很多团队做 RAG,第一阶段通常很顺:接一个大模型,切文档,做 embedding,塞进向量库,再拼一个检索增强的 prompt,Demo 很快就能跑起来。
真正麻烦的是上线之后。用户问法变了,文档持续更新,embedding 模型要不要换,chunk 切得是否合理,召回结果为什么突然变差,业务方反馈“有时候答得挺好,有时候像没读过知识库”。这些问题靠一次性调参解决不了。
RAG 的运维,本质上要从“搭系统”转向“养系统”。Loop Engineering 的价值也在这里:把检索、生成、反馈、评估、优化做成持续闭环,而不是每次出问题都靠人肉排查。
一、RAG 运维的难点在检索之后
很多人一开始会把 RAG 的问题归因到大模型。
回答不准,换模型。 回答不完整,加 prompt。 回答幻觉,调 temperature。
这些手段有用,但经常治标不治本。生产环境里的 RAG 问题,很多发生在更前面的链路:
文档采集 -> 清洗 -> 切分 -> 向量化 -> 入库 -> 检索 -> 重排 -> 生成 -> 反馈
任何一段出问题,最后都会表现成“模型回答不好”。
比如:
- 文档清洗阶段把表格结构打散了,模型拿到的上下文天然缺信息;
- chunk 切得太碎,召回片段缺少上下文;
- chunk 切得太大,召回命中但有效信息密度低;
- embedding 模型对业务术语不敏感,同义表达召回不回来;
- 只做向量召回,关键词、编号、型号这类精确匹配场景会吃亏;
- metadata 没设计好,权限、时间、产品线过滤只能在应用层硬补;
- 知识库更新后没有可追踪版本,线上效果波动无法复盘。
这也是 RAG 运维比传统搜索系统更难的地方。传统搜索通常有比较成熟的查询日志、点击反馈、排序指标和相关性评估体系。RAG 把搜索、推荐、NLP、生成式模型揉在了一起,链路更长,不确定性也更强。
所以,RAG 系统不能只盯着一次请求的最终答案,而要能拆开看:到底是没召回、召回了没排上、排上了没被模型用好,还是模型自己发挥过头了。
二、Loop Engineering 要解决闭环问题
Loop Engineering 可以理解为面向 AI 系统的闭环工程方法。
它关注的不是某一个模型调用,也不是某一个 prompt 技巧,而是把系统运行过程中的数据持续收回来,用评估和观测定位问题,再把优化结果重新投放到生产链路中。
一个典型的 RAG Loop 大概长这样:

这个闭环里面,最关键的不是“自动优化”四个字,而是可观测、可评估、可回滚。
很多团队做到这里会卡住。因为他们有日志,但日志不能回答问题;有反馈,但反馈无法映射到具体链路;有评估集,但评估集和线上真实问题脱节。
比较靠谱的做法,是把 RAG 的运维指标拆到几个层次。
| 层次 | 关注点 | 常见指标 |
|---|---|---|
| 检索层 | 有没有找到相关知识 | Recall@K、Hit Rate、MRR |
| 排序层 | 相关内容是否排在前面 | NDCG、Top1/Top3 命中 |
| 上下文层 | 模型拿到的信息是否可用 | 上下文覆盖率、冗余率、token 成本 |
| 生成层 | 答案是否忠实、完整 | Faithfulness、Answer Relevance |
| 业务层 | 用户是否解决问题 | 采纳率、追问率、人工转接率 |
这里有一个工程判断:RAG 运维不要一开始就追求指标体系完美。更现实的路径是先抓住“问题可定位”。
比如用户反馈答案不准,至少要能还原:
- 当时 query 是什么;
- 命中了哪些 chunk;
- 每个 chunk 的相似度是多少;
- 有没有 metadata 过滤;
- reranker 排序结果如何;
- 最终拼给模型的上下文是什么;
- 模型回答引用了哪些片段;
- 知识库版本和 embedding 模型版本是什么。
没有这些信息,所谓调优基本靠感觉。靠感觉能救一两次火,但很难支撑长期运维。
三、RAG Loop 的核心变量
RAG 的效果优化经常被讲得很玄,其实大部分问题绕不开几个变量。
文档切分
chunk 是 RAG 里最容易被低估的设计点。
切分策略决定了检索单元,也决定了模型最终能看到的信息结构。按固定字符数切最简单,但对技术文档、合同、FAQ、代码文档、产品手册来说,效果经常不稳定。
更工程化的切分会考虑:
- 标题层级;
- 段落语义完整性;
- 表格和列表结构;
- 代码块边界;
- FAQ 问答对;
- 业务对象,比如订单、设备、接口、告警项。
这里没有统一最优解。FAQ 知识库适合短 chunk,产品手册可能需要层级 chunk,合同和政策文件常常需要保留章节关系。为了省 token 把上下文切得太碎,最后可能在召回阶段省了钱,在生成阶段付出幻觉成本。
检索策略
单纯向量检索擅长语义相似,但对精确匹配并不总是友好。
比如用户问:
Milvus 3.0 是否支持某个具体参数?
