












































做 AI Agent 落地时,最容易被忽视的往往不是大模型本身的推理能力,而是外部工具调用的可靠性。天气查询是一个典型的“高频、强依赖、低容错”场景,它既需要实时数据,又要求结构稳定。最近针对三款主流的天气 MCP Server 做了深度测试,发现单纯接入协议并不能解决所有问题,真正的难点在于如何在协议层之上设计合理的工程兜底策略。
很多团队在初期会直接让 Agent 去调用 HTTP API,这导致 Prompt 里充斥着鉴权密钥和参数细节,且错误处理完全依赖模型的幻觉修复。引入 MCP(Model Context Protocol)本意是标准化上下文传输,但在实际生产环境中,不同实现的质量差异巨大。有的服务响应极快但元数据缺失,有的结构丰富却频繁超时。要找到一条可行的落地路径,必须从协议特性出发,结合业务约束做二次封装。
一、为什么天气场景是 Agent 的工具试金石
天气数据看似简单,实则对 Agent 架构提出了多维度的挑战。首先是时间敏感性,Agent 获取的是“此刻”还是“过去一小时”的数据,直接影响决策质量。其次是结构化程度,温度、湿度、降水概率这些字段在不同 API 中命名不一,MCP Server 需要将其清洗为统一的资源描述。最后是异常处理,当上游气象服务抖动时,Agent 是直接报错返回,还是降级给出模糊建议?
传统的 Function Calling 模式下,开发者需要在 Prompt 中硬编码参数说明,一旦 API 变更,维护成本极高。而 MCP 将工具定义抽象为独立的服务端点,理论上实现了关注点分离。但在实测中发现,如果 MCP Server 本身没有做好缓存和限流控制,高并发下 Agent 的延迟会从 200ms 飙升到 3s 以上。这种不可预测的延迟在交互型产品中是不可接受的。
真正的问题不在于能不能调用,而在于调用后的数据可信度。我们见过不少案例,Agent 因为无法解析 JSON 格式的降水预报,转而编造一个“大概有雨”的结论。因此,选择 MCP Server 时,不能只看功能列表,更要看它对数据一致性的保障机制。
二、MCP 协议层的实际表现差异
MCP 的核心价值在于统一了资源、提示词和工具的传输通道。但在具体实现上,不同的 Server 对这三者的支持程度完全不同。下图展示了标准 MCP 通信流程与实际落地时的典型链路差异:
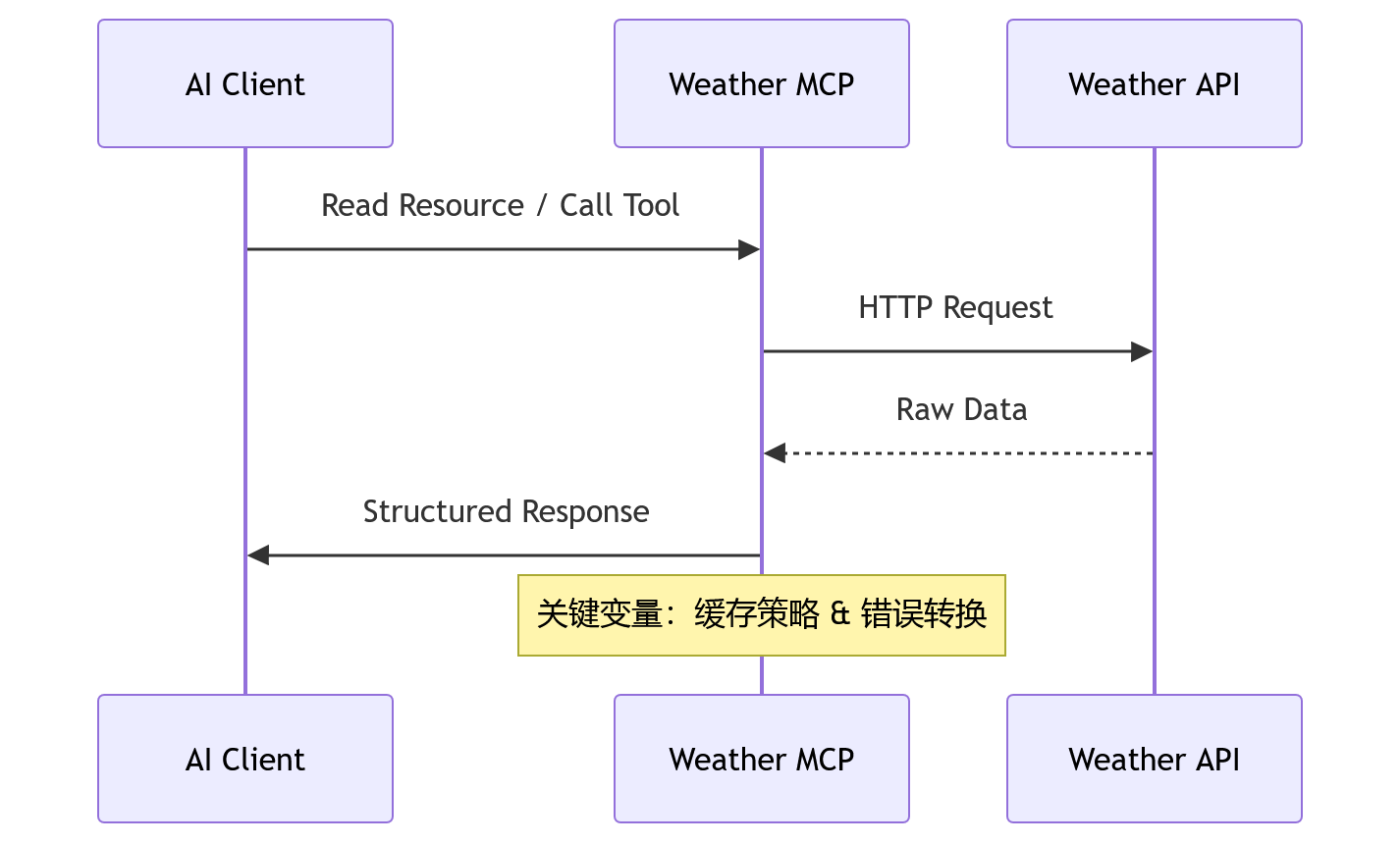
在这次测试中,我们重点关注了三个维度:
- Schema 稳定性:部分 Server 直接透传上游 API 的原始 JSON,导致字段层级过深,增加了 Token 消耗和解析难度。优秀的实现会在 Server 层做一次扁平化映射,只暴露 Agent 需要的核心字段。
- 错误语义化:当上游返回 503 或配额耗尽时,Server 是返回原始 HTTP 状态码,还是转换为 Agent 可理解的文本提示?后者能显著降低 Prompt 退化的风险。
- 连接复用:长轮询或 WebSocket 支持的 Server 在批量查询多城市天气时优势明显,避免每次请求都建立新的 TCP 连接。

上图展示了某款 Server 在压力下的响应分布。可以看到,在第 50 次请求后,由于缺乏本地缓存,延迟曲线出现陡峭上升。这说明即便协议标准统一,后端实现的资源调度策略才是决定体验的关键。
