












































很多人这两年聊RAG,容易把它理解成一个“外挂知识库”的小技巧:切分文档、做向量化、召回几段上下文、拼进Prompt,然后等模型输出。这个流程当然没错,但它更像RAG的早期形态,而不是它最终会停留的位置。
真正在生产环境里做过一段时间,会发现麻烦并不在“能不能检索出来”,而在“检索能力能不能持续演进、复用、被不同应用共享”。一旦业务里出现多个Agent、多个Copilot、多个知识场景,RAG如果还只是写死在单个应用里的内部模块,很快就会变成重复建设、口径不一、维护混乱。
所以现在看RAG,重点已经不只是生成前补几段上下文,而是它正在从应用内流程,下沉为AI系统里的检索基础设施。这个变化不算花哨,但很关键。很多团队后面会卡住,往往就卡在这里。
一、RAG最初为什么长成应用内流程
早期RAG的实现路径很自然。
一个典型链路通常是这样:

这个结构适合验证需求,也适合快速上线。因为它解决的是一个很具体的问题:大模型参数里没有你的私有知识,或者知识过期,于是需要在推理前补一点外部信息。
在这个阶段,RAG更像是LLM应用的一段增强逻辑,几个特点很明显:
- 检索入口通常只有一个用户问题
- 检索策略比较固定,常见是向量召回 + rerank
- 上下文消费方通常只有一个模型调用
- 检索结果只为当前问答服务,不强调跨应用复用
这套做法在Demo、单点知识助手、内部问答系统里都挺好用。问题是,一旦业务开始变复杂,它的边界就出来了。
Native RAG的局限,不在召回率本身
很多人会先盯着召回质量,觉得RAG做不好,是切块不对、embedding不够强、重排模型不够准。这些当然重要,但它们通常不是第一层矛盾。
更麻烦的是架构层的问题。
1. 检索逻辑和应用流程强绑定
很多系统里,RAG是直接写在Agent或聊天服务内部的。业务代码里混着:
- query改写
- 检索源选择
- 权限过滤
- 召回融合
- rerank
- prompt拼装
结果就是,检索能力无法独立演进。你想优化召回,只能改业务服务;你想新增一个知识源,得在多个应用里重复接入;你想统一权限,也会变得很别扭。
这类系统前期跑得快,后期维护成本会一路上升。
2. 检索是静态的一次性动作
Native RAG往往默认:用户问一次,我检索一次,我生成一次。
但现实问题经常不是一跳能解决的。比如:
- 用户问题表达模糊,需要先澄清意图
- 一个问题需要跨多个知识域