错误码 E1024 怎么处理?
SKU-AX19 的保修政策是什么?
这类问题里,编号、错误码、参数名、产品型号非常关键。只靠 dense embedding,可能把“语义接近”的内容排上来,却漏掉精确项。
所以生产里的 RAG 通常会走混合检索:
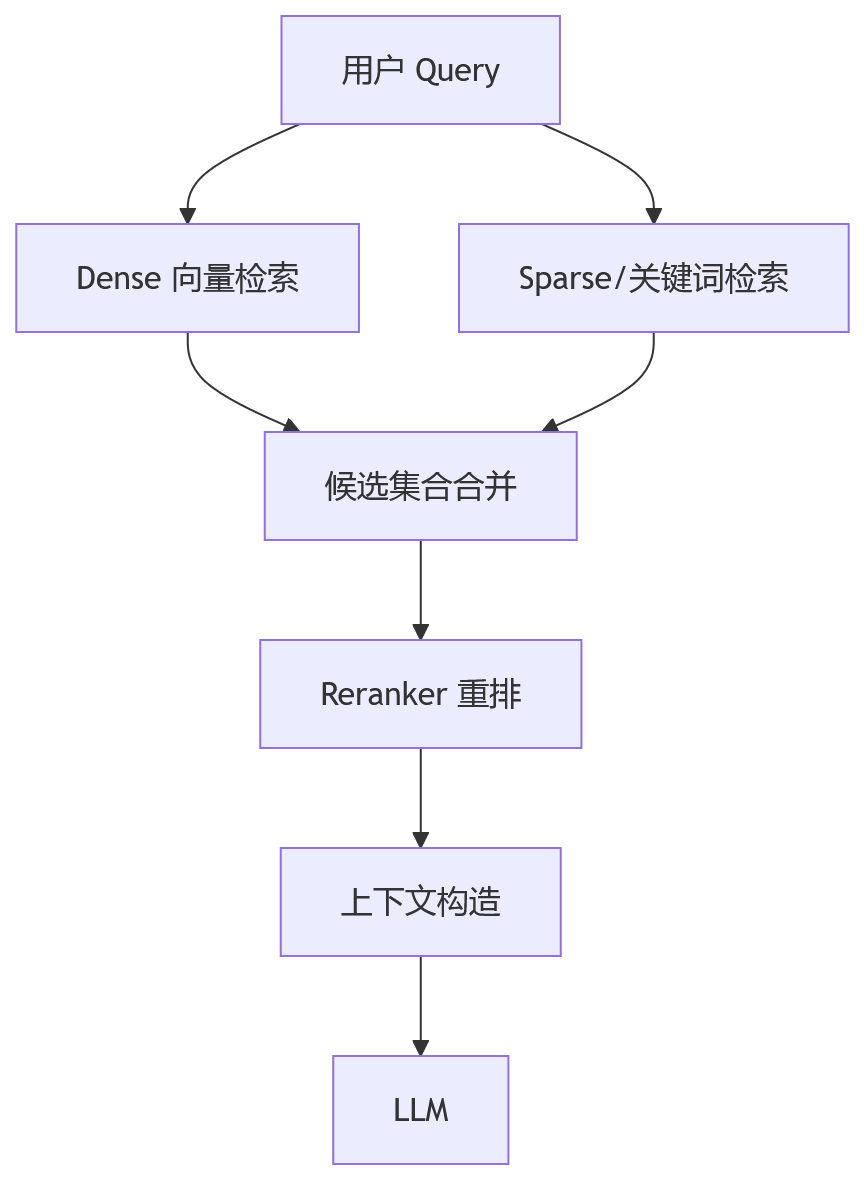
混合检索的代价也很明确:链路更复杂,参数更多,评估成本更高。但在企业知识库、客服、技术支持、法务合规这些场景里,这个复杂度通常是值得的。
Metadata 与权限
很多 RAG 系统 Demo 阶段不重视 metadata,上线后会补得很痛苦。
真实业务里,知识并不是一堆无差别文本。它有:
- 部门;
- 产品线;
- 版本;
- 发布时间;
- 地域;
- 用户权限;
- 有效期;
- 文档类型;
- 可信等级。
如果这些信息没有进入向量库的过滤条件,应用层就会变成一坨 if-else。更麻烦的是,召回结果可能已经混入了不该出现的内容,后面再过滤会影响召回质量和排序稳定性。
权限过滤尤其要前置。RAG 系统一旦把不该看的知识拼进 prompt,即使模型最后没说出来,风险也已经发生了。
四、Milvus 3.0 的价值在数据底座
Milvus 对 RAG 的价值,不应该只理解成“存向量”。
如果 RAG 是一个持续运转的知识系统,向量数据库承担的是 AI 数据底座的角色:承接高维向量、标量字段、索引、过滤、更新、扩缩容、查询延迟和数据治理。
Milvus 3.0 对 Loop Engineering 的价值,可以放在三个层面看。
第一,支撑混合检索
RAG 从 Demo 走向生产,检索策略大概率会从单一向量召回演进到混合检索。
Dense 向量负责语义相似,Sparse/全文能力负责关键词、术语、编号、实体匹配,metadata filter 负责业务约束。检索系统能不能把这些能力放在一条稳定链路里,直接影响调优效率。
工程上比较理想的检索形态是:
向量相似度 稀疏检索 标量过滤 重排
Milvus 这类向量数据库如果能把 dense vector、sparse vector、标量字段、过滤表达式放在统一查询模型下,RAG 运维会轻很多。
否则就会变成:
- Elasticsearch 做关键词;
- 向量库做语义召回;
- 应用层合并结果;
- 再接 reranker;
- 还要自己处理分页、去重、过滤、权重融合。
这个方案不是不能做,大厂或者搜索团队当然能扛住。但对大多数业务团队来说,系统复杂度会很快超过收益。尤其当知识库规模、租户数量、权限条件上来之后,维护成本会持续放大。
第二,承接持续更新
RAG 知识库不是一次性导入完就结束。
