












































【导读】面向Agent的基础模型正在从“更聪明”转向“更可靠、更高吞吐、更低成本”的工程竞赛。近期,阶跃星辰将Step 3.5 Flash以开源方式全量上线,并强调其在Agent任务与数学推理上的综合表现可对标部分闭源模型,同时在长链条任务稳定性与推理速度上做了系统级优化。围绕稀疏MoE、MTP-3预测与SWA+Full Attention混合注意力等关键设计,该模型试图在256K上下文、部署多端化与可扩展的推理效率之间取得更好的平衡。
一、从“模型更强”到“Agent可用”:Step 3.5 Flash发布要点
围绕Agent落地的核心诉求,Step 3.5 Flash把产品化指标提到了与能力同等重要的位置:速度、效果与稳定性被同时强调,并给出相对明确的工程指向。
1)更快:最高350 TPS的推理吞吐
在单请求代码类任务场景中,Step 3.5 Flash标注的推理速度最高可达 350 TPS(tokens per second)。对于需要多轮规划、频繁调用与快速响应的Agent系统而言,TPS不只是“体验指标”,还直接影响到并发能力、单位任务成本以及工具调用链路的总体时延。
2)更强:Agent场景与数学任务对标闭源模型
发布信息将重点放在两类更“贴近生产”的能力维度:
- Agent场景:强调在任务分解、步骤规划、执行策略组织等方面的表现。
- 数学任务:强调推理与严谨性输出。
在这一叙事下,模型不仅要在通用对话上表现良好,更要能在带约束的复杂任务中提供可复用的推理链条与更高的成功率。
3)更稳:复杂、长链条任务可用性
Agent系统常见问题之一是“越做越偏”:多轮后上下文累积、错误传播与指令漂移会明显拉低成功率。Step 3.5 Flash将“胜任复杂、长链条任务”作为核心卖点,背后对应的是对长上下文机制与推理路径稳定性的工程化优化。
此外,发布信息提到开启 Parallel Thinking 后在部分基准上会有增强表现(与性能图对照)。在Agent系统中,这通常意味着通过并行化思考/候选路径生成来提升解题或检索策略的覆盖度,代价是一定的计算开销与调度复杂度提升。
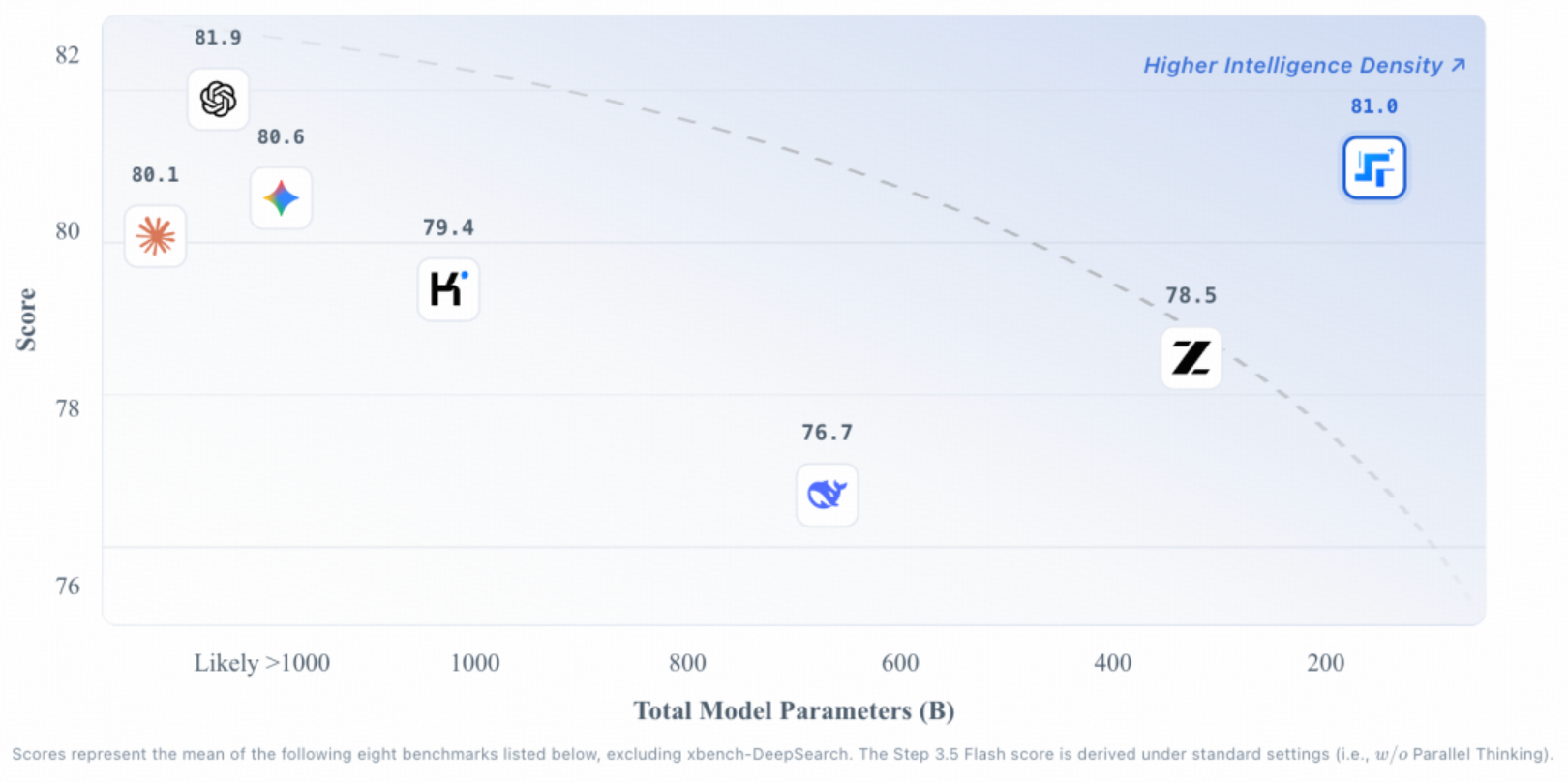
二、三项关键架构:稀疏MoE、MTP-3与混合注意力如何协同提效
Step 3.5 Flash的技术路线,整体指向一个目标:在不牺牲长上下文与任务复杂度承载能力的前提下,把推理成本压下去、把吞吐拉上来,并尽可能提升多轮任务的稳定性。
