












































面对企业级 AI 落地,最直接的冲击往往不是技术选型,而是账单。很多团队在 POC 阶段验证了效果,一旦接入生产环境,Token 消耗就像开了闸的水龙头。Uber 等头部企业在 AI 大规模应用后的成本反思,已经给行业提了个醒:单纯追求模型能力而不关注消耗结构,最终会拖垮业务的 ROI。
这不仅仅是省钱的问题,更是架构设计是否成熟的表现。如果无法清晰地定义 AI 任务的业务边界(即“本体”),就无法准确评估每个 Token 的价值。我们常看到的“成本失控”,本质上是业务流与技术流之间的断层。当开发人员只关心接口是否通畅,而忽略了调用背后的语义密度和冗余度时,成本黑洞就形成了。
要解决 Tokenmaxxing(Token 最大化消耗)困局,不能靠简单的限额策略,那会直接阉杀业务体验。需要从数据透视入手,还原真实的消耗分布,再结合架构手段进行精细化治理。
一、Token 计费的陷阱与价值错位
按 Token 计费是当前的行业标准,但这容易掩盖一个核心问题:Token 数量不等于业务价值。
在生产环境中,经常出现两个极端:一个是高频低价值的重复查询,比如用户反复询问相同的 FAQ;另一个是低频高价值的复杂推理,比如生成一份完整的合规报告。如果仅从总 Token 数看,前者可能占据大头,但后者才是业务的核心收益点。
很多团队在做成本分析时,习惯用“平均单次请求成本”作为指标。这个指标在早期很有用,但在规模放大后会失效。因为随着用户量增长,异常请求、恶意刷单、或者代码逻辑导致的死循环重试,都会把平均值拉偏。
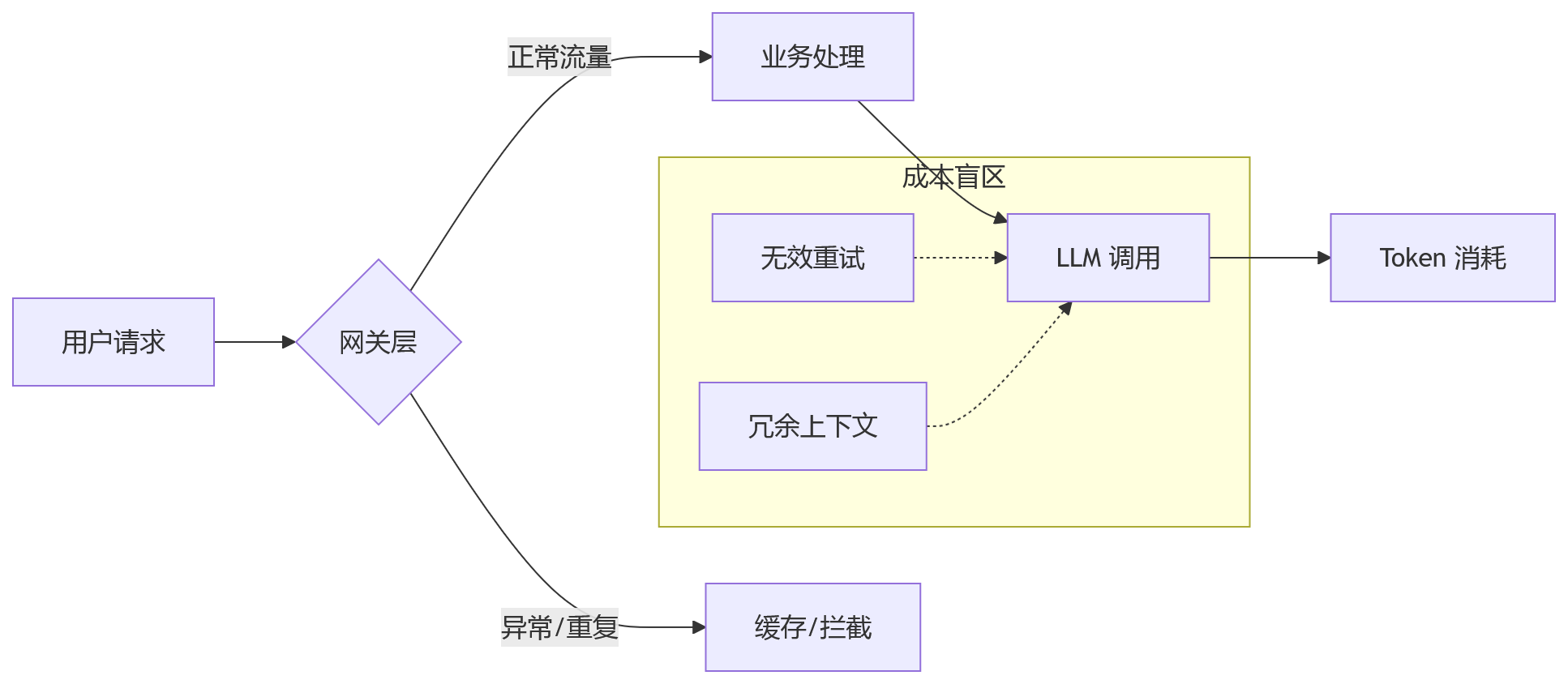
上图展示了典型的调用链路。真正的成本浪费往往隐藏在“成本盲区”里。比如,RAG 检索系统为了追求召回率,将大段无关文档塞入 Prompt,导致输入 Token 激增,但模型实际并未利用这些信息。这种“无效上下文”在很多系统中占比超过 30%。
因此,治理的第一步是打破“总量思维”。我们需要区分“有效计算”和“无效搬运”。如果一个请求消耗了 1000 个 Token,其中 800 个是重复的背景信息,那么它的边际成本极高。这种价值错位,是后续所有优化的起点。
二、构建三维数据透视体系
要摸清家底,必须依赖多源数据的交叉验证。单一维度的日志只能看到表象,结合三类数据源才能还原真实场景。
首先是客户端埋点。这是最接近用户意图的数据。通过记录前端发起的请求参数、等待时间以及用户后续的反馈(如点赞、复制、继续追问),可以判断该次调用的业务闭环是否完成。很多时候,后端显示成功返回了,但用户在对话轮数过多后流失,这意味着之前的 Token 投入是无效的。
其次是服务端链路追踪。这一层关注的是内部流转效率。重点监控是否存在因网络抖动导致的自动重试、微服务间的重复转发、或者缓存未命中引发的二次计算。在分布式系统中,一次用户操作可能触发多个下游 AI 服务并行调用,如果没有全局去重机制,成本会成倍增加。
最后是厂商侧计量数据。这部分来自云厂商或模型提供商的 API 账单。它是最准确的财务数据,但颗粒度通常较粗。需要将前两层的技术指标(如 TraceID)与厂商账单的 RequestID 进行关联映射。
| 数据维度 | 核心价值 | 常见盲区 |
|---|---|---|
| 客户端埋点 | 用户意图与满意度 | 无法感知后端具体拆分逻辑 |
| 服务端链路 | 内部流转与重试机制 | 难以关联最终财务账单 |