文档会新增、下线、修订,embedding 模型会升级,chunk 策略会调整,业务分类也会变化。Loop Engineering 要求系统能持续实验和回滚,这对底层数据管理提出了要求。
一个比较健康的设计,是在数据层面保留版本意识:
doc_id
chunk_id
content_hash
chunk_version
embedding_model
embedding_version
source_uri
created_at
updated_at
tenant_id
visibility
这些字段看起来啰嗦,但生产排查时很有用。
比如某天客服 RAG 的命中率下降,需要判断:
- 是新文档质量差;
- 是旧文档被覆盖;
- 是 embedding 模型升级导致分布变化;
- 是 chunk 策略变化;
- 是索引参数调整;
- 还是 query 分布变了。
没有版本字段,排查就像翻垃圾桶。能不能把向量、文本片段、元信息、版本信息稳定组织起来,是向量数据库在 RAG 运维里的基础价值。
第三,保证规模化后的稳定性
RAG 小规模时,很多问题可以靠应用层兜底。数据量上来之后,数据库能力会成为硬约束。
典型压力包括:
- 百万到十亿级 chunk;
- 多租户隔离;
- 高频增量写入;
- 低延迟检索;
- metadata 复杂过滤;
- 热点知识访问;
- 批量重建索引;
- embedding 模型迁移;
- 历史版本回滚。
这里的 trade-off 很现实。
如果团队选择轻量向量库或者直接把向量塞进关系型数据库,早期开发效率高,运维简单,成本也低。但当数据规模、查询并发、过滤复杂度上来后,索引性能和可扩展性会成为瓶颈。
如果一开始就上分布式向量数据库,系统复杂度、资源成本、运维要求都会增加。对于只有几万条文档的小系统,这可能显得重。
所以判断标准不是“哪个技术更先进”,而是:
- 数据规模是否会持续增长;
- 查询延迟是否敏感;
- 是否有多租户和权限过滤;
- 是否需要混合检索;
- 是否会频繁重建 embedding;
- 是否需要长期做评估和回滚。
满足其中三四项,Milvus 这类专用向量数据库的价值就比较明确了。
五、Loop Engineering 怎么落地
RAG 运维闭环不要一上来做得太大。比较可控的路径,是先建立最小闭环。
1. 记录可复盘日志
每次请求至少保留:
{
"query": "用户原始问题",
"query_embedding_model": "text-embedding-xxx",
"retrieved_chunks": [
{
"chunk_id": "doc1_chunk8",
"score": 0.82,
"doc_id": "doc1",
"chunk_version": "v3",
"metadata": {
"product": "milvus",
"version": "3.0"
}