- 回答过程中发现证据不够,需要二次补充检索
- 需要根据中间推理结果动态改写查询
这时,检索已经不是“生成前的准备动作”,而是整个推理过程里的动态能力。
3. 检索结果只服务Prompt,不服务系统
很多团队把检索的最终目标理解成“喂给LLM”。这会带来一个隐性问题:检索结果缺乏标准化表达。
真正的生产系统里,检索结果往往还需要服务:
- 引用与可追溯
- 权限审计
- 多轮缓存
- 工具编排
- 下游结构化决策
如果检索输出只是几段文本拼接,那它很难成为系统级能力。
4. 每个应用都在重复造轮子
这是最现实的一点。
一个企业里可能同时有:
- 知识问答助手
- 客服Agent
- 销售Copilot
- 研发文档助手
- BI分析Agent
- 流程自动化机器人
如果每个应用都自己实现一套RAG,最后通常会变成这样:
| 维度 | 应用内RAG | 独立检索层 |
|---|---|---|
| 知识源接入 | 每个应用重复接入 | 统一接入、统一治理 |
| 召回策略 | 各写各的 | 可复用、可配置 |
| 权限控制 | 容易分散 | 集中治理 |
| 效果优化 | 局部优化 | 全局可观测 |
| 成本 | 重复建设 | 边际成本更低 |
这也是为什么很多团队做到第二个、第三个AI应用时,会突然意识到:问题已经不是“怎么做一个RAG”,而是“怎么做一个可复用的检索层”。
二、独立检索层,解决的到底是什么
把RAG下沉成独立检索层,不是为了架构好看,而是为了把“检索”从某个应用的内部实现,变成AI系统的公共能力。
它通常会长成这样:
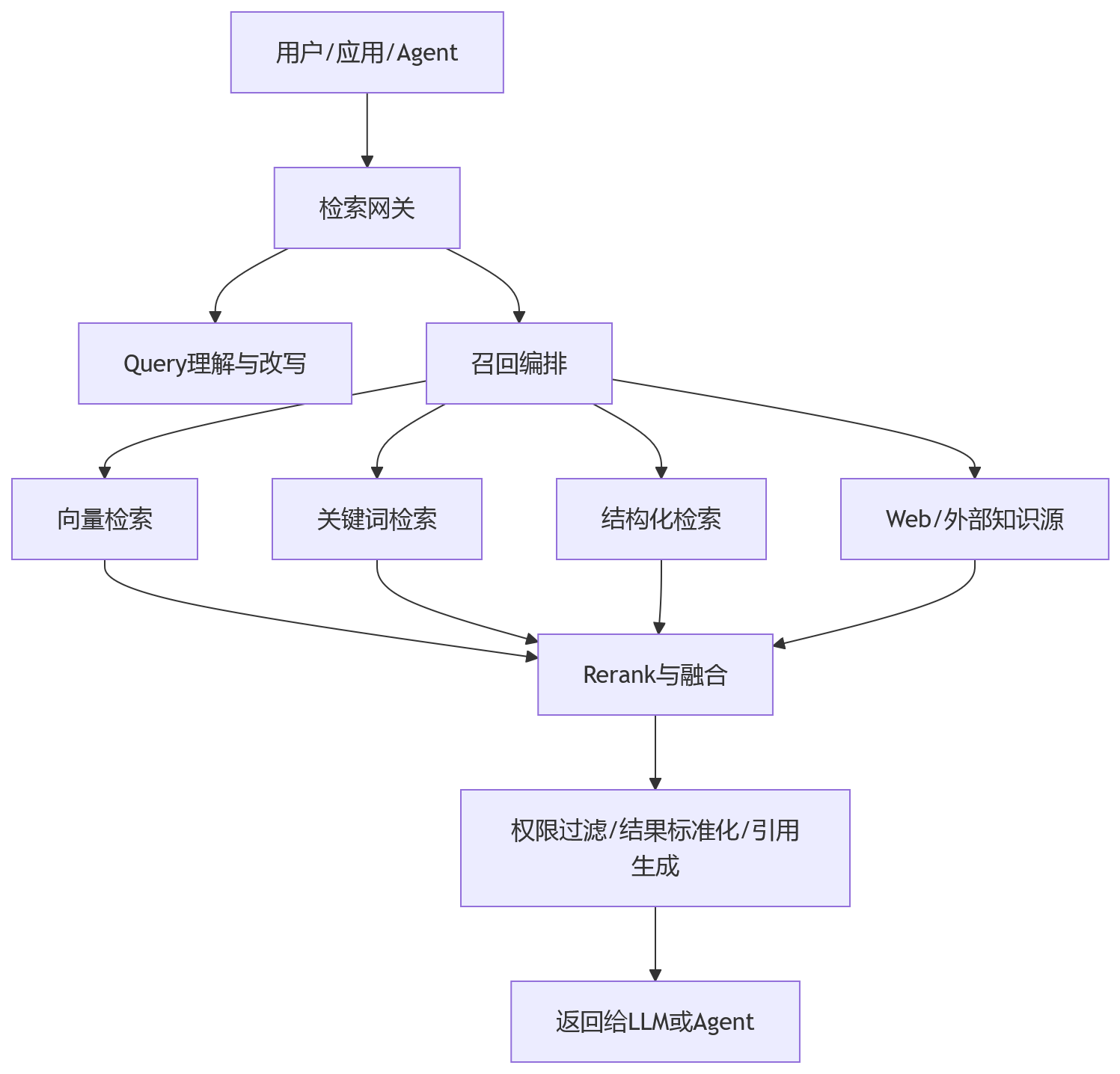
这里的关键变化有两个。
检索从“某种算法”变成“能力编排”
RAG早期经常被等同于向量检索,但真到复杂场景里,向量检索通常只是其中一个组件。
独立检索层更像一个编排系统,它要处理:
- 什么问题适合向量召回
- 什么问题应该走关键词或BM25
- 什么问题要查结构化数据库
- 什么问题需要实时外部搜索
- 多个来源怎么融合排序
- 哪些结果当前用户无权访问
换句话说,检索层的价值不只是“找内容”,而是“根据问题类型,调用正确的找内容方式”。
检索输出从文本片段变成标准化证据
如果把RAG做成基础设施,输出就不能只是几段字符串了。它最好至少包含:
- 文档内容
- 来源标识
- 时间戳
- 权限信息
- 置信度或排序分数
- 引用位置
- 文档类型
- 可追溯链接
一个简化示意:
{
