












































【导读】围绕大模型在垂直场景“幻觉”、知识图谱更新成本高与可解释性落差等痛点,工信部标准院发布的案例集汇总16个行业落地实践,覆盖政务、金融、能源、制造、医疗等方向。案例集中,“知识图谱增强大模型(KG→LLM)”与“大模型增强知识图谱(LLM→KG)”形成双向增强主线,并以OneKE、KAG、RAG等技术要素串起可复制的工程路径,为企业构建更可靠的智能问答、检索与决策系统提供了对照样本。
一、从“能生成”到“可用可控”:案例集关注的核心矛盾
企业推进LLM应用时,最常见的矛盾并不在“模型会不会说”,而在“说的是否可信、是否可追溯、是否能稳定服务业务流程”。案例集所指向的关键问题主要集中在三类:
- 大模型“幻觉”与领域知识缺口:在金融、政务、医疗等强合规行业,LLM生成的错误事实、错误引用或逻辑跳跃,会直接带来合规与业务风险。
- 知识图谱的构建与维护瓶颈:传统KG依赖人工/规则驱动的信息抽取与建模,更新周期长,难覆盖快速变化的制度、产品、设备与工艺知识。
- 可解释性与可审计需求:仅靠生成式回答很难满足“依据是什么、证据在哪里、规则如何命中”的审计要求,而结构化知识与溯源机制恰恰是业务侧的刚需。
在此背景下,案例集将“融合”定义为一种工程范式:不是简单把LLM接到知识库上,而是在知识表示、知识建模、知识获取、知识融合与模型训练、微调、推理、评估等环节建立闭环,让“结构化知识能力”和“生成式语言能力”形成协同。
二、两条主线:LLM→KG 与 KG→LLM 的“双向增强”框架
案例集将融合路径归纳为两种核心模式,并强调它们通常需要组合使用。
1)大模型增强知识图谱(LLM→KG):用LLM提升KG构建与演化效率
这一模式把LLM当作“知识工程工具”,重点解决KG“难建、难更、难补全”的问题,落在四类典型活动上:
- 模型增强知识表示:用LLM改进实体、关系、事件的表示与对齐,提升跨源数据一致性。
- 模型增强知识建模:辅助Schema设计与概念体系梳理,降低建模门槛。
- 模型增强知识获取:对文档、图片、视频等多模态数据做实体抽取、关系抽取、事件抽取,提高抽取覆盖与效率。
- 模型增强知识融合:在多来源数据冲突与重复时,用LLM做对齐、消歧与合并,提升图谱质量。
案例集中提到的OneKE(中英双语大模型知识抽取框架),即以KnowledgeExtraction为主战场:在多个全监督及零样本实体/关系/事件抽取任务上,效果超过GPT 3.5、GTP 4、Baichuan2-13B-Chat、InstructUIE、YAYI-UIE等模型,为“从文档到结构化”的链路提供了可复用的技术抓手。
2)知识图谱增强大模型(KG→LLM):用KG约束推理、补齐知识、提升可解释性
这一模式把KG当作“可靠知识底座”,围绕LLM的预训练、对齐微调、评估、推理做增强,主要价值体现在:
- 知识准确性:用结构化事实与规则降低幻觉概率;
- 逻辑性:借助图结构关系约束推理路径;
- 可解释性:回答可溯源到节点、边、证据片段或命中规则;
- 可运营性:业务知识更新可通过图谱增量完成,而非频繁重训大模型。
案例集中还强调了一个更贴近落地的层面:知识图谱与大模型输出协同。它把“检索—推理—生成—溯源”作为一条可编排链路,涉及:
- 语义识别/分解
- 混合知识检索(向量与图查询的检索方法)
- 协同推理
- 结果生成与溯源
- 知识统一表征与动态编排与调度
- 检验与评估
在不少企业实践里,这类协同往往与RAG、以及更进一步的GraphRAG思路相互交织:既要“召回相关片段”,也要“召回关系与约束”。
三、16个行业案例的共性做法:从数据工程到推理链路的工程化落地
案例集覆盖20余家单位的实战数据与20项应用实践,行业跨度大,但工程路径呈现出相对一致的“拼装方式”。
1)数据与知识构建:先解决“可用数据”再谈“智能”
