【导读】围绕长文档的 RAG 实践,行业长期受困于 Chunk 切片、重叠度调参、向量数据库运维与“检索到但不相关”的错配问题。近期开源项目 PageIndex 选择绕开向量检索路线,提出“无向量推理型 RAG”:先把 PDF 构造成语义化树状索引,再让 LLM 在索引树上进行路径搜索推理,从“语义相似度”转向“逻辑相关性”。在 FinanceBench 上,该方案宣称可将金融文档分析准确率提升至 98.7%,并强调可解释、可追溯的检索链路。
一、向量RAG的“相似度陷阱”:为什么长文档越做越难
RAG(检索增强生成)在企业知识问答、合规检索、投研助手、技术支持等场景已成标配,但一落到几百页的专业材料(法律条文、审计报告、SEC 申报文件、技术手册、学术教材),传统“向量检索 + 生成”的套路往往会暴露出结构性短板。
1)“相似性”并不等于“相关性”
向量检索的核心是 embedding 后的相似度度量,本质上擅长回答“这段话和问题语义像不像”。但在金融、法律、工程类文本中,正确答案常常来自严格的章节定义、前后依赖、条件约束、例外条款。很多时候,真正关键的不是“措辞相似”,而是“逻辑路径匹配”。
例如问题询问某项披露要求的例外条件,语义相似的段落可能在“概述”里,而真正的约束藏在“定义”“适用范围”“附注”或某个子条款里——相似度不保证检索到该路径。
2)暴力切片带来的上下文破坏与调参成本
对长文档做 RAG,常见工程动作是 Chunking:设置 chunk size、overlap、切片策略(按句、按段、按页、按标题)。但专业文档天然是层级结构:章—节—小节—条款—注释—表格。
一旦“硬切”,就容易出现:
- 关键定义被切到上一段,约束条件被切到下一段,检索只拿到一半证据;
- 表格/图注与解释正文分离,答案不完整;
- 需要不断微调 chunk size、overlap 才能“凑”出看起来可用的召回。
3)向量数据库与索引链路的工程负担
向量数据库引入了数据入库、索引构建、版本管理、检索延迟、重建成本等一整套运维与工程复杂度。即便加上 Rerank,很多团队仍会遇到“检索召回看似合理,但生成阶段仍然胡说八道”的问题,最终要靠提示词、过滤规则或人工校验兜底。
在这种背景下,PageIndex 的路线之所以引发关注,核心在于它不再把问题简化成“向量空间距离”,而是把长文档理解为可搜索的层级语义结构。
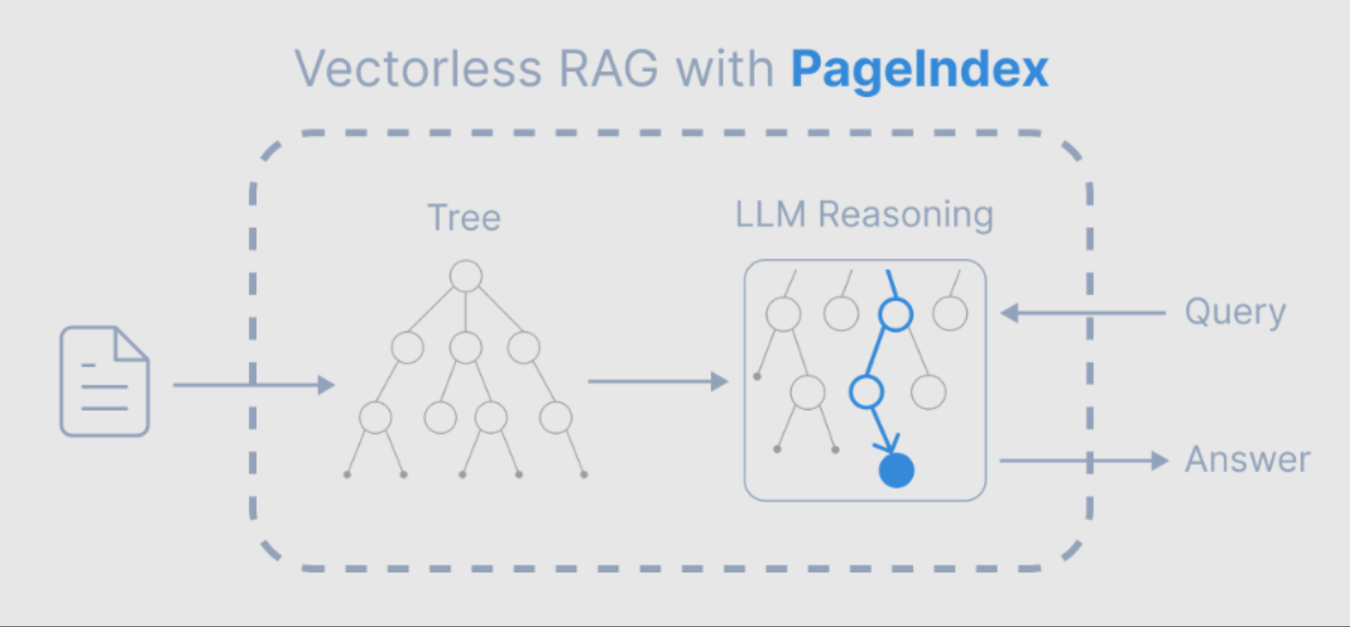
二、PageIndex 的核心架构:树状索引 + 树搜索推理
PageIndex 提出的“无向量推理型 RAG”,思路更接近人类专家处理长文档的方式:先看目录把握结构,再按问题逻辑定位章节,然后深入阅读取证。
其流程可概括为两步:
1)生成树状索引(Tree Index)
系统会把长文档转化为类似“目录”的语义化树形结构。该结构通常包含:标题层级、摘要信息、起始页码等,让文档从“连续文本”变成“可导航的语义地图”。
与常规 Chunking 不同,PageIndex 强调保留文档的自然章节结构,而不是把内容切成固定长度块。
2)树搜索推理(Tree Search Reasoning)
在检索阶段,LLM 不再直接对所有 chunks 做相似度检索,而是在索引树上进行路径搜索:根据问题逐层选择可能相关的章节/小节,进入更细粒度节点,直到定位到最可能包含依据的页面或段落。
这种方式的目标是让检索从“找得像”升级为“找得对”:利用 LLM 的推理能力进行路径决策,而不是仅靠 embedding 的距离度量。
从结果呈现上,PageIndex 还强调可解释性:模型能够说明证据落在“哪一章、哪一节、哪一页”,检索链路相对更可追溯,减少“黑盒召回”的不确定性。
三、四个关键优势:无向量、保结构、可解释、高准确
围绕企业最关心的落地成本与可控性,PageIndex 在公开信息中被反复强调的亮点主要集中在以下四点:
1)无需向量数据库(No Vector DB)
