【导读】同一夜里,Anthropic与OpenAI几乎“同台发布”:Claude Opus 4.6与GPT-5.3 Codex相继上线。两者不再只比通用问答,而是把火力集中在Coding、终端任务、电脑操作、在线信息检索与长上下文等“可交付”的能力上。更关键的是,Agent化的产品形态正在被快速补齐:从多代理协作到可中途介入的自主迭代,AI开始更像一支可调度的数字化劳动力。
一、同日更新的信号:评测指标正在向“能干活”迁移
过去一段时间,LLM的竞争往往围绕“更大参数、更强知识、更会聊天”。而这次两家更新释放的共同信号是:行业评估口径正从“语言能力”进一步转向“真实任务完成率”。
从公开信息看,这次被高频提及的评测更贴近真实工作流,包括但不限于:
- Terminal-Bench 2.0:在终端环境执行复杂真实任务(每题独立Docker容器),更像“让模型在命令行里把事做完”。
- OSWorld / OSWorld-Verified:评估AI agent操作真实计算机的能力,涵盖点击、切换应用、处理网页不稳定性等。
- BrowseComp:关注Agent在网上搜索信息并形成有效结论的能力。
- GDPval / GDPval-AA:把任务拉到“知识工作交付物”层面(文档、表格、演示、图表),试图衡量对真实岗位产出的替代或增益。
- SWE-bench Verified / SWE-bench Pro Public:围绕真实GitHub issue生成补丁并通过单测,强调“修得了Bug”。
- ARC AGI 2:强调“流体智力(Fluid Intelligence)”的模式识别与推理题,常被视为跨任务迁移能力的指标之一。
这些基准共同构成一个趋势:模型不仅要“说得对”,还要“做得到、做得完、做得稳定”。
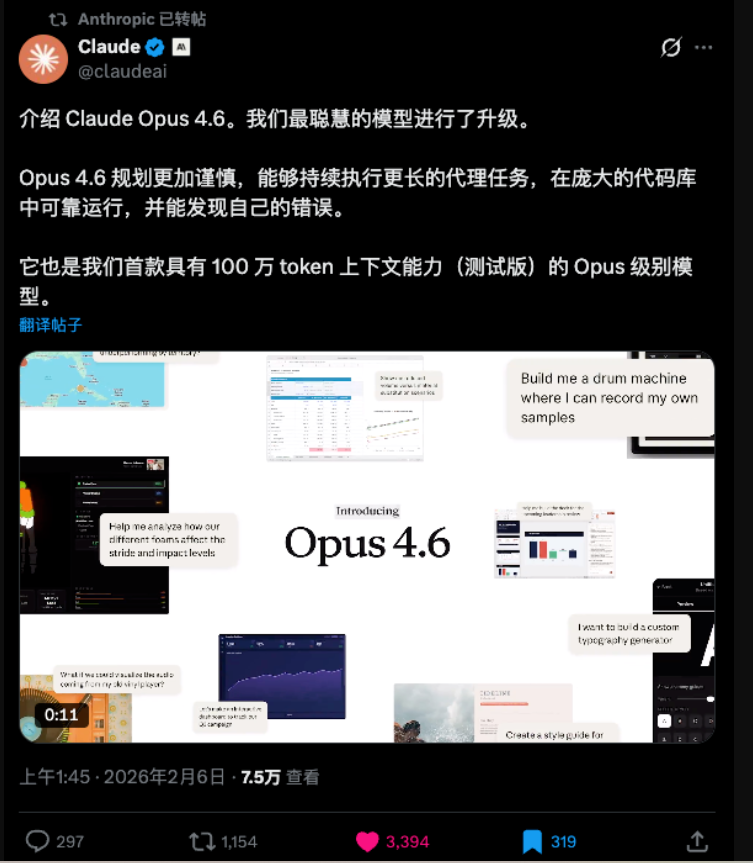
二、Claude Opus 4.6:长上下文 + 电脑操作 + 多代理协作的组合拳
从披露的结果看,Claude Opus 4.6在多个维度刷新了自家能力边界,尤其集中在“Agent需要的基础设施”上。
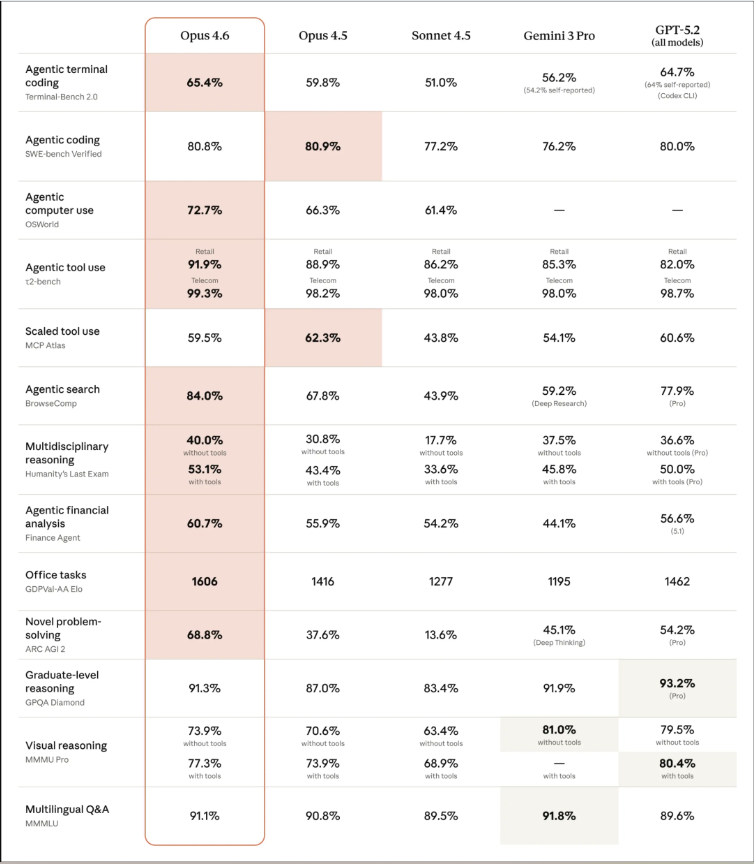
1)关键评测表现:终端、电脑、搜索与知识工作任务
- Terminal-Bench 2.0:65.4%(被描述为当时最高之一)。该基准强调终端任务闭环,能一定程度反映模型“把工具用起来”的能力。
- OSWorld:72.7%(相较前代被认为提升明显)。该指标对应“操作电脑”的可用性:鼠标点击、窗口切换、跨应用流程执行等。
- BrowseComp:84.0%。在线检索能力的提升意味着Agent在“外部信息补全”上的成功率更高。
- GDPval-AA Elo:1606。该体系用Elo量化在真实知识工作任务中的相对表现,分值提升通常被解读为“更接近可交付”。
此外,ARC AGI 2:68.8%也被认为是亮点,常与“在新情境下的推理与模式发现”相关联。
需要注意的是,不同机构、不同配置(是否接入浏览器/终端/agent框架)会影响可比性。跑分能提供方向,但并不直接等价于某个企业场景里的ROI。
2)产品侧更新:1M token上下文与“context rot”对抗
本次讨论度极高的升级是:1M token上下文窗口。长上下文对Coding、审计、研究类任务的影响非常直接——模型可以一次性承载更完整的代码库片段、长文档、会议纪要、规范与历史变更。
但“支持长上下文”与“能用好长上下文”并不是一回事。业界常把性能随对话变长而衰减称为 context rot。为回应这一点,Opus 4.6被提到在 MRCR v2 的“needle-in-a-haystack”测试中表现突出:在100万token、8根针的设置下拿到76%(同文中对比某型号为18.5%)。这类测试意在验证模型在超长输入中定位关键信息的能力。