| 厂商计量 | 真实财务支出 | 缺乏业务语义标签 |
这三类数据打通后,能形成一个完整的归因链条。例如,某日成本突增,通过厂商账单定位到是某个特定模型,再通过服务端链路发现是某个新上线的微服务开启了调试模式,最后通过客户端日志确认该服务未被用户主动触发。这种排查效率远高于单纯的查看账单峰值。
三、架构层面的治理策略
有了数据支撑,接下来就是工程上的收敛。治理 Token 成本不是让开发少写代码,而是调整架构的杠杆。
1. 智能路由与降级
不是所有问题都需要大模型来解决。在架构中引入一层“意图识别路由”,根据问题的复杂度选择模型。简单的分类、提取任务可以用小参数模型甚至传统规则引擎处理,只有涉及复杂推理时才调用主力大模型。
这需要维护一套“任务本体库”。将常见的业务场景定义为标准任务类型(如:总结、翻译、创作、问答)。每个任务类型绑定推荐模型和最大 Token 限制。这样做虽然增加了维护成本,但能从源头控制算力浪费。
2. 语义缓存机制
传统的 HTTP 缓存基于 URL 或参数哈希,对于 AI 场景往往失效。因为同样的语义可能有多种表达方式(“怎么退款”vs“我想退钱”)。
需要引入向量数据库构建语义缓存。在请求进入模型前,先计算 Query 的 Embedding,在向量库中检索相似度极高的历史回答。如果匹配度超过阈值(如 0.95),直接返回缓存结果。
# 示意代码:语义缓存检查流程
async def process_request(user_query):
embedding = await embed_model.encode(user_query)
cached_hit = vector_store.search(embedding, threshold=0.95)
if cached_hit:
# 节省 Token,直接返回历史最优解
return cached_hit.response
# 无缓存,执行完整 LLM 流程
response = await llm.generate(user_query)
vector_store.store(embedding, response)
return response
这里的 Trade-off 很明显:引入了向量检索延迟和存储成本,换取了高昂的 LLM Token 费用节省。在高频重复场景下,ROI 通常是正的。
3. Prompt 模板工程化
Prompt 不应散落在各个业务代码中。应该像管理 SQL 一样管理 Prompt,建立版本控制和测试机制。很多成本浪费源于 Prompt 中的冗余指令。例如,在 System Prompt 中反复强调“你是一个助手”,每次调用都携带这段文本,累积下来非常可观。
将通用指令抽离为静态配置,动态部分仅传入变量。同时,定期使用自动化脚本对 Prompt 进行“瘦身”测试,对比不同长度下的输出质量,找到那个性价比最高的临界点。
四、结语
Token 成本治理不是一个一次性项目,而是一个持续演进的过程。它要求技术团队从“功能交付者”转变为“资源经营者”。
所谓的“本体论”视角,在这里意味着我们要重新定义 AI 任务的本质——它不是一段黑盒代码,而是一系列可度量、可拆解、可优化的业务动作。当你能清晰地说出每一个 Token 对应哪一步业务价值时,成本控制自然就有了抓手。
未来的竞争不仅是模型能力的竞争,更是工程效率的竞争。谁能以更少的 Token 达成同样的业务目标,谁就能在 AI 时代获得更长的生存空间。








