【导读】开源文本转语音(TTS)正在从“能用”走向“可生产”。近期,Qwen团队推出Qwen3-TTS并以Apache 2.0协议开放权重与代码,主打跨语言高保真合成、3秒语音克隆与超低延迟流式输出。围绕1.7B与0.6B两种模型规格、Qwen3-TTS-Tokenizer-12Hz的“12Hz无损压缩”路线,以及FlashAttention 2、GPTQ-Int8等工程化优化手段,Qwen3-TTS给出了从开发验证到线上部署的一套较完整路径。

一、Qwen3-TTS的开源定位:两档模型覆盖从演示到生产
从产品形态看,Qwen3-TTS并非只给出单一“大模型”,而是提供两种参数规模以适配不同硬件与质量目标,并将“跨语言”作为默认能力之一。
开源与许可
- 采用 Apache 2.0 许可,意味着在合规前提下可用于商业场景,自托管也更便于企业做成本控制与数据治理。
两大模型版本与资源门槛
- Qwen3-TTS 1.7B:强调峰值质量与完整能力,面向生产/高质量合成需求。
- 参数量:17亿(1.7B)
- 权重体积:4.54GB
- VRAM:6–8GB(最低),更高VRAM可带来更稳的吞吐与并发空间
- Qwen3-TTS 0.6B:轻量化方案,适合资源受限或快速验证。
- 参数量:6亿(0.6B)
- 权重体积:2.52GB
- VRAM:4–6GB(最低)
为了更清晰地对齐选型,常见对比可概括为:
| 维度 | 1.7B | 0.6B |
|---|---|---|
| 参数规模 | 17亿 | 6亿 |
| 存储大小 | 4.54GB | 2.52GB |
| VRAM门槛 | 6–8GB | 4–6GB |
| 侧重点 | 峰值质量 | 均衡效率 |
| 典型场景 | 生产环境、高质量合成 | 演示、资源受限部署 |
在工程实践中,这种“双档位”结构的价值在于:同一套API/工作流下,团队可以用0.6B做快速迭代与A/B验证,再切换到1.7B承接更高质量的业务目标。
二、核心技术路线:Qwen3-TTS-Tokenizer-12Hz如何支撑“高保真压缩”
Qwen3-TTS的一个关键技术点是 Qwen3-TTS-Tokenizer-12Hz。从命名与指标呈现来看,它更像是面向语音表征的“离散化/压缩”组件:在压缩语音信息的同时尽量保持可懂度、自然度与说话人一致性,从而为后续生成提供稳定的语音“中间表示”。
12Hz Tokenizer带来的指标表现(素材给出的硬指标)
- STOI:0.96(可懂度)
- UTMOS:4.16(自然度主观质量相关指标)
- 说话人相似度:0.95
- PESQ宽带:3.21
- PESQ窄带:3.68
这些指标组合传递出一个信息:Qwen3-TTS在“压缩-再生成”的链路上,试图把语音主观听感的损失控制在较低水平,从而更接近“可用于生产内容”的要求。对于企业端常见的音频资产生产(客服话术、培训课件、视频配音、多语种本地化),这类Tokenizer能力通常决定了:同样的算力预算下,模型是否能在质量与吞吐之间取得更好的平衡。
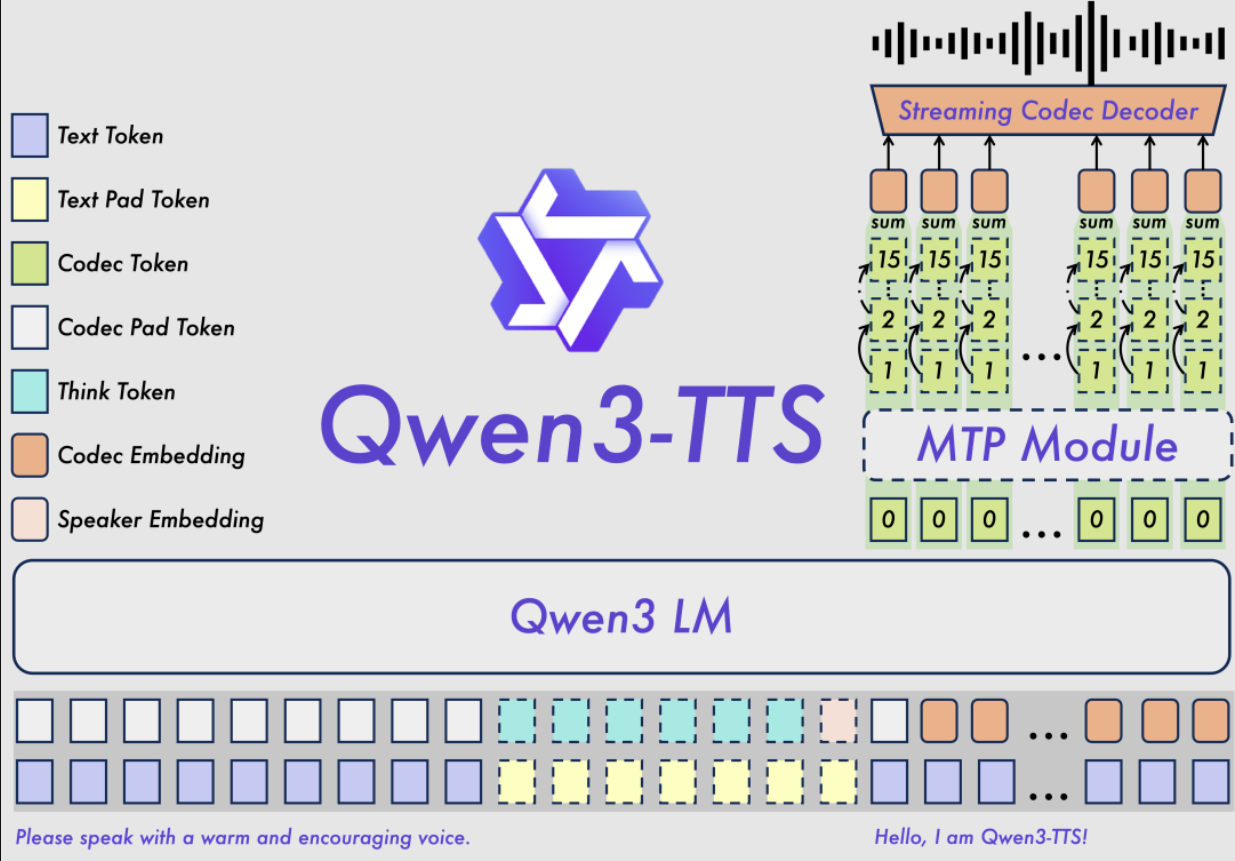
三、从部署到优化:VRAM、FlashAttention 2与GPTQ-Int8的工程化组合
与不少“只给论文指标”的TTS项目不同,Qwen3-TTS在硬件建议与优化路径上给出了更贴近工程落地的参考,尤其围绕VRAM门槛、加速算子与量化。
1)硬件需求与GPU建议(按模型分层)
Qwen3-TTS-1.7B
- 最低VRAM:6GB
- 推荐VRAM:8GB