"query": "过去30天华东区退货率为什么上升",
"results": [
{
"content": "3月下旬某批次产品因包装问题导致集中退货",
"source": "sales_report_2025_03.pdf",
"score": 0.91,
"timestamp": "2025-03-28",
"permissions": ["region_east", "sales_manager"],
"citation": {
"page": 12,
"section": "售后分析"
},
"type": "report"
}
]
}
这个差异看起来只是工程细节,实际上决定了RAG能不能往下沉。
因为只有输出被标准化,检索才能被更多Agent、更多应用、更多工具链稳定复用。
三、Agentic RAG里,检索已经变成动态工具
一旦进入Agent阶段,RAG的角色就彻底变了。
它不再只是“开场前查一次资料”,而是Agent在任务执行过程中,随时可以调用的工具。很多人把这个阶段叫Agentic RAG,我觉得这个命名还算贴切,因为这里的重点确实不在“检索增强生成”,而在“检索参与推理闭环”。
动态检索是怎么发生的
看一个常见任务: “帮我分析最近一个季度客户投诉增加的主要原因,并给出处理建议。”
这个任务通常不是一跳完成的。Agent更可能这样工作:
- 先识别任务需要哪些信息
- 检索投诉工单数据摘要
- 检索近期产品变更记录
- 检索客服质检报告
- 发现证据不足,再补充检索区域维度数据
- 基于已有证据做归因
- 输出结论,并附引用
它的链路更像这样:
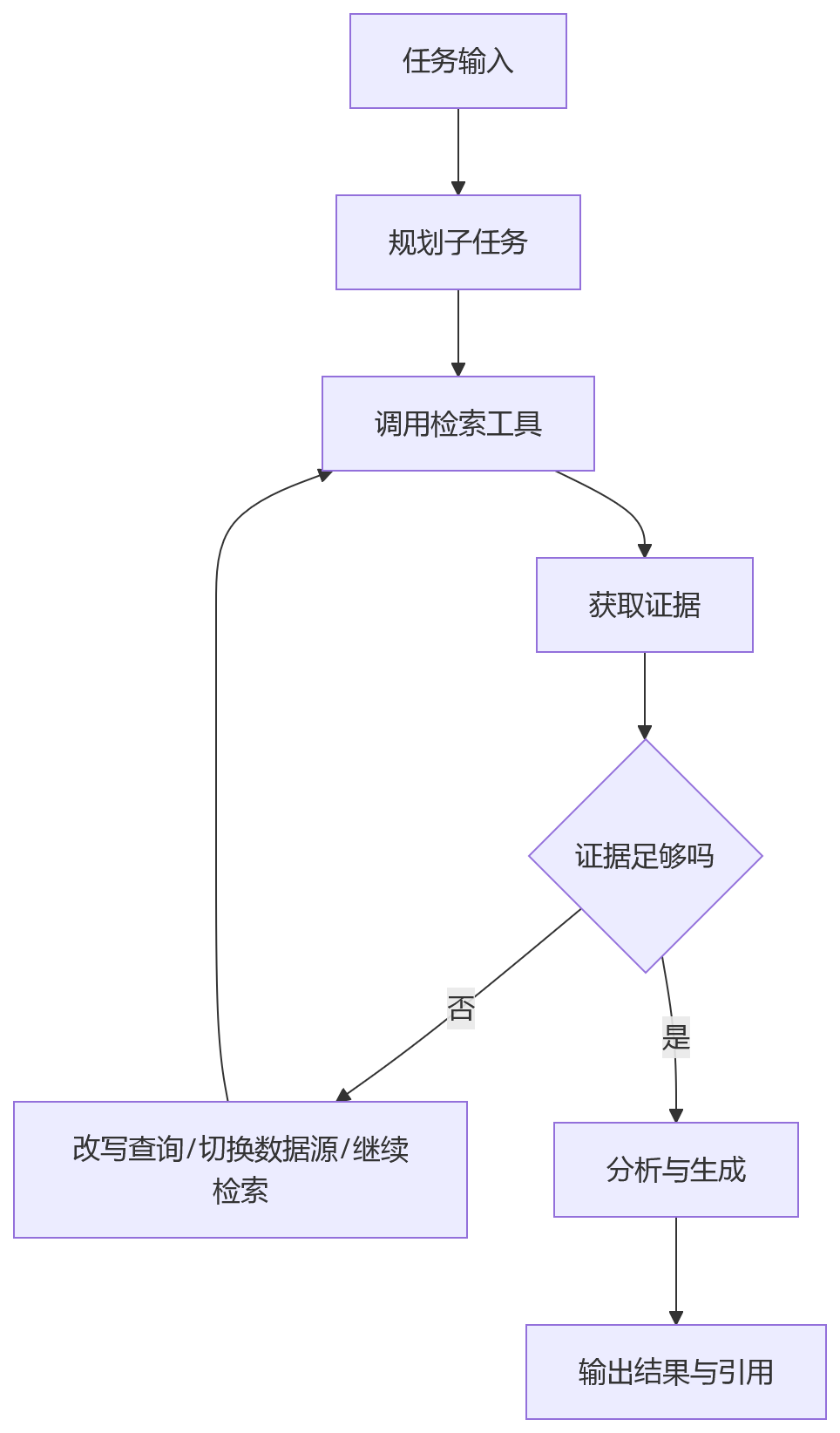
这里有几个很关键的工程变化。
1. Query不再只来自用户输入
在Native RAG里,query大多直接来自用户问题。在Agentic RAG里,query可能来自:
- 用户原始指令
- Agent规划出的子任务
- 上一轮检索结果触发的追问
- 工具执行失败后的重试策略
- 模型中间推理产物
也就是说,检索请求是系统动态生成的,而不是人工直接输入的。
这会直接改变检索层的设计要求。它必须支持更高频、更细粒度、更程序化的调用,而不是只服务一个聊天入口。
2. 检索不再只有一次,而是多轮迭代
这是Agent场景里最容易低估的成本点。
多轮动态检索意味着:
- 请求次数上升
- 结果去重更复杂
- 上下文预算更紧张
- 响应延迟更难控
- 检索缓存价值更高
