近期关于 AI 记忆能力的讨论再次密集出现,各类报道倾向于将“记忆”描述为一种类似人类大脑的黑盒能力。这种叙事在营销层面很有效,但在工程视角下,所谓的"AI 记忆”本质上是不同数据持久化策略的组合。当我们将目光从热点新闻移开,回到系统设计的底层,会发现当前的技术选型依然面临明显的物理约束和成本边界。
很多团队在接入大模型服务时,容易陷入一个误区:认为增加上下文窗口长度就能解决所有记忆问题。实际上,Context Window 只是短期缓存,真正的长期记忆需要外部存储系统的支撑。这两者在延迟、成本和一致性上的表现截然不同,决定了它们适用的业务场景完全不同。
一、上下文窗口与外部存储的本质差异
大模型的上下文窗口常被误读为短期记忆,但它本质上是一个昂贵的线性缓冲区。Token 数量的增加直接导致推理成本的指数级上升,同时也会拉长首字延迟。在生产环境中,超过一定长度的上下文往往会引发注意力分散,导致模型对关键信息的提取能力下降,即所谓的“中间迷失”现象。
相比之下,外部记忆系统通常基于向量数据库或键值存储实现。这种架构将“计算”与“存储”解耦。系统不再依赖模型内部的隐状态来维持对话历史,而是通过检索增强生成(RAG)机制,动态地将相关历史记录注入到当前的 Prompt 中。这种方式虽然引入了额外的检索延迟,但换来了记忆容量的无限扩展和更可控的成本结构。
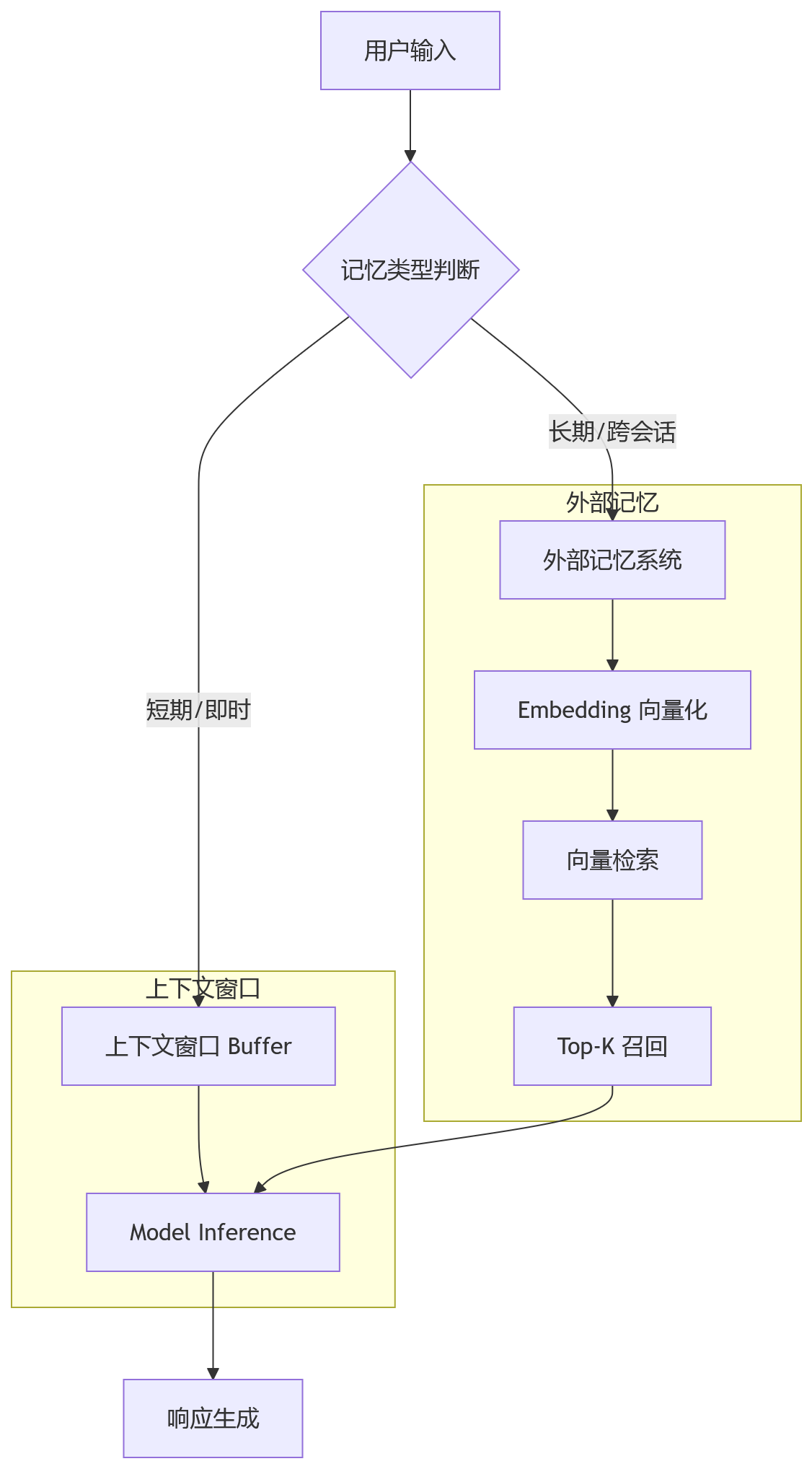
从架构图可以看出,引入外部记忆后,请求链路明显变长。这意味着在追求低延迟的场景下(如实时语音交互),过度依赖外部检索可能会导致体验卡顿。因此,合理的架构设计往往采用混合模式:高频、短期的交互保留在上下文内,低频、重要的知识沉淀到外部库。
二、记忆一致性与状态同步难题
一旦引入外部存储,状态管理就成为了新的瓶颈。多轮对话中,用户可能在不同时间修改同一个事实,或者在不同设备间切换。如何保证记忆的一致性,是工程落地的核心难点。
传统的做法是将所有对话日志存入数据库,但这会导致检索噪音过大。更精细的方案是为每个用户维护独立的记忆图谱,记录实体的属性变化。例如,用户说“我住在上海”,随后又说“我搬家到北京了”。系统需要识别出这是同一实体的属性更新,而不是两条独立的事实。
| 方案 | 一致性控制 | 查询复杂度 | 适用场景 |