- 最优VRAM:12GB+
Qwen3-TTS-0.6B
- 最低VRAM:4GB
- 推荐VRAM:6GB
- 最优VRAM:8GB+
推荐GPU档位(素材建议)
- 入门级:NVIDIA GTX 1070(8GB VRAM)或同等
- 中端:NVIDIA RTX 3060(12GB VRAM)或更高
- 生产环境:NVIDIA RTX 4080 或 A100(16GB+ VRAM)
系统侧要求
- Python:3.8+
- CUDA:需要支持CUDA的兼容GPU
- 存储:模型权重约 3–5GB
- 内存:建议 16GB+
这些参数意味着:哪怕不追求极致并发,Qwen3-TTS也把“消费级显卡可跑通”作为重要门槛之一,降低了原型验证成本。
2)性能优化:FlashAttention 2、量化与批处理
在推理侧,素材明确列出三类常见手段:
- FlashAttention 2:推荐用于以 torch.float16 或 torch.bfloat16 加载的模型,目标是降低注意力计算开销、提升吞吐并改善显存占用结构。
- 量化:例如 GPTQ-Int8,用于将内存占用降低 **50–70%**(该比例为素材给出的范围)。
- 批处理(batching):通过针对硬件调参批量大小,在稳定性与吞吐间取平衡。
对企业部署而言,这三项几乎决定了“能不能在既定GPU预算下跑到目标QPS/并发”,也影响是否要选择自托管还是购买外部API。
3)低延迟流式:97ms首包与双轨混合架构
Qwen3-TTS强调其“双轨混合流式生成架构”,并给出关键延迟指标:
- 首包延迟:低至97毫秒
- 端到端合成延迟:实时应用中低于100毫秒
在对话式AI、实时翻译、交互式语音应用中,首包延迟往往比总体音频渲染时间更影响用户感知。97ms级别意味着系统可以更早“开口”,同时在后台持续生成后续音频,提升交互的连续性。
四、能力清单与对标:多语言WER、3秒克隆与长文本稳定性
在功能层面,Qwen3-TTS将能力拆为更接近“可用功能点”的模块,而不是停留在单一合成质量描述。
1)自然语言语音设计
它支持用自然语言描述来定义声音与表达方式,包括:
- 音色特征(如“深沉的男声”“明亮的女声”)
- 韵律控制(如“慢速强调说话”“快节奏充满活力”)
- 情感基调(如“温暖友好”“专业权威”)
- 角色属性(如“年轻科技爱好者”“经验丰富的叙述者”)
这类“指令式”控制若能稳定工作,通常能降低内容团队与算法团队之间的沟通成本,让声音风格更可配置、可复用。
2)3秒语音克隆:Qwen3-TTS-VC-Flash
素材提到 Qwen3-TTS-VC-Flash 支持仅 3秒音频输入的语音克隆,典型用途包括:
- 个性化应用
- 跨内容保持一致声线
- 辅助失语人群的声音重建
- 跨语言内容本地化
从治理角度看,语音克隆能力越强,企业越需要同步建立授权、审计与水印/检测等配套机制,以避免声音资产滥用。
3)多语言支持:10种语言 + 母语级质量诉求
Qwen3-TTS覆盖10种语言:
中文、英语、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语。
素材强调“质量达到母语水平”,并特别提到中文方言支持与自然代码切换。
4)性能基准:WER与说话人相似度
素材给出的关键基准包括:
- **多语言平均WER:1.835%**(10种语言)
- 说话人相似度(10种语言平均):0.789
- 对标维度提到:跨语言适应性表现突出;并声称在相似度层面超越MiniMax和ElevenLabs(此处为素材表述)
