【导读】随着ChatGPT等产品把“记忆”带入真实用户场景,AI Agents的记忆系统不再只是RAG外挂,而逐渐演变为贯穿存储、推理与自我改进的基础设施。一项来自斯坦福、复旦、牛津等团队的研究提出“形式(Forms)-功能(Functions)-动态(Dynamics)”三维框架,为长期混乱的记忆概念给出统一坐标系。与此同时,OpenAI、Google、亚马逊及Mem0、Letta、Zep等开源/产品化方案的路径差异,也让“怎么选、怎么做、怎么控风险”成为工程核心议题。
一、从“短期/长期”到三维坐标:AI记忆概念开始收敛
过去谈智能体记忆,行业常直接套用心理学里的“短期记忆/长期记忆”。这套说法直观,但在工程上边界极不稳定:一小时的缓存算短期还是长期?向量数据库里长期沉淀的用户画像又该归哪类?当不同团队把聊天历史、用户偏好、工具调用轨迹、知识图谱、策略经验都称作“memory”时,技术沟通与选型很容易变成各说各话。
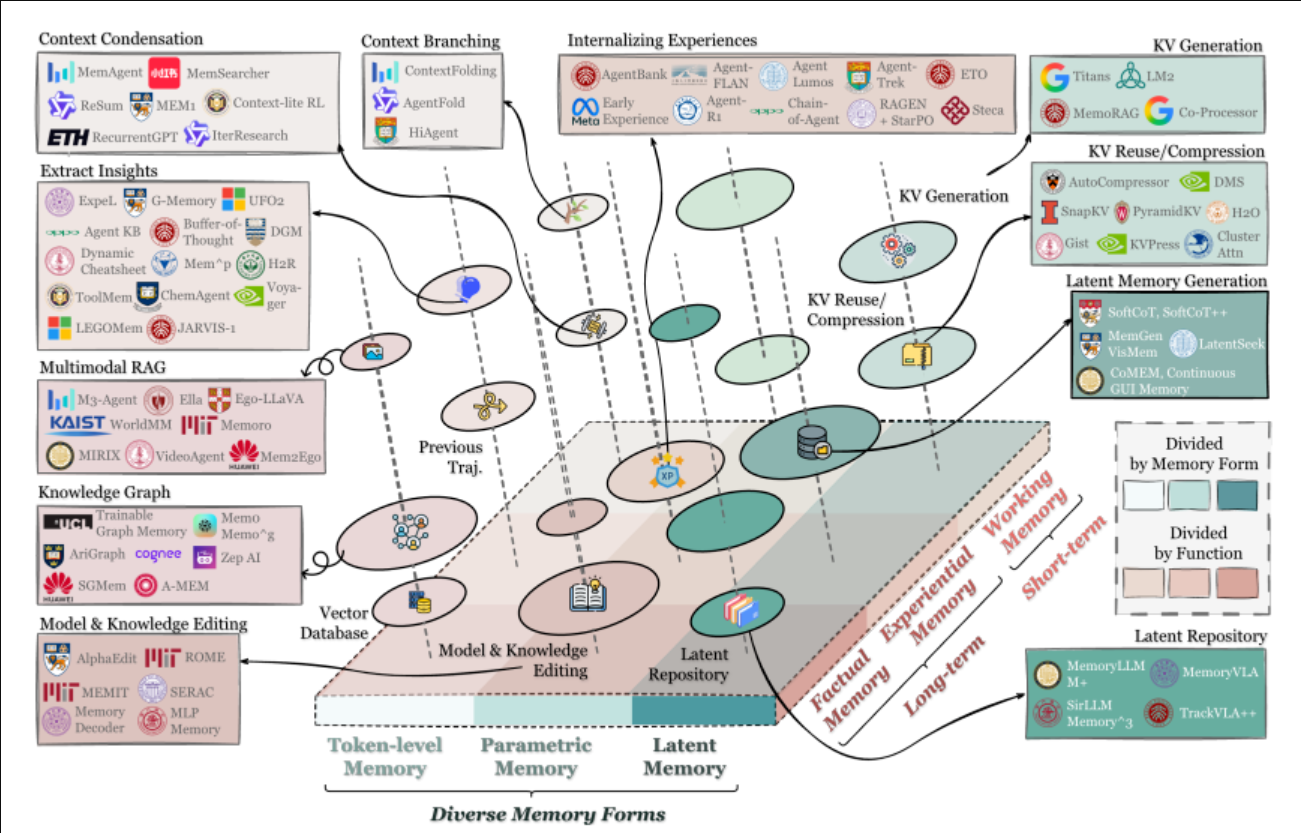
新的三维框架试图绕开“以时间长度划分”的歧义,改用三个彼此正交的维度来刻画一个记忆系统的全貌:
- 形式(Forms):记忆“以什么载体存在”,是Token级、参数级,还是潜空间(latent space)。
- 功能(Functions):记忆“在认知与决策中扮演什么角色”,是事实记忆、经验记忆,还是工作记忆。
- 动态(Dynamics):记忆“如何形成、演化与被检索”,以及如何遗忘、如何更新、如何防止污染。
这套框架的意义在于:它把“记忆工程”从一个泛化词汇,变成可拆解的系统设计问题——你可以分别回答“存在哪里、为何要存、如何生命周期管理”,进而对齐架构与成本、性能、可解释性、安全合规之间的权衡。

二、形式维度(Forms):Token级、参数级、潜空间记忆的工程取舍
1)Token级记忆:透明、可编辑,但对检索与治理要求高
Token级记忆可以理解为“可读可改、可寻址的外部化存储”:聊天历史、用户画像、结构化表、知识图谱、文档片段等,都以显式Token形式存在于外部系统(数据库、对象存储、向量数据库、图数据库)中。
它的核心优势是透明与可控:
- 可审计:能追溯“模型为什么知道/说了这个”。
- 可更新:事实变更时可直接改数据,不必重训模型。
- 可治理:更容易做权限、脱敏、保留策略与删除请求响应。
但Token级记忆的工程痛点也很集中:检索质量决定上限,规模一大还会带来索引、延迟、召回与成本压力。因此,行业开始从“只做向量相似度”扩展到更强的组织方式:
- Letta(原MemGPT)将记忆管理做成类似操作系统的“虚拟内存分页”:区分必须常驻上下文的Core Memory与按需调用的Recall Storage,用“分页/置换”思路缓解上下文窗口限制。
- Zep 的 Graphiti以知识图谱组织记忆,通过实体关系显式建模来提升精准检索与多跳查询能力,试图对抗“向量相似度不够用”的问题。
- 一些工程实践将聊天历史、用户画像、知识图谱等拆分成多种拓扑结构(流式、层次、图结构),本质上都是Token级记忆在不同数据组织形态下的实现选择。
2)参数级记忆:知识“学进权重”,性能强但更新慢且有遗忘风险
