












































很多人第一次用 Claude Code,感受到的是“交互效率”的提升:少切窗口、少翻文档、少写样板代码。这个阶段它更像一个坐在旁边的 Pair Programmer,能力强,但工作方式仍然是串行的。
串行有个很现实的天花板。一个 Agent 一次只能沿着一条上下文线推进。它可以理解复杂代码,可以修改多个文件,也可以跑测试,但当任务天然可以拆分时,比如批量迁移接口、并行分析多个模块、同时做安全审计和性能检查,单 Agent 就会开始显得慢。
Claude Code 的多 Agent 和 Headless 模式,真正有意思的地方不在“AI 更聪明了”,而在它开始接近工程系统里的两个。
一、单 Agent 的瓶颈
把一个 50 个文件的模块从 REST 迁移到 GraphQL,听起来像一个任务,但工程上通常不是一条直线。
它可能至少包含几类工作:
- 扫描已有接口和调用方
- 设计 GraphQL schema
- 修改服务端 resolver
- 调整前端调用层
- 补测试
- 清理旧 REST 入口
- 检查鉴权、缓存、错误处理是否一致
如果交给一个 Agent,它会在同一个上下文里做规划、读文件、改代码、跑测试、再修复。这个过程最大的问题不是 Claude 不会做,而是上下文和执行链路都被压在一条线上。
这会带来几个典型问题:
- 等待时间长即使任务之间没有强依赖,也只能排队执行。
- 上下文容易膨胀大任务推进到后半段,前面的决策、文件内容、错误日志都会挤在同一个上下文里。
- 失败影响面大中间某一步方向跑偏,后续修改可能都跟着偏。
- Review 压力不一定降低 一次性产出一大坨改动,人类 Review 反而更痛苦。
并行 Agent 的价值,就在于把这类任务拆成多个相对独立的执行单元。它不是让一个 Agent 更努力,而是让多个 Agent 在隔离环境里各自推进,最后再汇总结果。
这里的关键不是“多开几个 AI”,而是隔离级别、任务粒度、合并策略这三件事。
二、四种并行模式
Claude Code 里常见的并行方式,大致可以分成四类。它们看起来都叫 Agent,但工程语义并不一样。
| 方式 | 隔离级别 | 适用场景 | 复杂度 | 主要风险 |
|---|---|---|---|---|
| Subagents | 同一会话内 | 搜索日志、辅助分析、并行调研 | 低 | 上下文边界不够硬 |
| Agent View | 独立后台会话 | 同时处理多个独立任务 | 中 | 任务状态管理成本上升 |
| Agent Teams | 独立 Worktree | 大规模重构、团队式协作 | 高 | Token 成本和合并冲突 |
/batch Skill |
独立 Worktree 独立 PR | 批量修改、批量迁移 | 中 | 子任务切分质量决定效果 |
更直观一点:
- Subagents 像助理:帮你查资料、扫代码、做局部判断。
- Agent View 像分身:多个独立任务同时跑。
- Agent Teams 像小团队:有规划者,有执行者,适合大任务拆解。
/batch像流水线:把一批类似任务拆出去,各自生成结果。
这几个模式没有绝对高低。很多团队容易犯的错误,是一上来就想用最强的 Agent Teams。实际落地时,轻量任务用 Subagents,批量机械迁移用 /batch,复杂重构才考虑 Agent Teams,往往更稳。
并行不是免费的。并行带来的吞吐提升,通常要用三样东西交换:
- 更多 Token
- 更多中间产物
- 更多合并和校验成本
这和传统工程里的多线程很像。线程不是越多越好,任务划分不合理,锁竞争和上下文切换会把收益吃掉。Agent 并行也一样。
三、Subagents 的真实价值