1)稀疏MoE:总参数1960亿,但每个token只激活约110亿
该模型采用 稀疏MoE(Mixture of Experts) 架构,并给出关键参数口径:
- 总计参数量:1960亿(196B)
- 每个 token 仅激活约 110亿参数(11B)
稀疏MoE的典型收益在于:模型容量可以做大(提升表达能力与泛化上限),但推理时并不需要全量计算。对Agent而言,这种“容量大但计算稀疏”的方式,有助于在保持能力的同时控制推理延迟与成本。不过,MoE也对路由策略、专家负载均衡、推理并行与部署栈成熟度提出更高要求,真正的工程效果往往取决于实现细节。
2)MTP-3:一次预测4个Token,提升生成效率
Step 3.5 Flash引入 MTP-3,其描述为“模型一次预测 4 个 Token,效率翻倍”。这类多token预测(multi-token prediction)思路通常用于降低自回归生成的串行依赖,让每一步前向计算产出更多token,从而提升吞吐。
对代码生成、结构化输出、长文本续写等场景,MTP类方法能显著改善单位时间产出;但与此同时,它也需要在训练与解码策略上处理好多token预测带来的误差累积与稳定性问题,否则可能出现“生成更快但更容易跑偏”的副作用。发布信息将“更稳”与MTP-3并列呈现,意味着其试图在速度与可靠性之间找到可用的折中点。
3)SWA + Full Attention:3:1滑动窗口与全局注意力混合,支持256K上下文
长上下文是Agent系统的“基础设施能力”:无论是长文档理解、长任务轨迹记忆,还是多工具调用日志与中间态保存,都依赖更长的context window。
Step 3.5 Flash采用 3:1 滑动窗口与全局注意力混合架构(SWA + Full Attention),并强调:
- 在长文本中只关注“重点”,以降低计算开销
- 高效处理 256K 上下文
混合注意力的思路通常是将局部高频信息用滑动窗口(SWA)处理,同时保留一定比例的全局注意力(Full Attention)用于跨段关联与全局一致性,这能把纯Full Attention在长上下文下的计算压力明显降下来。对需要“既要长记忆又要能推理”的Agent链路,这种机制尤其关键:它决定了模型在超长输入下的可用延迟、可用成本,以及跨段引用的可靠程度。
三、从开源到多端部署:可用性被放到与能力同等重要的位置
与不少只强调“权重发布”的开源模型不同,Step 3.5 Flash在发布信息中同时给出多种使用与部署路径,体现出对“开发者接入成本”的关注。
1)全渠道体验与接入
- OpenRouter 提供限免体验入口(标注为free)