参数级记忆指把信息通过训练、微调或持续学习直接编码进模型权重。优点是推理时不必频繁访问外部记忆库,响应更“本能化”,对延迟敏感的场景很有吸引力。
典型路径包括:
- Google DeepMind 的 ReMem:用强化学习优化记忆保留策略,将历史经验蒸馏进模型权重,实现跨任务迁移能力的提升。
- 企业场景中常见“参数级 + Token级”的混合架构:把相对稳定、可泛化的能力(风格、流程、写作规范、领域表述)通过微调固化;把高频变化的事实与资料仍放在外部知识库里,减少“训一次就过时”的问题。
- 对“外部参数记忆”的工程实现,常会涉及 LoRA 适配器等方式,以较低代价为同一基座模型挂载不同专项能力。
代价同样明确:
- 灾难性遗忘:新知识可能覆盖旧知识,需要增量学习、经验回放等机制对冲。
- 可解释性下降:知识“在哪儿”变得难以审计。
- 更新慢:对频繁变化的企业事实数据并不友好。
3)潜空间记忆:高密度、低延迟,指向多模态与端侧
潜空间记忆把信息编码到模型隐藏状态、KV缓存或统一的潜在表示空间里,通常人类不可读,但机器处理效率高。它更贴近多模态系统的工作方式,也更适配边缘侧对低延迟与高吞吐的需求。
在多模态方向,MIRIX(Modular Multimodal Architecture)这类架构将文本、图像、视频、音频等编码到统一潜在空间,覆盖生成、重用、转换等子类型:
- 生成型:从潜空间重建多模态内容;
- 重用型:缓存中间表示以加速推理;
- 转换型:跨模态融合与压缩。
一些“显性Token + 隐性潜空间”的混合方案也开始出现:例如 A-MEM用 Zettelkasten 思路构建笔记网络,笔记本身是Token可读的,但笔记间关联可通过神经网络学习并沉淀为潜空间权重,从而形成“显性知识 + 隐性关联”的混合记忆。
三、功能维度(Functions):事实、经验、工作记忆,决定系统该“为什么存”
从工程视角看,“存什么”往往不如“为什么存”更关键。功能维度把记忆的目的拆成三类:
- 事实记忆(Factual Memory):维持一致性与长期知识——“智能体知道什么”。典型是产品信息、用户资料、制度条款、知识库条目。
- 经验记忆(Experiential Memory):用于自我改进与策略积累——“智能体学会什么”。典型是执行轨迹、成功/失败案例、策略总结、技能单元沉淀。
- 工作记忆(Working Memory):服务当前任务的临时状态——“智能体正在想什么”。典型是会话上下文、当前计划、分步推理中间产物、工具调用状态。
这种划分的价值在于,它能直接指导架构:
- 事实记忆通常需要强治理(权限、审计、版本),适合Token级外部存储 + RAG/混合检索;
- 经验记忆既可以外部化(便于回放与分析),也可以部分参数内化(形成“能力”);
- 工作记忆强调实时性和上下文编排,往往与上下文工程、会话管理、工具编排强绑定。
业界的代表性实践之一是亚马逊在 Agentic AI 基础设施中体现的功能导向:用 Amazon Bedrock Knowledge Base承载事实记忆,用执行轨迹数据库承载经验记忆,用会话上下文承载工作记忆,并形成“检索-增强-处理-提取-更新”的闭环,把记忆作为可运营的系统来管理,而非一次性的RAG调用。