架构上绕开向量索引与向量库依赖,降低了“embedding 选型 + 入库 + 索引 + 召回调参”的工程复杂度。对一些希望快速验证 RAG 价值、或对向量库运维成本敏感的团队,这一点吸引力很强。
2)告别暴力切片,保留章节结构(Structure-Preserving)
通过树状索引保留文档层级,减少“切片破坏语义边界”的问题,尤其适合条例、审计披露、标准规范、教材类材料——它们的正确理解高度依赖结构,而不是句子级语义相似。
3)检索链路可解释(Explainable Retrieval)
当系统能明确指出依据来源位置(页码、章节路径),不仅便于排错和复核,也更贴近金融、法务、审计等高合规场景对“可追溯证据链”的要求。对企业来说,可解释性往往意味着更低的上线风险和更高的业务接受度。
4)在 FinanceBench 上达到 98.7% 准确率(High Accuracy)
公开数据提到:基于 PageIndex 的系统在 FinanceBench(金融问答基准测试)中达到 98.7% 的准确率,并宣称显著高于传统向量 RAG。
需要注意的是,评测结果通常会受数据切分、问题类型、判分口径、模型选择等因素影响;但从趋势上看,PageIndex 把“检索阶段的推理”放到台前,确实契合专业文档问答的核心矛盾:不是“没检索到相似内容”,而是“没定位到逻辑依据”。
四、长文档与PDF的现实难题:上下文窗口之外怎么办
即使 LLM 上下文窗口不断变大,长文档场景依旧存在典型痛点:
- 信息过载导致的注意力稀释:内容一多,模型更容易遗漏关键约束,出现“中间丢失”或只抓住局部表述。
- 跨页表格、图表与正文耦合:金融 PDF 常见“表格 + 注释 + 口径说明”跨页分布,单纯文本抽取很难保证完整证据链。
- 多轮查询的累积误差:一次检索偏了,后续生成再怎么写也很难“纠偏”,最终变成自洽但错误的回答。
PageIndex 的层级树把“先定位、再阅读”作为默认策略:先缩小搜索空间,再对目标章节做深度阅读与引用,从机制上减少无关上下文对生成的干扰。
此外,它还提出支持 Vision-based RAG:允许模型基于页面图像进行逻辑分析,从而在一定程度上绕开繁琐的 OCR 流程。对于图表密集、排版复杂、包含脚注/小字/多列表格的 PDF,这类路径确实更贴近真实资料形态(当然也意味着对多模态模型能力与成本提出更高要求)。
五、快速上手:从安装到生成树状索引
在使用方式上,PageIndex 提供了本地部署路径,也提供了类似聊天平台的交互形态,并提到可通过 MCP(Model Context Protocol) 插件集成到 Claude 或 Cursor 等工具链中,降低集成门槛。
开发者侧的基础流程包括安装依赖、配置 API 密钥,并对指定 PDF 生成树状索引。示例命令如下:
pip3 install --upgrade -r requirements.txtpython3 run_pageindex.py --pdf_path /你的文档路径.pdf
生成的索引通常会包含标题层级、摘要、起始页码等关键信息,用于后续在索引树上进行路径搜索推理。对工程团队来说,这种“先构建可导航结构,再让 LLM 做推理检索”的形态,也更便于做权限控制、审计记录与结果回放。
结语:技术背后的管理思考
PageIndex 把 RAG 的核心矛盾从“检索召回”推进到“检索推理”,本质上是在用更贴近专家工作流的方式,提升知识型工作的可靠性:先建立结构化索引,再沿着逻辑路径查证并给出依据。对企业管理而言,这类能力的外溢价值不止是“问答更准”,还会改变组织对知识资产的治理方式——文档是否具备清晰目录与一致口径、关键条款能否被追溯到页码与版本、回答是否可复核可审计,都会直接影响合规成本、决策效率与跨部门协作质量。与此同时,“推理型 RAG”也在重塑岗位技能要求:业务专家需要更会提出可验证的问题,研发与数据团队需要把检索链路做成可观测、可回放的系统工程,管理者则要建立从知识沉淀到使用闭环的制度与流程。正如红海云在探索新一代人力资源管理解决方案时所强调的,技术的终极价值在于赋能组织:把分散的知识与流程连接起来,让效率提升与风险控制同时可度量、可落地。