- GitHub 提供快速部署相关内容
- HuggingFace / 魔搭社区提供模型权重
- 同时提供APP与网页端的免费使用入口
这类组合意味着:从“试用—验证—开发—部署”的路径被刻意打通,便于开发者快速把模型接入现有Agent框架、评估吞吐与成功率,再决定是否进入更深的本地化或私有化部署。
2)本地部署指向:工作站级硬件也能跑得动
发布信息明确提到对本地部署性能做了优化,并给出可运行的工作站平台示例:
- NVIDIA DGX Spark
- Apple M3/M4 Max
- AMD AI Max+ 395
这对企业端的意义在于:Agent系统不一定必须全量依赖云端推理。对于数据敏感、成本敏感或对延迟要求极高的场景,本地/私有化推理与端云协同会越来越常见,而模型是否具备“工程上可部署”的能力,往往比理论指标更能决定能否落地。
3)示例能力:数学、编程与端云协同任务拆解
发布内容展示了多个侧重点不同的例子:
- 数学题快速求解(强调复杂计算与正确性)
- “智能体编程”:根据文字prompt生成可视化平台方案,涉及 WebGL 2.0、WebSocket、低延迟数据管道、地理空间可视化等关键词(强调专业场景的系统构建能力)
- “端云结合”:云端作为“云端大脑”负责规划拆解,本地端(如Step-GUI)执行抓取与操作,最后云端汇总(强调任务编排与执行成功率)
这些示例共同指向一个趋势:Agent能力的竞争不只在模型本身,也在于“规划—执行—校验—汇总”的闭环是否稳定,以及是否能在端侧工具、企业系统与外部应用之间顺畅编排。
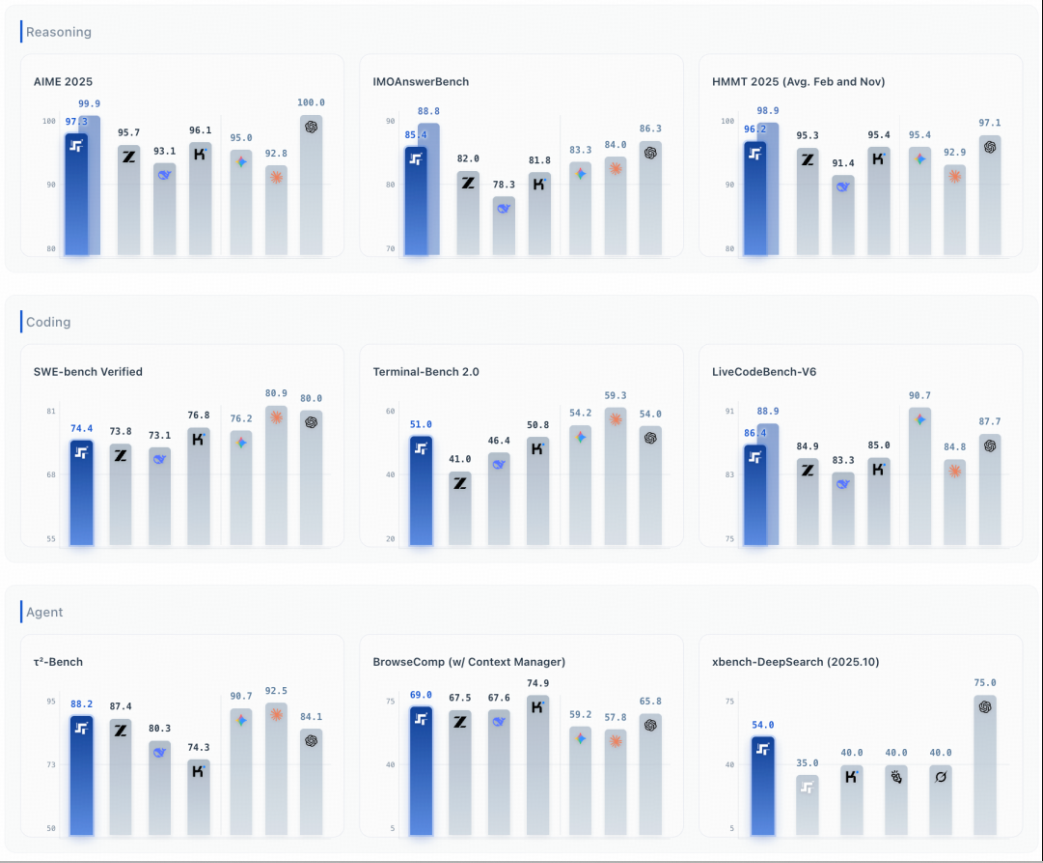
结语:技术背后的管理思考
Step 3.5 Flash这类“为Agent而生”的开源模型,把行业关注点从单纯比拼参数与榜单,推向更务实的工程指标:TPS、长上下文(256K)、长链条稳定性、端云协同与本地部署可行性。对企业管理而言,这意味着智能体不再只是“演示型助手”,而更接近可进入流程的“数字员工”:它需要在可控成本下持续响应,能遵循规则执行任务,并在复杂业务中保持一致性与可追溯的结果输出。随之而来的,是组织对人才能力结构的再定义——业务人员需要更懂任务编排与提示工程,技术团队需要更懂模型部署与推理优化,管理者则要把AI纳入流程治理与绩效衡量体系,明确数据边界、权限控制与责任归属。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把模型能力转化为可复用的流程资产,才能真正提升组织效能与人效水平。


