【导读】Ollama 在 2026 年 2 月发布 v0.15.6。表面上是补丁版本,但实际包含模型加载机制、上下文限制、Claude 环境变量、Docker 构建路径、云端模型拉取逻辑、tokenizer 模块重构等一系列结构性调整。代码层面体现为多模块迁移与依赖改造,并通过更密集的单元测试覆盖来压住兼容性风险。对开发者而言,它既影响 CLI 行为,也会触及集成脚本与二次开发接口。
一、版本变更全景:一次“删多加少”的结构性整理
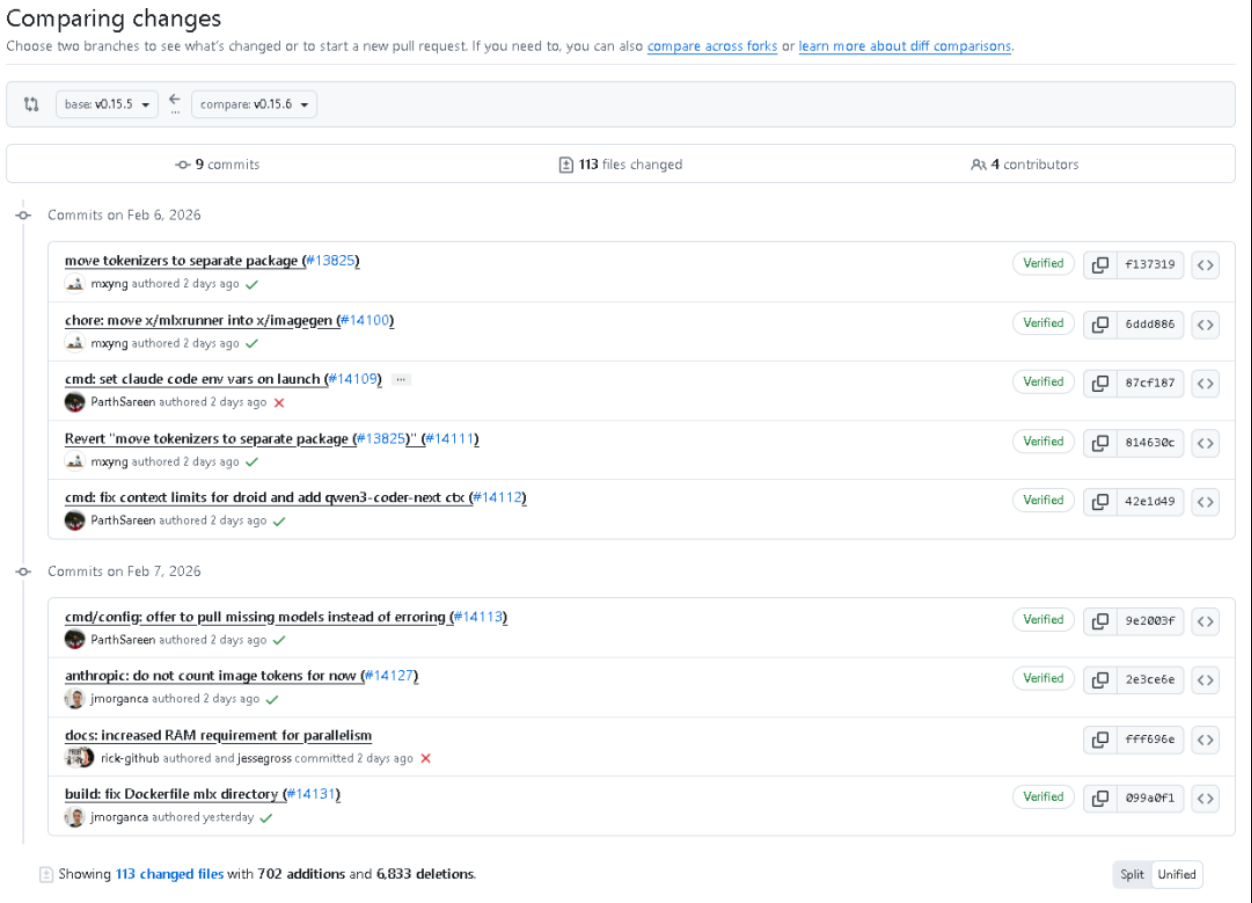
从变更规模看,v0.15.6 的特征非常鲜明:提交次数不多,但涉及文件面广,新增行数远小于删除行数,典型指向“迁移/重排/去冗余”的工程动作。调整集中在 cmd/config、llm/server、model、runner、server 等核心路径,并新增独立子包 tokenizer,同时将 x/mlxrunner 的职责迁移并改造为 x/imagegen。
本次更新围绕九类议题展开:
- 修复 ollama launch droid 的上下文限制(context limits)问题
- ollama launch 在缺少模型时支持自动下载(交互式确认),不再直接报错
- 修复 ollama launch claude 在提供图像时导致 context compaction 的异常行为
- 新增对 ANTHROPIC_* 环境变量的支持,优化 Claude Code 的模型选择链路
- 强化 cmd/config 测试覆盖
- 将分词与文本处理从 model 包剥离,形成独立 tokenizer 包
- 将 x/mlxrunner 重构为 x/imagegen(多模态能力接口化)
- 修正 Dockerfile 构建路径(mlx 目录层级变化引发的 COPY 错误)
- 更新 FAQ,明确 OLLAMA_NUM_PARALLEL 与 OLLAMA_CONTEXT_LENGTH 的内存乘积关系
这些变化的共同指向是:把“易变的边界层”(模型拉取、配置、分词、图像生成)拆解成可独立测试、可替换的模块,让核心推理链路更稳定。
二、关键功能改动:上下文修复、自动拉取与Claude变量链路
1)上下文限制修复:Droid 的 maxOutputTokens 动态收敛
此前在某些场景下执行:
ollama launch droid
可能出现上下文溢出或响应不稳定。v0.15.6 针对 Droid 场景补齐逻辑:当识别为云模型(cloud model)时,通过查表(lookup)自动应用云侧限制,从而动态调整 maxOutputTokens,避免输出上限与云端策略不一致引发的行为异常。
相关逻辑类似于:
if isCloudModel(context.Background(), client, model) { if l, ok := lookupCloudModelLimit(model); ok { maxOutput = l.Output } }
同时,云模型限制表新增对 qwen3-coder-next 的支持:Context: 262,144 与 Output: 32,768。这类“超长上下文 + 大输出”组合对工具型交互(代码编辑、长文档分析、跨文件重构)尤为关键;而一旦客户端侧限制处理不严谨,最容易触发的就是 context limits 与压缩策略异常。
为了保证行为可回归验证,测试用例补齐了云模型限制识别、:cloud 后缀兼容、本地与云混合输入等边界场景。
2)ollama launch 自动下载缺失模型:从“硬失败”到“可交互修复”
旧行为是:模型不在本地缓存则直接退出,用户需要先 ollama pull model。v0.15.6 将这一段体验改成“自动检测 + 交互确认下载”。核心流程是先 Show 判断模型是否存在;若不存在则弹出确认提示,确认后执行拉取。
对应函数形态为:
if _, err := client.Show(ctx, &api.ShowRequest{Model: model}); err == nil { return nil } if ok, err := confirmPrompt(fmt.Sprintf("Download %s?", model)); err != nil { return err } else if !ok { return errCancelled } return pullModel(ctx, client, model)
这项改动对两类人影响明显:
- 开发者/试用者:减少首次体验的阻断点,launch 更像“开箱即用”。
- 自动化/脚本用户:需要注意“交互式确认”的引入,可能影响无终端(non-terminal)环境下的执行路径;因此测试中也覆盖了 NoTerminal 情形,避免 silent fail 或行为不确定。
3)Claude 环境变量增强:ANTHROPIC_* 与模型别名映射更细
在 cmd/config/claude.go 中新增 modelEnvVars,目标是让 Claude Code 在不同层级(primary/fast/subagent)模型选择上更可控,并把 alias 映射到多个环境变量出口。
新增变量包括:
- ANTHROPIC_DEFAULT_OPUS_MODEL
- ANTHROPIC_DEFAULT_SONNET_MODEL
- ANTHROPIC_DEFAULT_HAIKU_MODEL
- CLAUDE_CODE_SUBAGENT_MODEL
示意逻辑为:
return []string{ "ANTHROPIC_DEFAULT_OPUS_MODEL=" + primary, "ANTHROPIC_DEFAULT_SONNET_MODEL=" + primary, "ANTHROPIC_DEFAULT_HAIKU_MODEL=" + fast, "CLAUDE_CODE_SUBAGENT_MODEL=" + primary, }
这类“多出口变量”看似琐碎,实则常用于解决:同一工具链中不同子模块默认模型不一致导致的输出差异(例如主对话用高质量模型、快速分支用 fast 模型、子代理仍要回到 primary 模型以保证一致性)。配套测试用例数量显著增加,说明团队在“配置链路正确性”上投入了更高权重。
三、最重量级重构:tokenizer 独立化与 imagegen 接管多模态
1)tokenizer 子包落地:TextProcessor 从 model 包剥离
v0.15.6 的底层改动中,影响面最大的是 tokenizer 重构:原本 BPE、SentencePiece、WordPiece、Vocabulary、TextProcessor 等逻辑都在 model 包内,推理与分词耦合较重;现在迁移至独立包 tokenizer,并同步调整 llm/server、runner、sample 等处的依赖与接口。
迁移关系清单如下(路径发生变化):
- model/bytepairencoding.go → tokenizer/bytepairencoding.go
- model/sentencepiece.go → tokenizer/sentencepiece.go
- model/wordpiece.go → tokenizer/wordpiece.go
- model/vocabulary.go → tokenizer/vocabulary.go
- model/textprocessor.go → tokenizer/tokenizer.go
- model/testdata/* → tokenizer/testdata/*
接口侧也有明显变化:例如 llm/server 中字段从
- textProcessor model.TextProcessor
变为 - tokenizer tokenizer.Tokenizer
并且 model.NewTextProcessor 的返回类型也转为 tokenizer.Tokenizer,让“分词器作为独立可替换组件”成为默认架构。