}
],
"rerank_results": [
{
"chunk_id": "doc1_chunk8",
"rerank_score": 0.91
}
],
"prompt_context_ids": ["doc1_chunk8", "doc2_chunk3"],
"answer": "模型最终回答",
"feedback": "good_or_bad",
"created_at": "2025-xx-xx"
}
这不是为了存一堆日志好看,而是为了能回答“为什么这次答错”。
2. 建立小而稳定的评估集
评估集不需要一开始上千条。几十到几百条高质量问题,往往就能暴露主要问题。
评估集应该来自真实场景:
- 高频用户问题;
- 失败案例;
- 业务方标注的关键问题;
- 容易混淆的问题;
- 有权限边界的问题;
- 有时效性的问题。
每次调整 chunk、embedding、索引、检索参数、reranker,都跑一遍评估集。哪怕评估不完全自动化,也比靠主观体验靠谱得多。
3. 把调优动作分层
RAG 调优最怕乱调。
今天改 prompt,明天换 embedding,后天调 topK,再后来改 chunk。最后效果变了,但没人知道是哪一步带来的。
更稳的方式是分层实验:
| 调优层 | 动作 | 风险 |
|---|---|---|
| 数据层 | 清洗、去重、补 metadata | 中低 |
| 切分层 | 调整 chunk size、overlap、结构化切分 | 中 |
| 检索层 | topK、索引参数、混合检索权重 | 中 |
| 排序层 | 接入 reranker、调整阈值 | 中高 |
| 生成层 | prompt、引用格式、拒答策略 | 中 |
| 模型层 | embedding/LLM 替换 | 高 |
embedding 模型替换通常风险最大,因为它会影响整个向量空间。除非有明确评估和灰度机制,否则不要把它当成普通配置项随手改。
4. 做灰度和回滚
RAG 的改动一定要有回滚能力。
比较实用的方式是多集合或多版本并行:
collection_v1: 当前线上版本
collection_v2: 新 chunk 策略 新 embedding
线上流量按比例切到 v2,对比检索指标和业务反馈。效果稳定后再扩大流量。
如果底层向量库支持更好的集合管理、别名切换、分区管理和元数据过滤,这类灰度会更顺。Milvus 在这里的价值不是替你判断哪个版本更好,而是提供可承载实验的基础设施。
六、Milvus 3.0 适合放在哪一层
在 RAG 架构里,Milvus 3.0 不应该承担所有事情。
它适合做:
- 向量与混合检索底座;
- 知识片段和元信息管理;
- 多租户或多业务线的数据隔离;
- 大规模相似度搜索;
- 过滤条件下的检索;
- 检索实验版本承载;
