












































最近大模型领域的一个明显趋势是,大家不再满足于让模型“回答问题”,而是希望它“完成任务”。商汤这次发布的 SenseNova-Skills,核心卖点是从凌乱数据到精美 PPT 的直接交付。听起来很美好,但在工程视角下,这实际上是把一个复杂的业务流,强行塞进了一个基于概率生成的系统里。
很多团队在尝试类似功能时,往往会卡在中间环节。比如数据解析错了、逻辑推理断了、或者 PPT 排版乱了。这种端到端的自动化,本质上不是单一模型的突破,而是对传统软件工程与大模型能力的重新组合。我们需要看清这背后的技术账本,才能判断它到底离真正可用还有多远。
一、办公技能的本质是流程编排
所谓的“技能”,在现在的语境下,很少是指模型本身学会了写字或画图,更多是指模型学会了一整套工具的使用顺序。过去我们写脚本处理 Excel,现在是用自然语言触发脚本。但中间的差异在于确定性。代码是确定性的,输入 A 必得输出 B;大模型是非确定性的,输入 A 可能得 B,也可能得 C。
要实现“从数据到 PPT",模型必须完成三个动作:理解意图、调用工具、校验结果。这不仅仅是 Prompt Engineering 能解决的,需要引入 Agent 的规划能力。
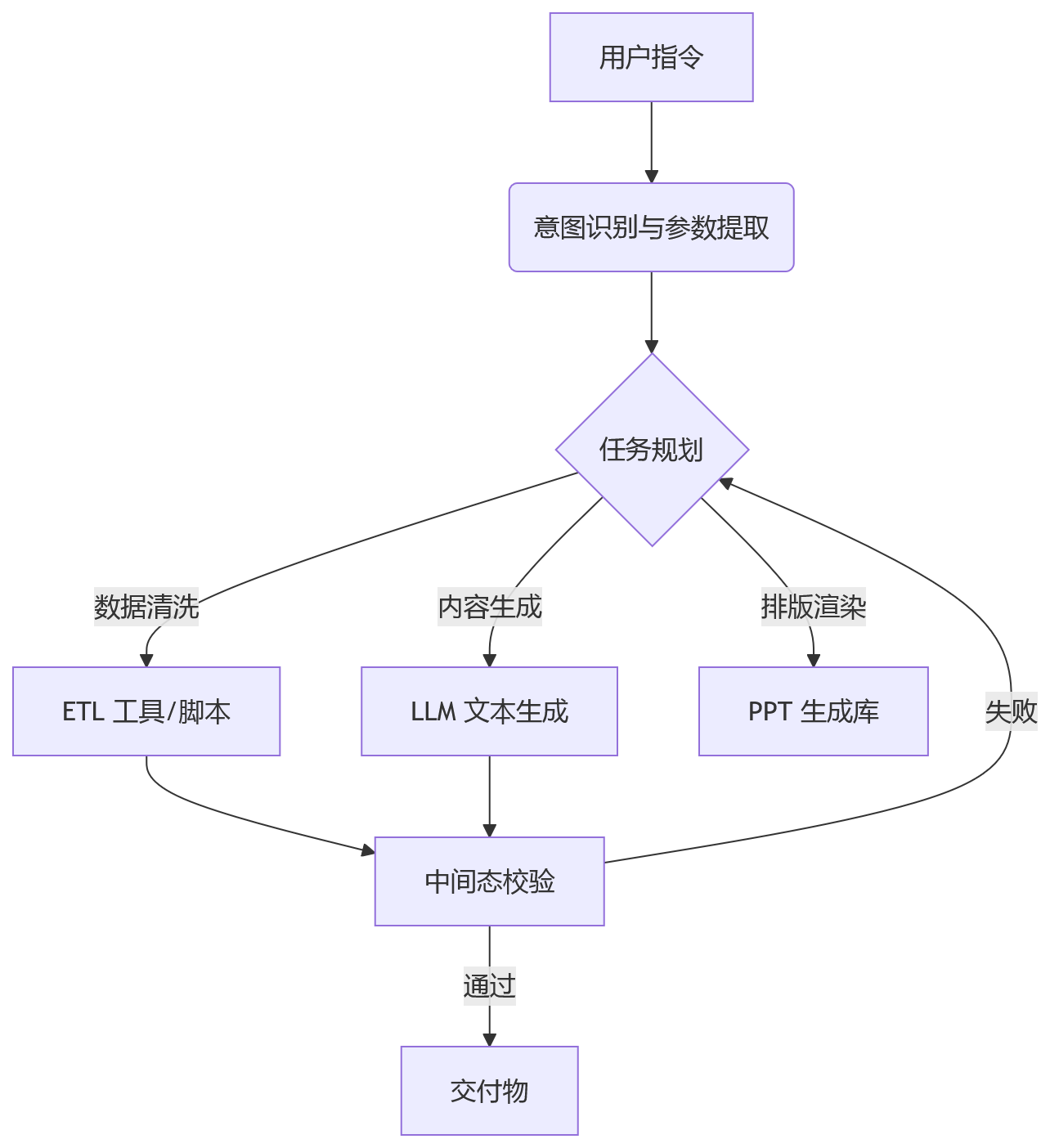
上图展示了一个理想化的闭环。在实际工程中,Validator(校验器)是最容易被忽略的部分。如果模型生成了错误的图表数据,但没有校验机制直接写入 PPT,最终交付的报告就是不可用的。SenseNova 强调的“开源技能集”,大概率包含了这套预设的校验规则和工具链配置,而不仅仅是几个 Prompt。
这里存在一个明显的权衡:灵活性 vs. 可靠性。完全开放给模型去决定每一步怎么做,灵活性高,但容易翻车;把步骤写死成硬编码的工作流,可靠性高,但又失去了 AI 的意义。目前的方案大多是混合模式,关键节点由模型决策,执行节点由代码保障。
二、数据到 PPT 的技术拆解
“从凌乱数据到精美 PPT"这句话里,藏着三个技术难点。
首先是非结构化数据的清洗。用户上传的可能是一个格式混乱的 CSV、一张截图,甚至是几段语音转文字的记录。模型需要先做 OCR 或解析,再对齐字段。这一步的容错率极低,一旦解析错位,后续所有分析都是错的。传统的 ETL 工具在这里依然不可替代,LLM 更多是负责定义映射规则。
其次是分析逻辑的稳定性。模型需要根据数据生成结论。比如销售额下降了,是因为市场原因还是产品原因?模型可能会产生幻觉,编造不存在的因果关系。在办公场景下,这种幻觉是致命的。解决方案通常是限制模型的发挥空间,提供固定的分析模板或 SQL 查询约束,让它只负责填空,不负责创造因果。
最后是文档渲染的标准化。LLM 擅长生成 Markdown 或 JSON,但不擅长控制 PowerPoint 的坐标、字体和母版。这里必须依赖专门的文档生成 SDK。模型输出的应该是结构化的内容描述,而不是直接的二进制文件操作指令。
| 环节 | 传统方式 | LLM 介入点 | 风险点 |
|---|---|---|---|
| 数据接入 | 人工上传/接口同步 | 自动识别文件类型与内容 | 隐私泄露,解析错误 |