四、动态维度(Dynamics):记忆的形成、演化、检索与遗忘,正在替代“只做检索”
真正把记忆系统从“外接知识库”升级为“类操作系统”的,是动态维度:它把记忆当成持续生长、持续代谢的对象,强调形成与演化,甚至强调“遗忘”的必要性。
1)形成(Formation):从对话与行为中把信息“变成可用记忆”
常见路径可归纳为五类:
- 语义摘要:每轮对话后做摘要,降低上下文噪声,避免窗口被无效信息占满;
- 知识蒸馏:从大量轨迹中提炼规律;
- 结构化构建:把信息显式组织成表、图、层次结构;
- 潜空间表征:压缩为隐藏表示以提速;
- 参数内化:通过训练把规律固化进权重。
这里的关键趋势是:形成阶段越来越自动化,不再靠人工标注或手工规则“挑选哪些值得记”。
2)演化(Evolution):整合、更新与遗忘,避免记忆库失控
“会记不会忘”的系统很快会变成噪声堆积场。遗忘机制因此成为分水岭:
- 一类思路是基于访问频率、时间衰减、重要性等信号做分层存储与降级淘汰。
- MemoryScope采用四层仿生架构,并通过“巩固”机制让高频使用的信息上升到长期记忆,低价值信息逐步降级直至遗忘。
- Letta也有相对直接的归档策略,但更精细的方向是把时间、频率、重要性做联合决策,避免“重要但低频”的信息被误删。
3)检索(Retrieval):不再等同于向量搜索
动态维度对检索的最大改变,是强调“检索策略”与“查询构建(query construction)”。在多轮对话或复杂任务中,直接用用户原始问题去向量库检索往往不稳定,越来越多系统会先让LLM生成结构化的检索意图(关键词、时间范围、实体、约束条件),再进行检索。
在检索方法上,也从单一向量相似度走向组合:
- Mem0代表轻量的向量检索,适合快速落地;
- Zep/Graphiti用知识图谱提升关系推理与多跳查询;
- Cognee把向量、图谱、全文检索组合成混合检索,更适合“复杂条件 + 推理”的企业检索需求。
整体趋势可以概括为:记忆系统开始从“检索式记忆”迈向“生成式记忆”——不仅把相关片段找出来,还要能在形成与演化阶段自动抽象、整合与重写记忆,使其更贴近任务需要。
结语:技术背后的管理思考
当AI记忆系统从“RAG外挂”变成贯穿Forms/Functions/Dynamics的基础设施,它对企业的影响就不止是“回答更准”,而是更深层的组织能力重构:第一,知识管理会从静态文档库升级为“可演化的组织记忆”,事实、经验、流程会被持续沉淀,并通过检索-更新闭环保持新鲜度;第二,工作方式会更强调“可追溯的协作链路”,尤其是Token级记忆带来的透明、可审计特性,会成为合规行业引入AI Agents的关键前置条件;第三,人才与能力模型也会变化——企业需要既懂上下文工程、RAG/混合检索、知识图谱,又理解数据治理与权限边界的复合型团队,才能把“会记忆的智能体”变成稳定的生产力。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把知识沉淀、流程协同、权限合规与效率提升打通,才能让AI从工具走向可规模化的组织能力。