












































【导读】图像生成模型长期面临“画面好看但文字难用”的痛点,尤其在PPT、海报、信息图与漫画等强排版场景中更为突出。最新发布的Qwen-Image-2.0将“专业文字渲染”“2K细腻质感”“语义遵循强化”与“轻量架构提速”打包升级,并把文生图与图像编辑能力合并到同一模型范式中。随着阿里云百炼API开启邀测及Qwen Chat开放体验,面向生产级工作流的图文生成能力正在进入可规模化落地阶段。
一、从“能画”到“能交付”:Qwen-Image-2.0的核心升级指向
围绕企业级内容生产常见诉求,Qwen-Image-2.0的更新点更像是对“可用性指标”的系统性加固,而不只是单纯追求审美或风格多样性。综合发布信息,其能力被归纳为四条主线:
- 更专业的文字渲染:模型支持 1k token 指令长度,目标是让“复杂排版+大段双语+多模块信息图”这类提示词能够直接落到成品图中。典型输出包括PPT页、海报、漫画分镜、A/B测试结果信息图等。
- 更细腻的真实质感:支持 2k分辨率 生成,用于强化人物、自然、建筑等写实场景中的纹理细节与材质表现。
- 更强的语义遵循:强调“理解生成一体化”,并提出“生图编辑二合一”的定位,即同一模型同时覆盖 文生图 与 图生图/编辑 任务,减少在工作流中切换模型或管线的成本。
- 更轻量的模型架构:以更小模型实现更快推理速度,面向实际生产节拍与算力约束。
在可获得的体验路径上,开发者侧已通过阿里云百炼开放 API邀测,普通用户则可在 Qwen Chat(chat.qwen.ai) 入口体验“生成图像”功能。这种“API+交互产品”双入口意味着其目标用户既包括创作型个体,也包括需要将图文生成嵌入业务系统的团队。
二、生图与编辑合流:Omni能力为何成为这轮升级的“主叙事”
过去一段时间,图像大模型常见的产品形态是“生成模型一套、编辑模型一套”,生成擅长从零到一,编辑擅长对现有图像做定点修改、风格迁移或一致性保持。Qwen-Image-2.0的关键转向在于:把两条技术路线合并为一个“omni模型”思路——既要画得出来,也要改得动,还要在两个任务上同时保持性能。
从其对外的模型演进叙述来看,项目早期存在两条分支探索:
- 生图支线:更关注图像生成的准确性与真实性,例如强调文字渲染精准、细节质感强化等。
- 编辑支线:更关注功能性与一致性,例如从单图编辑到多图编辑,再到一致性提升等。
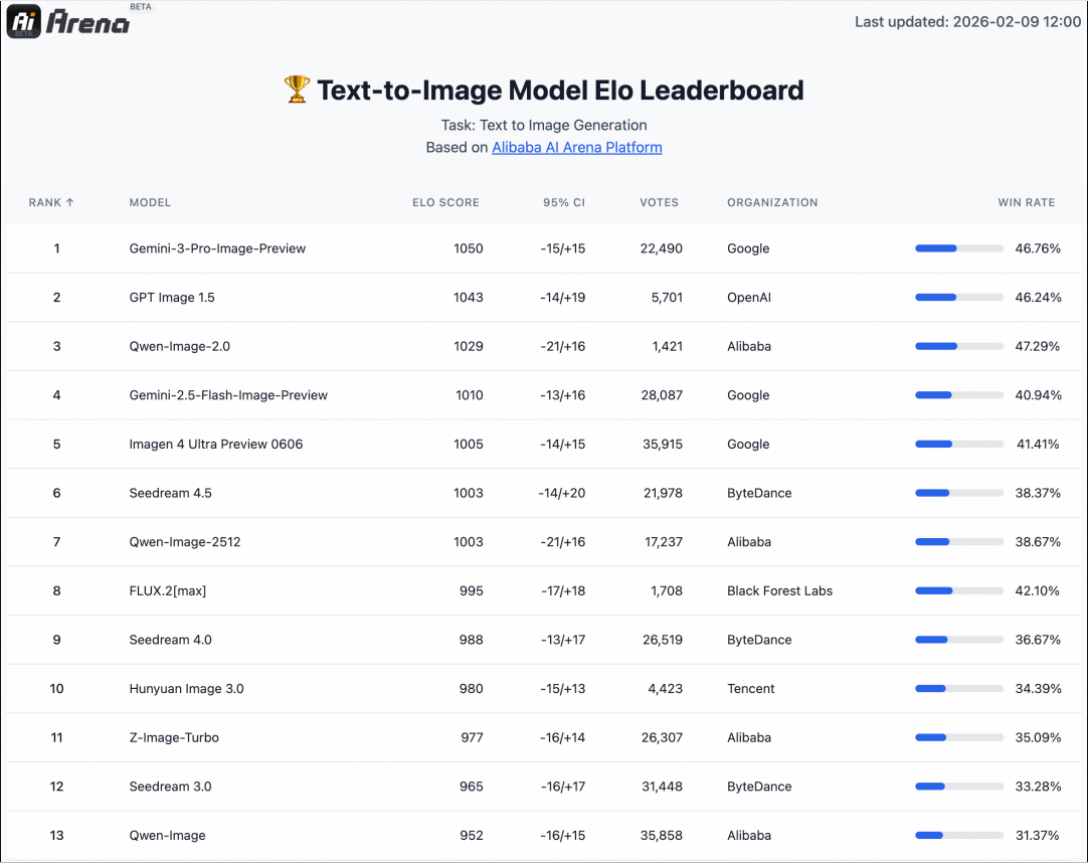
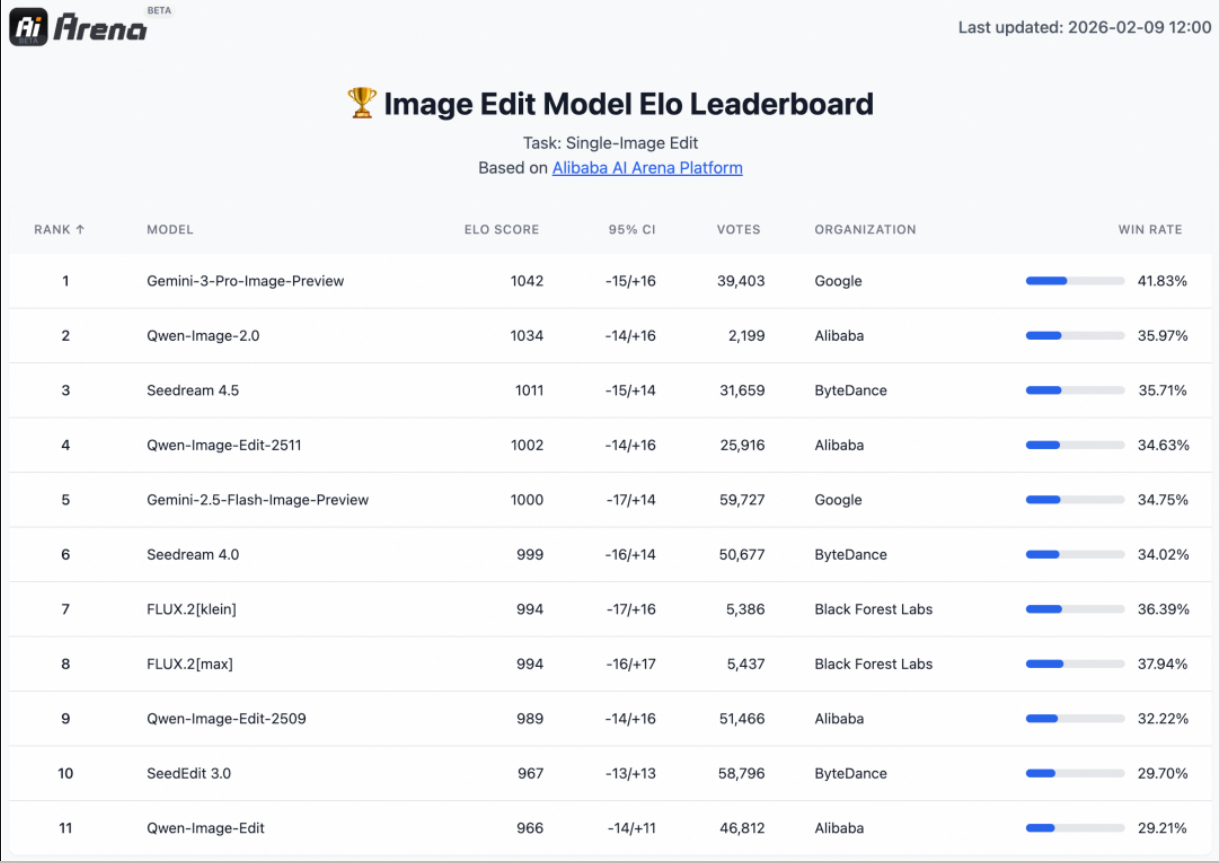