|---|---|---|---|
| 全量上下文 | 高(天然顺序) | 低 | 短会话,低并发 |
| 向量检索 | 中(需去重) | 中 | 知识库问答 |
| 关系图谱 | 高(显式关联) | 高 | 复杂任务规划 |
在实际项目中,很多团队为了简化开发,直接选择向量检索方案,忽略了实体消歧的问题。这会导致模型在面对矛盾信息时产生幻觉,或者无法理解用户的意图变更。解决这个问题通常需要引入额外的语义层,对写入的记忆进行结构化清洗,而不仅仅是简单的 Embedding 存储。
三、成本与隐私的工程边界
随着记忆数据的积累,存储成本和检索开销会持续攀升。对于个人助理类应用,每个用户的记忆数据量可能不大,但面对百万级 DAU 时,向量数据库的索引维护成本不容忽视。此外,检索过程本身也需要消耗 Token,间接增加了调用费用。
隐私合规是另一个不可忽视的硬约束。AI 记忆系统存储了大量用户个人信息,这些数据必须具备严格的访问控制和生命周期管理。例如,用户要求“删除我的记忆”,系统不仅要删除向量记录,还要确保在备份和日志中彻底清除痕迹。这在分布式系统中是一个复杂的工程挑战,涉及到数据版本管理和异步清理机制。
目前行业内常见的做法是对敏感信息进行脱敏存储,或者将记忆权限下沉到本地端侧。端侧记忆虽然解决了隐私问题,但受限于设备算力,难以处理复杂的跨模态记忆检索。云端集中式管理则在性能和规模上更有优势,但必须建立完善的信任机制。
四、现实落地的取舍建议
针对不同的业务形态,记忆架构的选择应当有所侧重。如果是客服机器人,重点在于快速检索知识库,可以采用轻量级的 RAG 方案,不必追求长期的个性化记忆。如果是个人智能体,则需要构建完整的用户画像系统,允许一定的延迟以换取更高的准确性。
不要盲目追求“无限记忆”。在大多数 B 端场景下,最近 N 条对话的历史记录已经足够满足 80% 的需求。过度设计记忆模块不仅增加运维负担,还可能因为检索噪声降低回答质量。保持对业务需求的敏感度,比追逐最新的技术名词更重要。
技术演进的节奏往往慢于市场宣传。OpenAI 等厂商的更新确实推动了行业对记忆能力的重视,但底层的架构原理并未发生颠覆性变化。作为工程实践者,关键在于理解这些技术组件的边界,在成本、性能和体验之间找到当前阶段的最优解。