同时,输出上限提升到128K(由64K翻倍)也更适配“长交付物”场景:长代码生成、长报告、长规格说明书、批量用例与测试结果汇总等。
3)Context Compaction:把长对话“压缩成可继续工作的状态”
当Agent执行长任务时,历史对话会快速吞噬上下文预算。Context Compaction的价值在于:将旧对话自动压缩为摘要,让任务能继续推进而不必人工裁剪上下文。对于需要多轮探索、长链路执行的工作(代码重构、合规审查、复杂文档编辑),它更像一种“会话记忆管理机制”。
4)Adaptive Thinking与Effort:把推理成本从“开关”变成“旋钮”
在强调成本与速度的商业环境里,推理能力也需要调度。Opus 4.6的两个控制项——
- Adaptive Thinking:让模型自行判断是否进入更深推理;
- Effort(low/medium/high/max):允许用户手动设置推理强度;
本质上是在把“质量-速度-成本”三角变成可配置的策略,而不是一刀切。
5)Agent Teams:从“子代理”走向“可协作的团队结构”
在Claude Code相关能力中,Agent Teams被视为重要变化:
- 过去的 subagents(子代理) 更像单会话内的分工,只向主代理汇报;
- Agent Teams强调多个成员各自运行在独立上下文窗口中,并允许成员间直接通信、互相质疑与协调。
这类结构更接近真实软件团队的工作方式:前端、后端、数据库、测试同时推进,并在接口变更时互相同步,最终汇总交付。
6)Office场景延伸:Claude in Excel与Claude in PowerPoint
在插件侧,能力被进一步拉到“企业日常工具链”:
- Claude in Excel:支持数据透视表编辑、图表修改、条件格式设置、排序筛选、数据验证与金融级格式等,并包含长对话自动压缩、拖放多文件等可用性改进。
- Claude in PowerPoint:集成到侧边栏,能够读取既有布局、字体与母版,并按模板构建与定向编辑幻灯片。
这类更新的意义不在“能不能生成PPT”,而在于它开始嵌入组织里最常见的交付载体:表格与演示文稿。
7)价格与超长上下文定价(按素材信息保留)
API价格被描述为保持:$5/$25 每百万token(输入/输出);当上下文超过20万token时,额外定价为 $10/$37.50 每百万token(输入/输出)。
三、GPT-5.3 Codex:在Coding基准上更激进,并把“自举式开发”摆到台前
与Claude更强调“长上下文 + 办公插件 + 多代理组织”不同,GPT-5.3 Codex的叙事更集中在两点:更强的编程闭环能力,以及模型参与自身研发流程的“自举”信号。
1)一个关键表述:模型参与了自己的开发过程
公开信息中最引人注目的一句是:
“GPT-5.3 Codex是我们第一个在创造自己的过程中发挥重要作用的模型。”
对应的解释是:在开发GPT-5.3 Codex过程中,团队使用早期版本模型来debug训练过程、管理部署、诊断测试结果和评估。
这意味着Codex不只是被用来“写业务代码”,也被用来加速“模型工程本身”的研发链路——训练脚本、部署流水线、测试框架同样是代码与工程系统。
如果这种“自举式工具链”持续增强,模型迭代速度可能会出现新的加速度:研发团队把更多工程性工作交给模型,进而释放人力去做更高阶的研究与产品定义。
2)可对齐对比点:Terminal-Bench 2.0的正面交锋
在两家披露中,最容易对齐的基准之一是 Terminal-Bench 2.0:
- Claude Opus 4.6:65.4%
- GPT-5.3 Codex:77.3%
差距约 11.9 个百分点。
在这个“终端闭环任务”基准上,GPT-5.3 Codex体现出更强的优势,也符合Codex系列面向软件工程任务的定位。
3)OSWorld分数背后的“口径差”:OSWorld vs OSWorld-Verified