此外还提到长文本稳定性:
- 可合成 10分钟以上 的自然语音
- 长音频上无质量下降
- 说话人特征保持一致
对实际生产来说,“长文本不崩”往往比短句音质更关键,因为课程、播客、有声书等场景天然是长音频。
五、安装与快速上手:从transformers到FlashAttention 2
Qwen3-TTS的安装与示例更偏“开发者可直接复现”的路径,以下保留关键命令与代码结构。
安装步骤
# 从Hugging Face安装 pip install transformers torch # 克隆仓库 git clone https://github.com/QwenLM/Qwen3-TTS.git cd Qwen3-TTS # 安装依赖 pip install -r requirements.txt # 可选:安装FlashAttention 2以优化性能 pip install -U flash-attn --no-build-isolation
基本使用示例(自定义音色)
from qwen_tts import Qwen3TTSModel import soundfile as sf # 加载模型 model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice") # 使用自定义音色生成语音 wavs, sr = model.generate_custom_voice( text="你好,这是Qwen3-TTS在说话。", language="Chinese", speaker="Xiaoming" ) # 保存音频 sf.write("output.wav", wavs[0], sr)
语音克隆示例(3秒样本)
from qwen_tts import Qwen3TTSModel # 加载用于语音克隆的基础模型 model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-Base") # 从3秒音频样本克隆声音 wavs, sr = model.generate_voice_clone( text="您的文本内容", voice_sample_path="voice_sample.wav", language="Chinese" )
从接口形式看,generate_custom_voice 与 generate_voice_clone 把“声音设计/克隆”能力抽象为可编排的函数入口,利于在业务系统里封装为服务(例如TTS微服务 + 任务队列 + 音频存储)。
结语:技术背后的管理思考
当TTS从“效果展示”进化到“开源可生产”,企业管理层真正需要关注的,往往不只是音质指标,而是它对流程与组织协作方式的重塑:第一,内容生产链路会被显著压缩——培训课件、产品宣讲、客服话术、多语种视频配音等环节,从“录音棚排期+反复返工”转向“脚本驱动+参数化生成”,交付周期与边际成本都会改变;第二,岗位能力结构会重新分配——内容团队需要更强的Prompt写作、声音风格规范、版权与授权意识,技术团队则要补齐流式架构、GPU资源治理、量化与监控告警等MLOps能力;第三,合规与风控必须前置,尤其是3秒语音克隆一类能力,需要配套权限、审计、素材来源证明与内部使用边界。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把新工具纳入标准流程、明确责任边界、建立技能体系与治理机制,才能把“模型能力”转化为可持续的组织效能提升。