很多Demo里Agent看上去很聪明,到了生产环境就变慢、变贵、变不稳定,原因往往不是模型不行,而是动态工具调用链条失控了。检索如果要服务Agent,就不能只是“查得到”,还得“查得可控”。
3. 检索策略要能被模型或编排器调用
当检索成为工具,工具接口就必须清晰。
一个过于简单的接口,比如:
{ "query": "xxx" }
在复杂任务里通常不够。更实用的接口会允许Agent传入更多约束:
{
"query": "查询华东区最近30天退货率上升原因",
"sources": ["sales_report", "after_sale_ticket", "product_change_log"],
"time_range": {
"start": "2025-03-01",
"end": "2025-03-30"
},
"filters": {
"region": "east"
},
"top_k": 10,
"need_citation": true
}
这样做的意义,不只是让接口更完整,而是把“检索意图”结构化。 一旦结构化,系统才能做更稳定的路由、融合、缓存和权限控制。
4. Agentic RAG更依赖可观测性
这个问题平时不显眼,一上线就很要命。
因为Agent会多轮调用检索工具,所以你必须知道:
- 它查了什么
- 为什么这么查
- 哪轮检索失败了
- 哪个数据源贡献了有效证据
- 哪次改写把结果带偏了
- 哪些无效调用在浪费token和延迟
没有这一层可观测性,Agentic RAG几乎没法持续调优。
很多团队一开始只关注最终回答是否正确,后面才发现,真正能优化系统的,是中间链路日志:query改写记录、召回分布、rerank结果、证据利用率、引用命中率、失败重试次数。这些指标在应用内RAG里往往是缺失的,但基础设施化之后反而更容易统一建设。
四、为什么RAG大概率会沉淀为共享基础设施
这个趋势背后,不只是技术偏好,而是系统复杂度逼出来的。
复用价值越来越高
当企业里只有一个知识问答机器人时,单独写一套RAG问题不大。 当企业里开始有十几个AI入口时,重复造检索链路就会变得很不划算。
共享基础设施最直接的价值有三层:
- 知识复用:同一份文档、同一个知识源,不需要在多个应用里重复处理
- 能力复用:query改写、混合召回、rerank、引用生成、权限过滤可以复用
- 治理复用:监控、审计、版本、评测体系可以统一
很多基础设施最终能成立,靠的都不是某个点特别炫,而是复用之后边际成本明显下降。RAG也一样。
AI系统会越来越依赖动态外部信息