这类解耦带来三个直接收益:
- 分词逻辑可单独测试与优化(包括内存结构、Encode/Decode 性能、词表管理)
- 模型结构与 tokenizer 演进互不阻塞,降低联动修改成本
- 为多 tokenizer、多语言 token 化乃至后续统一接口打基础(尤其是工具链场景下可能同时跑多模型)
但也带来迁移提示:所有直接引用 model.TextProcessor 的外部工具,需要改为 tokenizer.Tokenizer,否则编译期就会出现不兼容。
2)从 x/mlxrunner 到 x/imagegen:图像生成能力“模块化接管”
多模态相关链路也进行了明显梳理:runner 层删除对 mlxrunner 的调用入口,统一为:
- --ollama-engine → ollamarunner.Execute
- --imagegen-engine → imagegen.Execute
这意味着图像生成任务逐步由 x/imagegen 完整接管,MLX 不再以原方式暴露。server 层也同步调整:routes 导入路径指向 x/imagegen/manifest,调度器 sched.go 重写加载逻辑,loadMLX 转由 imagegen.NewServer 承接。
工程层面,这是一种“把多模态作为独立产品线能力封装”的信号:接口更统一、职责更清晰,未来扩展不同后端(包括替换推理框架、切换 manifest 组织方式)也更容易。
3)Dockerfile/CMake 路径修复:构建链路跟随模块迁移
随着目录结构调整,构建脚本也必须同步更新,否则容器构建会直接失败。v0.15.6 修复了 MLX 目录层级变化导致的 COPY 路径错误:
更新前:
- COPY x/ml/backend/mlx x/ml/backend/mlx
更新后:
- COPY x/imagegen/mlx x/imagegen/mlx
并在 CMakeLists.txt 中将子目录引用调整为:
- add_subdirectory(${CMAKE_CURRENT_SOURCE_DIR}/x/imagegen/mlx)
对于维护自定义镜像或企业内部 CI 构建链路的团队,这类变更属于“必须跟进”的硬要求,否则会在构建阶段被阻断。
4)FAQ 对并行与内存的表述更精确:面向可预测的容量规划
OLLAMA_NUM_PARALLEL 的解释由模糊的“自动选择”变为更明确的语义:
- 默认并行度为 1
- 内存需求随 OLLAMA_NUM_PARALLEL * OLLAMA_CONTEXT_LENGTH 成比例增长
这对做容量评估、边缘设备部署、或在 GPU/内存受限环境(如特定 Windows Radeon 场景)上跑长上下文任务的用户更友好:并行度不再是“猜测”,而是可以纳入明确的算账模型。
结语:技术背后的管理思考
从 v0.15.6 的改动可以看到,Ollama 在做的并不只是“修 bug”,而是把影响稳定性的关键路径——上下文限制(context limits)、模型获取(show/pull)、配置链路(ANTHROPIC_*)、以及分词与多模态模块(tokenizer、imagegen)——系统性地拆出来、测起来、规范起来。对企业而言,这类工程化动作的价值不止体现在开发者体验,更体现在可控性:当 LLM 被纳入研发、客服、知识库与办公协同时,真正的风险往往来自“边界不清、接口不稳、行为不可预测”,而不是单点性能指标。与此同时,FAQ 中对 OLLAMA_NUM_PARALLEL 与 OLLAMA_CONTEXT_LENGTH 的乘积关系明确化,也提示组织在引入长上下文与并行推理时,必须把容量规划、成本核算与SLA一起纳入治理。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:通过标准化接口、可回归测试与清晰的资源模型,把AI能力从“能用”推进到“可规模化落地、可持续运营”。