- RAG 评估闭环中的召回侧基础设施。
它不适合替代:
- 文档解析系统;
- 权限主数据系统;
- 评估平台;
- prompt 管理平台;
- LLM 网关;
- 业务反馈系统。
这个边界要讲清楚。很多 RAG 架构出问题,是因为把一个组件想象成全能平台。向量数据库再强,也解决不了脏数据、坏切分、错误权限模型和缺失评估集。
比较合理的架构关系大概是:
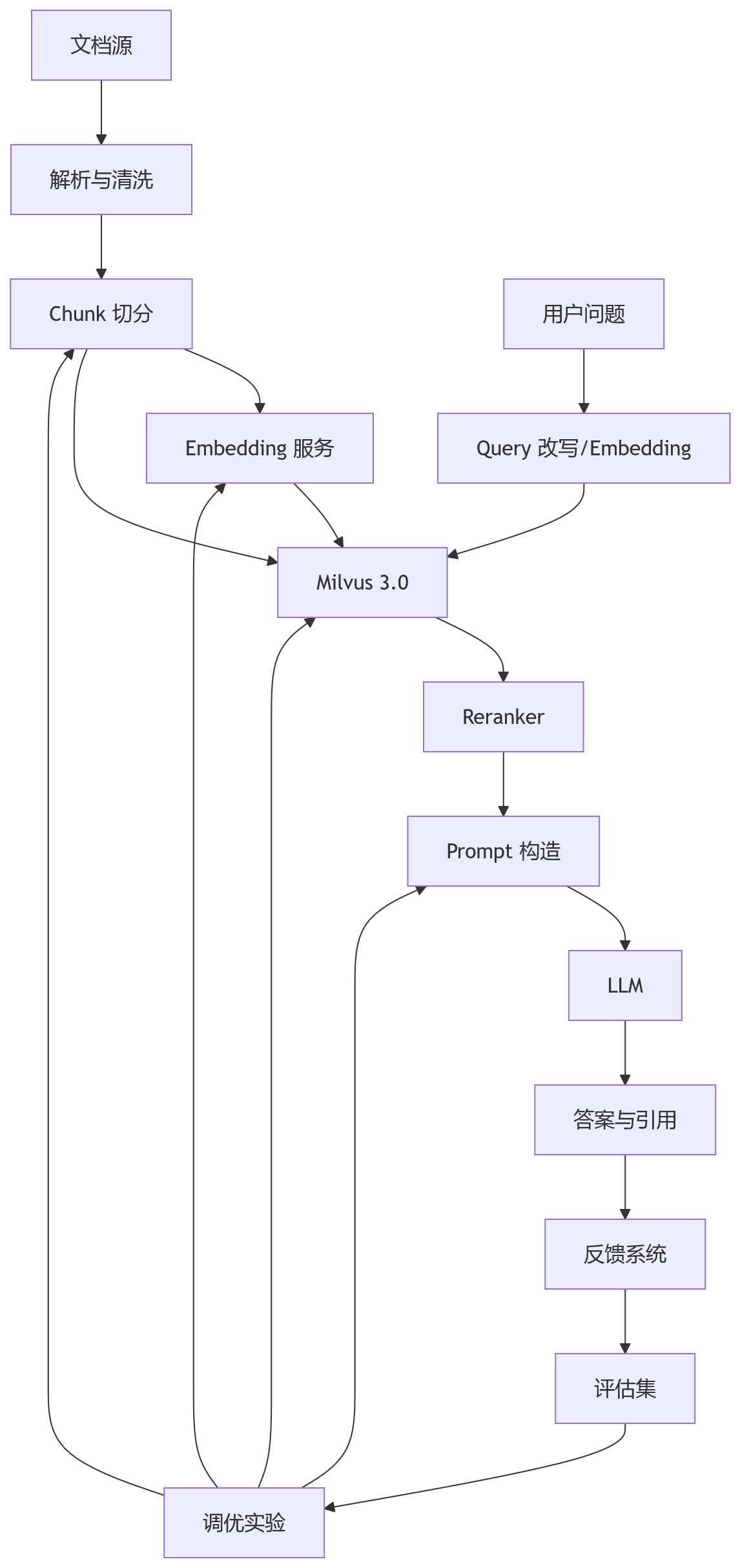
Milvus 位于检索数据层,向上服务 RAG 编排,向下承接索引和存储。Loop Engineering 要跑起来,Milvus 要和日志、评估、实验、反馈系统一起工作。
七、几个容易踩的坑
只看向量相似度
相似度高不等于答案可用。
有些 chunk 语义很接近,但缺关键字段;有些 chunk 分数不高,却包含唯一正确答案。尤其在技术文档和客服知识库里,精确词、版本号、错误码经常比语义相似更重要。
所以线上 RAG 很少只靠一个相似度分数做最终判断。混合检索、reranker、metadata filter 都是为了解这个问题。
topK 越大越好
topK 调大能提高召回概率,但也会引入噪声和 token 成本。
模型上下文不是垃圾桶。塞得越多,模型越可能被无关片段干扰。工程上更常见的做法是:召回阶段多拿一些候选,重排后再控制进入 prompt 的内容。
忽略拒答策略
RAG 系统不应该每个问题都硬答。
当检索结果分数低、候选片段冲突、权限不足、知识过期时,系统应该有拒答或转人工策略。否则模型会用看似合理的话把问题糊过去,用户短期可能没发现,长期会损害信任。
没有知识版本
知识库一旦持续更新,版本就是生命线。
没有版本,评估结果不可复现;没有版本,线上回滚困难;没有版本,业务方问“为什么昨天能答今天不能答”,技术团队只能沉默。
八、真正的价值是可持续优化
RAG 早期拼的是集成速度,上线之后拼的是工程闭环。
Loop Engineering 让 RAG 从一次性方案变成可持续优化的系统。它要求团队把日志、评估、反馈、实验、回滚这些看起来“不性感”的东西补齐。说实话,这些工作没有换大模型那么容易出效果,但它们决定了系统能不能长期稳定。
Milvus 3.0 的价值,也要放在这个闭环里看。它不是让 RAG 自动变聪明的银弹,但能把向量检索、混合检索、元数据过滤、规模化存储和版本实验这些底层能力托住。
如果只是做一个几千条文档的内部助手,轻量方案也许足够。 如果目标是企业级知识系统、多业务线接入、持续更新、可评估可回滚,那么向量数据库就不只是存储组件,而是 RAG 运维闭环的基础设施。
RAG 的后半场,大概率不会只属于 prompt 写得最花的人,而属于能把数据、检索、评估和运维闭环做扎实的团队。[DONE]