模型参数再强,也不可能承载所有实时、私有、细粒度、带权限约束的信息。
企业里的高价值问题,往往恰好具备这些特征:
- 信息是私有的
- 信息变化快
- 信息分散在多个系统
- 信息带组织权限
- 信息需要引用和追责
这些问题天然要求一个长期存在的检索层。 从这个角度看,RAG不是Prompt工程的补丁,而是AI系统连接外部知识世界的接口层。
检索能力会从“支持回答”扩展到“支持行动”
这是另一个很重要的变化。
早期RAG主要帮助模型“说得更像那么回事”。 再往后,它更重要的价值是为Agent提供可执行决策的依据。
比如:
- 工单分派前先检索历史处理模式
- 销售建议生成前先检索客户互动记录
- 代码Agent修改前先检索架构约束和变更记录
- 数据分析Agent出报表前先检索指标定义
这里检索服务的就不只是自然语言回答,而是工作流里的判断与动作。 一旦进入这个阶段,RAG就更像数据库访问层、搜索服务层、知识访问网关的混合体,而不是一个聊天功能插件。
五、RAG基础设施化,真正难的地方在哪
趋势很明显,不代表落地简单。
很多团队以为“把向量库独立出来”就算基础设施化了,实际上还差得远。真正在生产环境里,麻烦往往出在下面几个地方。
1. 数据接入不是一次性工程
RAG的基础设施化,前提是知识源持续可用。而企业知识通常分散在:
- 文档系统
- Wiki
- 数据库
- 工单系统
- CRM
- 对象存储
- 邮件或IM沉淀
这些源的结构、权限模型、更新频率都不同。 所以检索层不是只建索引,还要解决增量同步、版本更新、失效清理、格式清洗、元数据抽取。
很多项目卡住,不是模型效果不行,而是数据治理跟不上。
2. 权限控制一定会变成硬问题
这是所有企业级RAG绕不开的现实约束。
检索层一旦共享,就必须处理:
- 用户能看到什么
- Agent代表谁在查
- 跨系统权限怎么映射
- 缓存结果是否会越权复用
- 引用内容是否会暴露敏感字段
权限如果下沉不到检索层,只放在应用层兜底,迟早会出问题。 而权限一旦下沉,索引结构、过滤逻辑、缓存策略都会被影响,这不是后补几个if能搞定的事。
3. 延迟、成本、效果三者很难同时最优
这是典型的工程权衡。
- 检索轮次多,效果可能更好,但延迟和成本上升
- 数据源接得越全,覆盖率更高,但召回噪声更大
- rerank做得越重,结果更准,但吞吐变差
- 上下文塞得越多,证据更全,但token成本和干扰也会增加
所以检索基础设施没有银弹配置。 它更像一组按场景切换的策略集合。