| 内容分析 | 固定报表/BI 工具 | 异常检测,归因分析 | 逻辑幻觉,过度解读 |
| 报告生成 | 模板填充 | 文案润色,摘要总结 | 风格不一致,排版错乱 |
可以看到,LLM 真正起作用的环节主要集中在“内容分析”和“文案润色”,而在“数据接入”和“报告生成”上,它更多是作为一个调度器存在。
三、技能封装与行业知识沉淀
商汤提到“开源技能集如何封装行业知识与工作流”,这是企业落地的关键。如果把每个客户的业务逻辑都写成硬代码,维护成本太高;如果全靠 Prompt,每次微调都要重新训练或调整上下文。
比较可行的方式是Code-Defined Workflows(代码定义的工作流)。将通用的业务逻辑(如周报生成、会议纪要整理)抽象成函数或模块,将具体的业务规则(如 KPI 计算公式、汇报语气)配置化。模型负责串联这些模块,并根据当前上下文选择参数。
这种模式下,所谓的“技能”其实是一个可复用的 Docker 镜像或微服务包。它包含:
- 前置依赖:所需的 Python 库、API Key 等。
- 入口函数:接收用户意图,返回标准协议。
- 后处理逻辑:格式化输出,确保符合下游系统要求。
这样做的好处是,即使底层模型升级了,只要接口协议不变,技能本身不需要重写。这对于长期维护的企业级应用至关重要。不过这也带来了门槛,开发者不仅要懂 Prompt,还得懂后端开发和系统集成,这对纯算法团队是个挑战。
四、落地中的现实约束
虽然技术路径看起来清晰,但在生产环境里,麻烦往往出在细节上。
延迟问题是首当其冲的。从上传文件到生成 PPT,如果中间经过多次模型推理和工具调用,耗时可能长达几分钟甚至更久。对于高频办公场景,用户很难接受这种等待。优化方向通常是异步处理,或者在本地部署小模型进行预处理,只有复杂任务才上云。
权限与数据隔离同样棘手。办公数据涉及公司机密,调用第三方 API 或公有云模型存在合规风险。私有化部署是必然趋势,但这又受限于算力成本。如何在有限的显存下跑通这一整套链路,是架构师需要计算的平衡点。
另外,用户预期的管理。目前的大模型还无法做到 100% 准确。如果模型生成的 PPT 有一处数据错误,用户对整个系统的信任度会大幅下降。因此,设计交互时必须保留“人工审核”环节,明确告知用户哪些部分是 AI 生成的,需要确认后才能最终提交。不要试图用 AI 完全替代人,至少在现阶段,它是人的副驾驶,而不是自动驾驶。
五、理性看待技术演进
SenseNova-Skills 的出现,标志着大模型应用正在从玩具走向工具。它解决的不是“能不能做”的问题,而是“怎么规模化做”的问题。
对于技术团队来说,关注点不应仅停留在模型本身的 SOTA 指标上,更要看它在具体业务流中的鲁棒性。真正的竞争力不在于拥有最强的基座模型,而在于谁能更稳定地封装出一套“开箱即用”的工作流,并处理好那些脏活累活的边缘情况。
未来一年,我们会看到更多关于 Agent 协作、长链条任务规划的探索。但对于大多数企业而言,先从单点的效率提升开始,比如让 AI 先帮你写好邮件草稿,再慢慢过渡到自动生成完整报告,可能是更稳妥的路径。技术没有银弹,只有在约束条件下做出的合理选择,才是工程的价值所在。