Subagents 是最轻量的一类。它适合放在主会话旁边,处理那些“有用,但不值得打断主线”的工作。
比如你正在修一个支付模块的 Bug,主 Agent 聚焦在复现和修复。这时可以派 Subagent 去做几件事:
- 搜索最近相关提交
- 查找类似错误日志
- 扫描是否存在同类代码模式
- 对某个目录做安全检查
- 汇总测试覆盖薄弱点
这类任务的共同点是:读多写少,分析为主,产出结果给主线参考。
自定义 Subagent 通常可以放在 .claude/agents/ 目录下,用 Markdown 描述它的职责。比如一个安全审计 Agent:
# Security Auditor
你是一个安全审计专家。检查代码时重点关注:
- SQL 注入风险
- XSS 漏洞
- 硬编码的密钥和凭证
- 不安全的依赖版本
- 权限绕过和鉴权缺失
输出格式:
按严重程度分为 Critical / High / Medium / Low。
每项需要包含:
- 文件路径
- 问题描述
- 触发条件
- 修复建议
这个配置看起来简单,但里面有两个工程细节值得注意。
第一,职责要窄。 “帮我检查代码质量”这种 Agent 很容易输出泛泛而谈的建议。安全审计、依赖风险、日志异常、SQL 使用模式,这类边界清晰的角色更稳定。
第二,输出格式要硬。 如果 Subagent 的输出最终要进入后续流程,比如生成 Issue、阻断 CI、进入审计报告,就不能只写“请给我一些建议”。你需要明确字段、严重级别、文件路径和修复建议。
Subagents 比较适合下面这些场景:
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 查找某类代码模式 | 适合 | 读操作为主,结果可汇总 |
| 安全审计初筛 | 适合 | 可以按规则和风险维度扫描 |
| 大型重构执行 | 不太适合 | 隔离不足,容易干扰主线 |
| 自动修改多个模块 | 谨慎 | 缺少强隔离,回滚和合并不够清晰 |
| 日志根因分析 | 适合 | 可以并行分析不同日志片段 |
很多时候,Subagents 的价值不在于替你写代码,而在于减少你在主会话里来回切任务的次数。主线保持专注,支线交给助理,这是更健康的使用方式。
四、Agent Teams 的工程边界
Agent Teams 更像一套 AI 协作机制。它的思路是让一个 Team Lead 负责拆任务和协调,多个 Teammate 在独立 Git Worktree 中执行具体修改。
启用方式通常类似:
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
claude
它的典型流程可以抽象成这样:
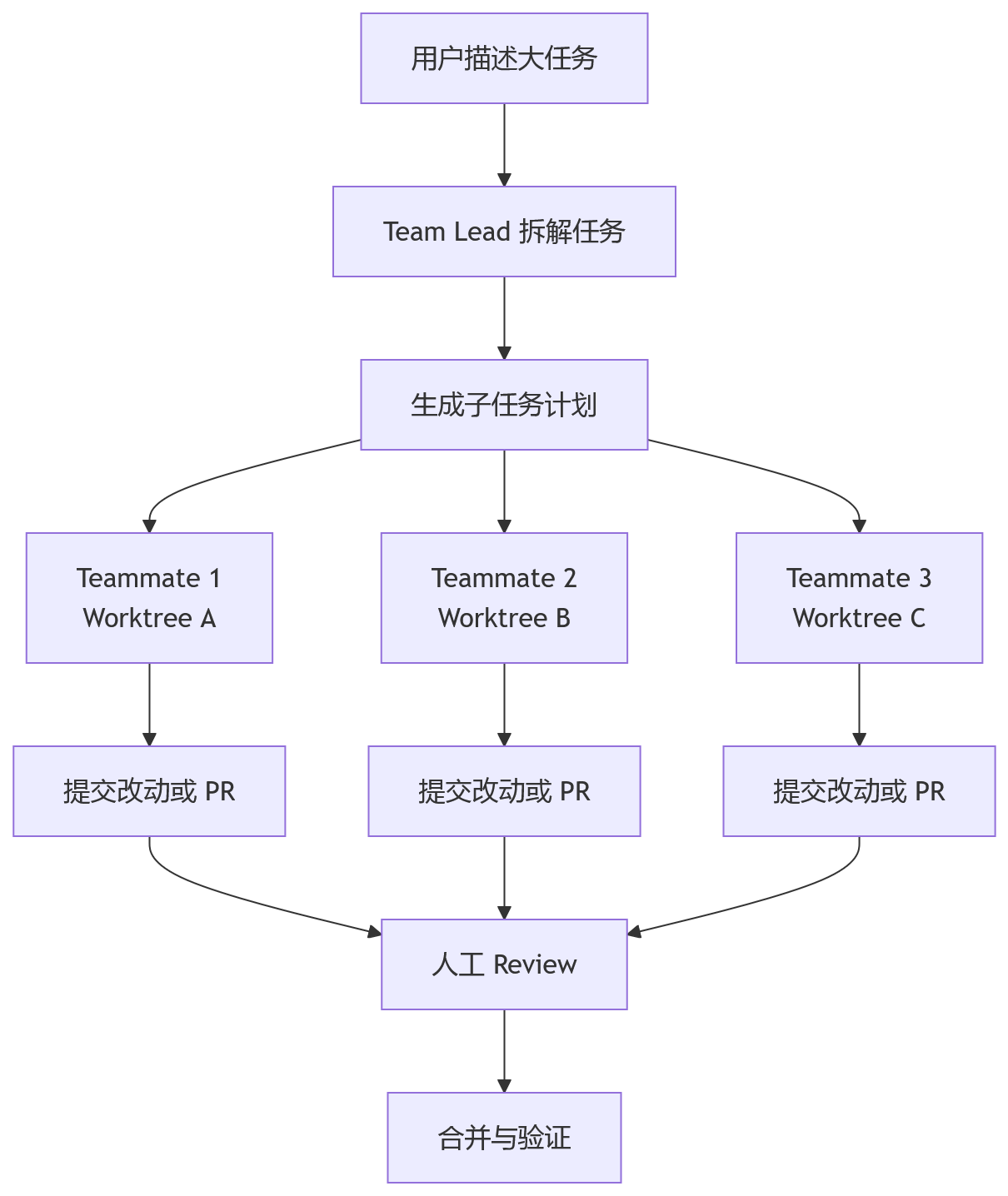
Git Worktree 是这里的关键。它解决的是并行修改时的文件隔离问题。每个 Agent 在自己的工作区里改代码,避免多个 Agent 同时踩同一个 working directory。
但 Worktree 只能解决文件层面的隔离,解决不了设计层面的冲突。
比如一个 REST 到 GraphQL 的迁移任务,如果拆成:
- Agent A 修改用户模块
- Agent B 修改订单模块
- Agent C 修改商品模块
- Agent D 修改前端 API client
- Agent E 补测试
看起来很合理。但如果 schema 命名、错误模型、鉴权方式没有提前定好,最后会出现五套风格。合并时不是简单解决冲突,而是要重新统一设计。
所以 Agent Teams 适合的任务有一个前提:架构边界和接口约束要先定清楚。
适合 Agent Teams 的任务:
- 多模块相似重构
- 大规模 API 迁移
- 批量测试补齐
- 多服务依赖升级
- 代码库分区明确的改造
不太适合的任务:
- 产品语义还没定的需求
- 架构方向不明确的重构
- 需要强一致设计判断的核心模块
- 小改动、小 Bug 修复
还有一个很现实的问题:成本。
5 个 Teammate 加一个 Team Lead,不会神奇地只消耗一个 Agent 的 Token。大致可以理解为线性增长,再叠加协调开销。大任务跑之前,最好先用一个小切片验证:
- 子任务能否拆开
- 单个 Agent 产出质量如何
- Worktree 合并是否顺畅
- Token 消耗是否可接受
- 测试是否能覆盖主要风险
这个验证成本不高,但能避免直接把一个大重构跑成一堆需要人工救火的 PR。
五、/batch 更像工程流水线
如果说 Agent Teams 偏协作,/batch 更偏批处理。
它适合一类很常见的任务:多个子任务结构相似,执行路径相似,但文件或模块不同。
比如:
- 给 20 个接口补充输入校验
- 把多个页面从旧组件迁移到新组件
- 批量替换废弃 API
- 为多个模块生成基础测试
- 按固定规范调整错误处理
这类任务如果由一个 Agent 串行做,会很慢;如果用 Agent Teams,又可能有点重。/batch 的价值在于把任务切成多个相对独立的修改单元,每个单元在独立 Worktree 中执行,最终形成独立 PR 或改动。
它的工程收益很明确:
- 可以并行跑
- 每个 PR 更小
- Review 粒度更清楚
- 失败可以局部回滚
但它也非常依赖任务切分质量。批量任务最怕指令模糊,比如:
重构所有用户相关代码,让它更优雅。
这种指令放进批处理里,大概率会得到一堆风格不统一的改动。
更好的写法应该是:
将
services/user/**下直接调用legacyHttpClient的代码迁移到apiClient.user。保持函数签名不变,不修改业务逻辑。每个子任务只处理一个文件。修改后运行对应单元测试。
这里面有几个关键约束:
- 修改范围
- 目标 API
- 不允许改什么
- 子任务粒度
- 验证方式
这才是批处理能稳定工作的基础。
六、Headless 模式的本质
并行 Agent 解决的是吞吐问题,Headless 模式解决的是集成问题。
交互式 Claude Code 面向人。Headless 模式面向流程。它可以从标准输入读取内容,非交互地执行任务,然后把结果输出给下游系统。
最基本的用法:
echo "解释这段代码的作用" | claude -p
分析日志:
cat error.log | claude -p "分析这个错误日志,找出最可能的根因"
Review Git Diff:
git diff main...HEAD | claude -p "Review 这个 PR 的改动,关注潜在 Bug"
Headless 的价值,不是让你少打开一个终端,而是它能嵌入已有工具链:
- GitHub Actions
- GitLab CI
- Jenkins
- pre-commit hook
- npm scripts
- Release pipeline
- 内部质量平台
这意味着 Claude Code 从“人主动调用的工具”,变成“流程自动触发的能力”。
不过,自动化里最重要的不是会不会跑,而是结果是否稳定、可解析、可追踪。否则 AI 输出再漂亮,也很难进入生产级流程。
七、结构化输出是分水岭
如果 Headless 只输出自然语言,它最多是一个自动评论工具。真正想接入工程系统,结构化输出是必需的。
比如列出项目里的 TODO:
claude -p "列出项目中所有 TODO 注释" --output-format json
更进一步,可以用 JSON Schema 约束输出:
claude -p "分析 package.json 的依赖风险" \
--json-schema '{
"type": "object",