一个比较务实的做法,是按任务等级分层:
| 场景 | 目标 | 检索策略 |
|---|---|---|
| 实时问答 | 低延迟优先 | 轻量召回 + 小top_k + 快速重排 |
| 分析型任务 | 准确率优先 | 多源检索 + 多轮补充 + 引用校验 |
| 自动执行任务 | 稳定性优先 | 强约束过滤 + 结构化结果 + 审计日志 |
这类分层比追求“一套策略打天下”靠谱得多。
4. 评测体系不能只看最终答案
RAG效果评估一直是个老问题。 如果只看用户觉得答案好不好,调优效率会很低,因为中间问题全部被埋掉了。
更实用的评测拆法通常包括:
- 检索命中率
- 引用相关性
- 权限过滤正确率
- 多源融合后的排序质量
- Agent多轮检索成功率
- 最终回答证据覆盖率
只有把检索层单独度量,RAG才真正像基础设施,而不是黑盒外挂。
六、接下来会怎么演进
从现在的方向看,RAG后面大概率会沿着几条线继续下沉。
检索接口标准化
未来不同Agent、不同应用、不同模型编排框架,都需要稳定调用检索服务。这会推动检索接口越来越标准化,包括:
- 统一的query schema
- 标准化结果结构
- 引用与证据格式
- 权限上下文传递
- 多源路由协议
谁先把这层做扎实,谁就更容易把上层应用做快。
从“向量库中心”转向“检索编排中心”
前两年很多讨论都围着向量数据库打转。但再往后,核心壁垒未必在存储本身,而在检索编排能力:
- 如何理解任务意图
- 如何动态选源
- 如何融合多种检索方式
- 如何给Agent提供可消费证据
说得直白一点,向量库重要,但它更像RAG底座里的一个组件,不太像全部答案。
与工作流、记忆、工具系统深度耦合
Agent系统成熟之后,检索层会越来越紧密地连接:
- 长短期记忆
- 工具调用历史
- 工作流状态
- 用户画像
- 实时业务数据
这意味着未来的RAG不会只是“查文档”,而是“按上下文访问整个知识环境”。 到那个时候,把它继续塞在单个应用内部,基本就不现实了。
RAG这波演进,表面上看像是一个技术模块位置的变化:从应用内流程,变成独立服务。真正的变化其实更深一层——AI系统开始需要一个长期存在、可治理、可复用、可审计的知识访问层。
这也是我为什么会判断,RAG注定会继续下沉。
它不会消失,也不会只停留在“检索增强生成”这个名字里。更可能的结果是,大家慢慢不再单独讨论RAG,而是把它当作AI基础设施的一部分,像今天谈缓存、搜索、权限、消息系统那样自然。
等走到那一步,RAG才算真正成熟。








