上,传统 RAG 仍然更“工业化”。
三、实战形态:跨格式知识检索 Skill 如何跑起来
一个面向本地知识库的检索 Skill,通常会把能力拆成三段:定位领域 → 定位文件 → 定位内容,并用“渐进式检索”控制读取量。
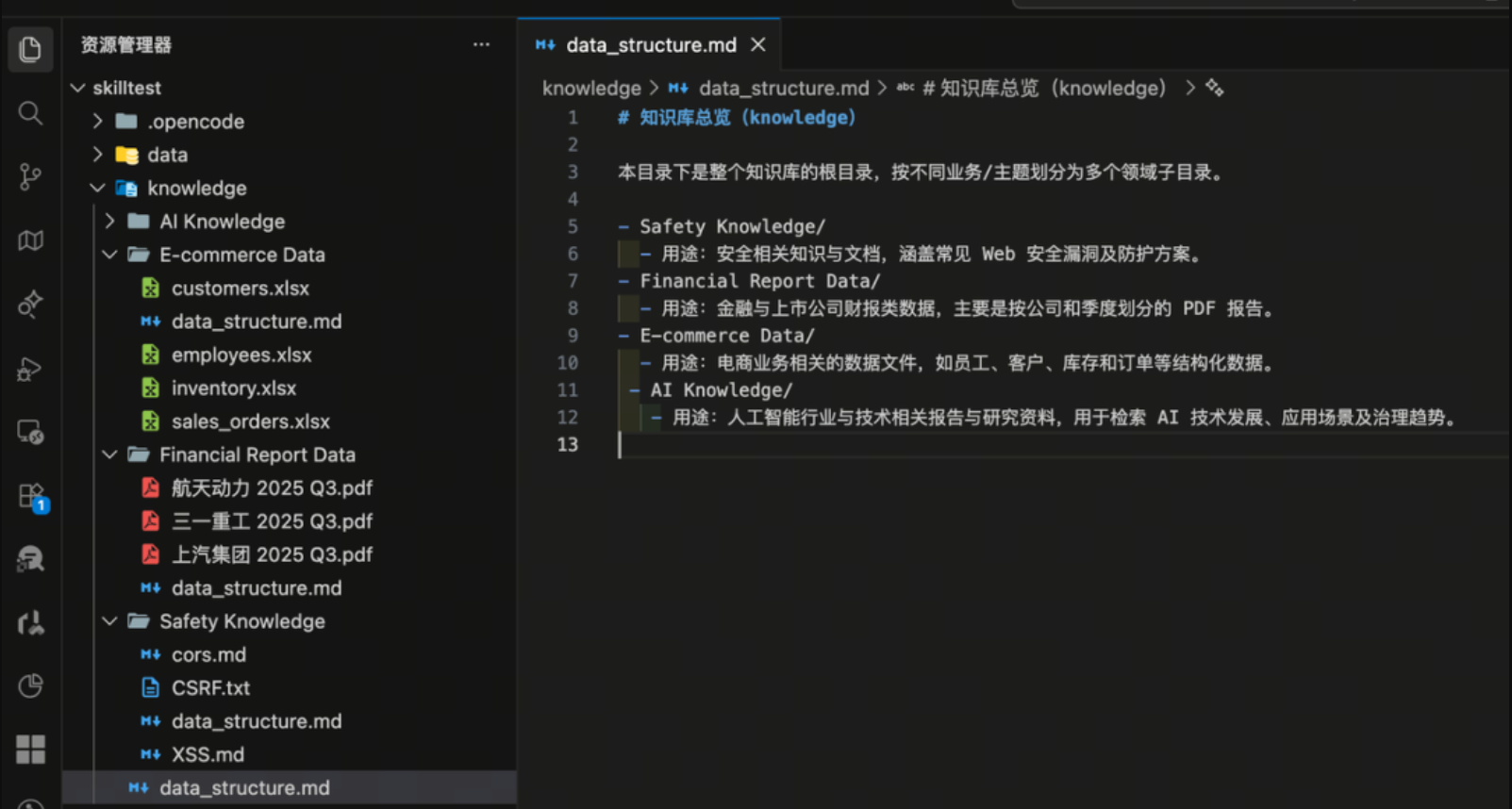
1)定位领域:先在目录结构里找“可能发生答案的地方”
做法往往是让 Skill 要求知识库按领域分文件夹,并在每个领域下放一个目录索引(如 data_structure.md),描述该目录每个文件的用途。这样 Agent 只在判断“该领域可能相关”时才读取索引,符合渐进式加载的思路。
2)定位文件:用 glob/grep 把候选文件缩小到少数
例如查询“航天动力前十股东总持股”,流程会倾向于:
- 先用 glob/文件名关键词锁定“航天动力”相关报告
- 再在候选文件附近用 grep 搜“股东信息”“前10名股东”等关键字
- 只打开最可能包含答案的文件,而不是把整个知识库灌进上下文
3)定位内容:按文件类型分流处理(Markdown/PDF/Excel)
- Markdown/文本:直接抓取命中段落并补上下文窗口,形成可回答证据。
- PDF:调用脚本先做解析(转 txt/Markdown 或按页抽取),再按页/章节检索;若上下文不足则扩大 offset/limit。
- Excel:用脚本读取表格,仅关注相关 sheet/列/行。例如问题“郑雪买了啥?”需要跨两张表:
- 在顾客表按姓名定位客户 ID
- 在订单表按客户 ID 关联到商品
这种“跨表推理”对传统 RAG 其实并不友好(向量召回更擅长语义片段,而非结构化 join),而脚本式读取能更直接得到确定性结果。
4)这一范式的现实短板:效率、稳定性与 Token
实践中暴露的缺陷也很集中:
- 首次检索效率问题:PDF/Excel 临时解析耗时明显,通常需要“预处理为纯文本/结构化中间层”来优化。
- Skill 调用稳定性:多轮对话中模型可能“忘记调用 Skill”或漏步骤,导致流程不一致;需要在 Agent 层做更强的路由约束与记忆策略。
- Token 消耗偏大:渐进式检索意味着“不断试、不断扩”,找到正确证据前可能消耗更多 Token,但换来的是更高的命中确定性。
结语:技术背后的管理思考
从传统 RAG 到 Agent Skills 驱动的 Agentic RAG,本质变化是:知识检索从“离线标准化切分+在线相似度召回”,转向“在线任务分解+工具协同+渐进式证据构建”。对企业管理而言,这会直接影响知识资产的组织方式与使用效率:一方面,知识库不再只是“存文件”,而需要更清晰的领域目录、索引规范与权限边界,让 Agent 能快速缩小范围;另一方面,员工能力结构也会变化——会写提示词不够,还要理解数据结构、脚本工具链与检索可追溯性,才能把“找得到”变成“答得准、可复核”。当组织开始规模化引入这类检索 Agent,HR 与管理者需要同步建立知识治理机制(命名规范、版本管理、敏感信息分级、使用审计)与岗位技能体系(数据素养、AI 工具使用规范、流程化问题拆解)。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把知识流动、协作流程与人才能力建设连接起来,才能让 AI 检索从“演示很惊艳”走向“生产可持续”。