Qwen-Image-2.0将两条支线“合二为一”,并在基准对比上给出了信号:在 AI Arena 的盲测里,作为“生图编辑二合一”的模型,能够在 文生图 与 图生图 两类基准中同时取得更优表现。对行业而言,这一方向的价值不止在“少用一个模型”,更在于统一能力后,文字渲染、写实质感等生图增益可以迁移到编辑任务中,反过来编辑的一致性能力也能改善生成任务的稳定性。
三、文字渲染进入“工程化阶段”:准、多、美、真、齐的能力拆解
Qwen-Image-2.0被反复强调的卖点并不是“风格”,而是“文字”。从展示案例可归纳为五个维度:准、多、美、真、齐,它们分别对应不同的生产级难点。
1)“准”:复杂画中画与多层结构仍能保持文字正确
在一页由模型直出的“发展历程时间轴PPT”中,提示词不仅要求标题、时间节点、分支结构,还要求节点内嵌入“画中画”(例如组图、对话框文字、透明文本框标注)。此类任务常见失败点是:时间轴结构乱、分支关系错、字形拼写错误或文本溢出。案例意在说明模型能将结构与文字一并对齐,实现“可交付的PPT页”。
2)“多”:1k token让信息图提示词可承载更长的结构化内容
信息图类提示词往往包含多栏布局、双语对照、统计指标、箭头流程、图表元素、显著性检验字段等。Qwen-Image-2.0展示了“AB Testing Results Report A/B测试结果汇报”这种长提示词,包含:
- Revenue Uplift、ROI、Scalability Score、Next Steps
- Statistical Analysis流程与p<0.05、95% CI、Cohen's d=0.32等字段
- Business Impact表格中Control A与Variant B对比、p=0.003等标注
这类“硬信息密度”对模型而言不只是生成文字,更是在空间里排布文字并保持对齐关系,属于从审美生成走向“版式生成”的门槛能力。
同时,材料也给出一种常见工作流:先输入简短需求(如“帮我生成一个手绘风格的杭州两日禅意人文之旅双语海报”),再由LLM扩写为长提示词,再交给图像模型渲染。这里隐含的是“LLM + 图像模型”的协作链路:LLM负责把需求结构化、细化字段,图像模型负责把字段可靠落版。
3)“美”:在图文混排中更像“懂排版”的生成
在水墨长卷中题写柳永《雨霖铃·寒蝉凄切》、在工笔画中以瘦金体书写宋词、在水墨设色中用小楷书写《兰亭集序》等案例,强调的不仅是字的正确,更是字与画的相互让位:例如模型倾向于把文字落在留白处,减少遮挡主体,从而使输出更接近“诗书画一体”的构图逻辑。
4)“真”:多介质文字与真实场景光学一致性
“玻璃白板+衣服Logo+杂志封面”的案例把难点放在多介质表面:
- 玻璃的反射、透光与倾斜透视
- T恤布料褶皱上的logo变形
- 杂志印刷质感与景深虚化下仍可辨识文字
提示词中还出现了更具体的结构化标注,例如:
- '[8B Qwen3-VL Encoder] → [7B Diffusion Decoder] → pixels (2048×2048)'
- 2048×2048、7B 等关键信息
这类“写实照片里写文字”的可用性,直接决定了模型能否进入品牌视觉、培训材料、产品营销物料等强依赖文字可信度的场景。
5)“齐”:表格、日历、漫画对话框的规整排布
对齐能力往往是“最后一公里”:文字即使正确,只要网格错位、行距不稳、气泡文字溢出,就难以直接投产。展示案例覆盖:
- 2026年2月日历的7列网格与节假日标注
- 4x6格漫画里每格对话框文字居中对齐
- OKR信息图中相似段落的自动对齐与模块化结构
这些都指向同一个信号:模型正在从“生成一张图”转向“生成一套可读的版式系统”。
四、编辑能力的外溢收益:题词、九宫格、双图合成与跨次元编辑
当“生图编辑二合一”成立后,生成侧的文字能力会反哺编辑侧,具体体现在:
- 图片题词:可在现有图片上直接加赵孟頫楷书等纵排题词,意味着编辑任务不再局限于抠图、换背景,也能处理“文字叠加但要自然融合材质光影”的需求。
- 九宫格组图:例如“生成一个九宫格带不同拍照姿势的组图”,更像是面向社媒内容的结构化生产。
- 双图编辑合成:将两张照片中的同一位人物合成自然合照,提示词明确了镜头等效参数(如“等效全画幅50mm镜头拍摄(f/4.0,1/160s,ISO 200)”)、光照方向、站位间距与背景统一等约束,强调“无拼接痕迹”。
- 跨次元编辑:保持真实城市照片不变,把扁平化卡通形象以“壁画/海报插图”方式贴合到建筑周围,典型用于品牌传播或创意内容。
这些编辑用例的共同点是:对一致性、真实感与可控性的要求更高。当编辑任务也能稳定输出,才更接近企业可复用的内容管线。
结语:技术背后的管理思考
以Qwen-Image-2.0为代表的图文生成模型,正在把“设计能力”从少数岗位的专门技能,部分转化为一种可编排、可复用的组织能力:用1k token提示词把需求写清楚,用2K输出把细节交付到位,再通过生图编辑二合一减少多模型切换带来的返工与沟通损耗。对企业管理者与HR团队而言,这会带来三点直接变化:其一,内容生产链路将更依赖“提示词工程、视觉规范、素材治理”等新型能力,岗位画像需要同步更新;其二,市场、招聘、培训、内宣等部门会更高频地生成PPT/海报/信息图,标准化模板与审批流程需要更轻量但更可追溯;其三,随着API化交付成为主流,如何把生成能力嵌入业务系统并形成可度量的效率指标,将成为数字化转型的新课题。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把人的创造力从重复排版与低价值修图中释放出来,让协作更快、交付更稳、组织效能更可持续。