多数案例在前置环节都强调数据处理的基本功:数据清洗、去重、标准化,随后进入知识构建的三件套:实体抽取、关系抽取、事件抽取。
样本源不仅是文档,也包含图片、视频等多模态输入,目的是保证知识覆盖的多样性与代表性。
2)模型训练与微调:强调指令数据与对齐
在模型侧,案例集中给出较明确的工程做法:使用“大规模高质量抽取指令微调数据”,并采用LLaMA进行全参数微调。这意味着不少场景并非只做“外挂检索”,而是把领域抽取与对齐能力直接写入模型参数,以获得更稳定的结构化理解能力。
此外,案例集提到若干与融合紧密相关的技术点,包括:
- 基于Schema的轮询指令构造技术:把抽取目标和Schema约束显式写入指令,减少“抽取漏项/跑偏”;
- 图结构数据理解能力:让模型能“读懂”图结构输入或图查询结果;
- 向量与图查询的检索方法:用向量召回解决语义相关,用图查询补齐关系、规则与路径。
3)效果指标:更关注“业务可交付”的度量
案例集并不只用通用NLP指标,很多案例直接用业务指标描述效果提升,例如准确率、覆盖率、效率提升、自动化比例、检索时间缩短等,这也反映出“KG&LLM融合”常以业务交付为牵引,而非纯学术benchmark。
四、代表性成效速览:准确率、覆盖率与效率的可量化提升
从案例集披露的结果看,融合框架在“准确性—效率—可解释”三角上给出了较多可量化的收益样本:
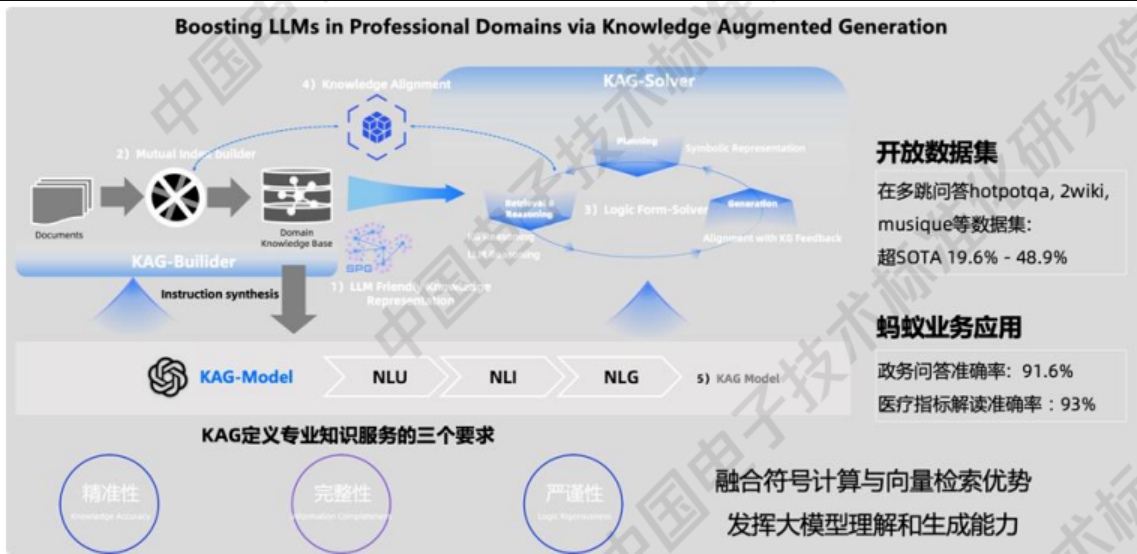
- KAG(通用·面向专业领域的知识增强生成框架):政务问答准确率从66%提升至91%;医疗指标解读准确率超过90%。
- 金融行业声誉风险智能分析:从海量数据提取关键观点,观点提取准确率提升至90%。
- 油气知识平台(知识图谱与行业大模型双轮驱动):覆盖油气主要业务链的知识库,包含10万个行业专业词汇、1254万个分类特征词汇、2657个知识分类项、5大类43种知识模板和对象模板、12085种知识关系。
- 电力领域评审大模型:在基建工程资料合理性、合规性审查中,对常规输变电工程可实现分钟级预审。
- 银行业金融知识中台:数据整合效率提升,搜索准确率达到90%,专家问答覆盖率超过80%。
- 行业安全管控平台:自动化搜索达到70%,搜索结果高准确性达到98%。
- 电阻点焊工艺智能管理:实现焊接作业前质量预测,质量合格率提升至99.8%。
- 设备故障维修助手:故障案例查找时间从20分钟降至2分钟,知识检索准确率提升30%。
- 面向医生的医学知识助手:综合降低人工成本60%,新产品上线效率提升80%以上。
- 基于知识图谱的大模型 RAG精准问答实践:针对结构化与半结构化文档,改善召回不全、关系缺失等问题,提升融合效果。
这些结果共同指向:当企业希望把LLM从“聊天”推入“生产系统”,结构化知识、检索与可验证链路往往是关键增益项,而不是单纯追求更大参数或更强生成能力。
结语:技术背后的管理思考
知识图谱与大模型融合之所以在政务、金融、能源、制造、医疗等行业集中爆发,本质上是企业对“可控智能”的一致诉求:既要LLM的自然语言交互与生成效率,也要KG带来的结构化约束、可解释性与可审计性。对组织管理者而言,这类融合范式会直接改变三件事:第一,知识资产的沉淀方式从“文档堆积”转向“Schema+实体/关系/事件”的可运营体系,知识更新更像持续工程而非一次性项目;第二,工作流程会被重新拆解为“语义分解—检索—协同推理—溯源输出”的链路,推动审查、客服、风控、运维等岗位向“人机协作+规则治理”演进;第三,人才画像会更偏向“领域专家×数据治理×提示与评估”复合能力,尤其需要懂业务又懂评测与合规边界的人。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把知识、流程与人员能力放进同一套可度量、可迭代的系统中,企业才能真正把AI从试点带到规模化。