三、工程权衡:自研 Server 还是使用开源方案
选型阶段最常见的纠结是直接使用社区开源的 MCP Server,还是基于官方 SDK 自己写一层。这里没有绝对的最优解,取决于你的业务边界。
如果是通用型的聊天机器人,开源方案足以满足需求,且能快速集成。但对于企业级应用,特别是涉及计费、隐私或特定区域数据的场景,自研 Server 更可控。下表总结了两种方案的适用边界:
| 维度 | 开源/第三方 MCP Server | 自研 MCP Server |
|---|---|---|
| 开发成本 | 低,配置即用 | 高,需维护协议与业务逻辑 |
| 数据控制权 | 弱,依赖上游更新 | 强,可自定义字段与缓存 |
| 故障排查 | 困难,黑盒较多 | 透明,日志完整可追溯 |
| 扩展性 | 受限,受限于作者维护 | 灵活,可随时增加新工具 |
我们的建议是采取“混合模式”。对于标准化的公开数据(如全球主要城市天气),优先对接成熟的开源 Server;对于核心业务数据或需要特殊鉴权的接口,通过自研 Server 进行适配。这样既能利用社区的生态红利,又能保证核心链路的稳定性。
在代码层面,自研 Server 需要特别注意类型安全。虽然 MCP 允许动态传递参数,但最好能在 TypeScript 层定义严格的 Zod Schema,防止传入非法坐标或日期格式。
// 示意代码:严格校验输入参数的 MCP Tool 定义
const weatherTool = {
name: "get_weather", parameters: z.object({
location: z.string().describe("城市名称或经纬度"),
unit: z.enum(["metric", "imperial"]).default("metric")
}),
handler: async ({ args }) => {
// 业务逻辑:先查缓存,再调上游
const cached = await cache.get(args.location);
if (cached) return cached;
const response = await upstream.fetch(args.location);
await cache.set(args.location, response.data);
return response.data;
}
};
四、构建可靠气象能力的最终形态
经过这一轮对比测试,比较清晰的路径浮出水面。MCP 解决了“连通性”问题,但没有解决“可用性”问题。要把气象专家的能力装进 Agent,还需要在协议之上叠加一层工程治理。
第一,强制实施本地缓存策略。对于非实时性要求极高的历史天气或慢变数据,设置合理的 TTL(如 15 分钟),避免重复请求打穿上游。第二,设计友好的降级方案。当 MCP Server 不可用时,Agent 应能识别并切换到备用数据源,或者诚实地告知用户当前数据不可用,而不是生成虚假内容。第三,监控指标前置。不仅监控 Agent 的响应时间,还要监控 MCP 工具调用的成功率,这是发现上游服务波动的最快手段。
技术选型的本质是在不确定性中寻找确定性。MCP 提供了一个很好的基础设施,但最终交付给用户的体验,依然取决于我们对数据流转每一个环节的把控。对于正在规划 Agent 系统的团队,建议先从单一的高频场景入手验证协议稳定性,再逐步扩展到复杂领域。