在“操作电脑”能力上,素材强调了可比性问题:
- Claude Opus 4.6提供的是 OSWorld(72.7%)
- GPT-5.3 Codex提供的是 OSWorld-Verified(64.7%)
其中 OSWorld-Verified被描述为一次重构版本,修复了原版中300+问题(失效URL、反爬CAPTCHA、不稳定HTML结构、含糊指令、评测脚本过严/过松等),因此一般被认为更严格、更难。
这也提示企业在选型时要警惕“同名基准不同版本”的误读:分数高低之外,更要看评测设置与工具接入条件。
4)GDPval两套体系:wins-or-ties vs Elo,难以直接换算
素材给出的口径差异很典型:
- GPT-5.3 Codex:GDPval wins or ties:70.9%(以人类专家为固定分母,由职业人类评审盲评“是否与人类一样好或更好”)
- Claude Opus 4.6:GDPval-AA Elo:1606(基于Artificial Analysis体系与agent框架,Elo由比较与拟合得到)
这两者并非同一量纲,直接对比容易得出错误结论。对企业来说,更稳妥的方式是:围绕自身任务集做小规模POC,用一致工具链(同浏览器/同终端/同权限/同数据)评估交付质量与成本。
5)SWE-bench:Verified与Pro Public的“难度结构”差异
在SWE-bench上,双方披露的是不同子集:
- Claude Opus 4.6:SWE-bench Verified 80.8%(500题、人工验证、仅Python)
- GPT-5.3 Codex:SWE-bench Pro Public 56.8%(731题、多语言:Python/Go/JavaScript/TypeScript等,横跨41个仓库;参考解平均107.4行、4.1个文件;并纳入copyleft与专有代码库以降低数据污染风险)
因此,80.8%与56.8%不应被解读为“简单的强弱对比”,而更像“各自对不同难度结构与语言覆盖的表现”。
6)Codex产品形态:长周期自主迭代 + 人类可中途介入
素材提到OpenAI展示了两个由GPT-5.3 Codex生成的可玩游戏(赛车、潜水),并强调其在数天内自主迭代了数百万token,通过类似 develop web game 的Skills与通用跟进提示不断改进。
更实用的一点是:模型工作时可随时互动介入、调整方向,不必先停止任务再重启流程。这类“可打断、可纠偏”的交互机制,直接影响Agent在真实研发中的可控性。
此外,还提到性能侧体感提升:同任务所需token少于5.2-Codex的一半、单token速度提升25%以上(以公开社交平台表述为依据),这意味着在相同预算下可覆盖更长的迭代链路。
结语:技术背后的管理思考
从Claude Opus 4.6与GPT-5.3 Codex的同日更新可以看到,AI正在从“回答问题的助手”向“可调度的执行单元”演进:更长的上下文窗口、更强的Terminal-Bench 2.0表现、更严格口径下的OSWorld-Verified能力,以及Agent Teams、多轮自主迭代与可中途介入的交互方式,本质上都在提升“把任务做完并交付”的确定性。对企业管理者与HR而言,这会带来三点变化:第一,知识工作将更像生产流程,需要把工作拆分为可评估的任务包(输入、工具权限、验收标准、风险边界);第二,组织能力建设会从“会不会用模型”转向“会不会搭工作流”,包括权限治理、数据分级、提示与评测体系;第三,人才画像也会随之变化——懂业务的人需要更熟悉自动化与Agent协作,懂技术的人则要更理解合规与组织流程。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把AI能力嵌入岗位与流程,通过数据与系统化治理提升组织效能,而不是停留在零散的个人效率工具层面。