"properties": {
"outdated": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": { "type": "string" },
"current": { "type": "string" },
"latest": { "type": "string" },
"risk": { "enum": ["low", "medium", "high"] }
},
"required": ["name", "current", "latest", "risk"]
}
}
},
"required": ["outdated"]
}'
这类约束很重要。因为 CI/CD 不会像人一样“理解一下意思”。它需要明确字段,明确状态,明确是否阻断流程。
在工程里,可以把 AI 输出分成三档:
| 输出类型 | 适用场景 | 是否适合自动化决策 |
|---|---|---|
| 自然语言 | Review 评论、分析报告 | 不适合直接阻断 |
| Markdown | PR 评论、Release Note | 适合展示,不适合机器判断 |
| JSON / Schema | 风险扫描、质量门禁 | 适合进入流水线 |
这里有个经验判断: 如果一个 AI 检查会影响合并、发布、告警,尽量要求结构化输出,并且只让它做“给出候选风险”,不要让它独立承担最终决策。
AI Review 可以提示风险,但是否阻断 CI,最好仍由明确规则控制。比如 Critical 数量大于 0 才失败,或者只对安全类 High 风险阻断。否则误报会很快消耗团队信任。
八、--bare 与可复现性
Headless 放到 CI 里,最容易被忽略的是环境一致性。
本地 Claude Code 可能加载:
- Hooks
- Skills
- MCP 服务器
- CLAUDE.md
- 用户自定义配置
- 本地上下文
这些能力在交互式开发里很方便,但在 CI 里可能变成不确定因素。
--bare 的意义就在这里:
claude -p "检查代码中的安全漏洞" --bare
它会跳过 Hooks、Skills、MCP 服务器和 CLAUDE.md 的加载,让执行环境更干净。
这背后是一个典型工程权衡:
- 本地开发需要上下文丰富,提高效率
- CI/CD 需要环境稳定,提高可复现性
便利性和可复现性经常冲突。CI 里通常应该优先选择后者。因为流水线一旦行为漂移,排查成本会很高。你很难接受同一个 Commit 今天过、明天不过,只是因为某个本地配置或外部工具上下文变了。
权限控制也要收紧:
claude -p "检查代码风格" \
--bare \
--permission-mode dontAsk \
--allowedTools "Read,Glob,Grep"
这里的思路是: 在无人值守环境里,尽量只允许读操作。需要写文件、提交代码、运行命令的任务,要么进入隔离环境,要么要求人工确认。
九、CI/CD 集成场景
PR 自动 Review
一个比较常见的 GitHub Actions 配置:
# .github/workflows/claude-review.yml
name: Claude Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Setup Claude Code
run: npm install -g @anthropic-ai/claude-code
- name: Review PR
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
git diff origin/main...HEAD | claude -p \
"你是一位资深 Code Reviewer。
请从以下维度审查这个 PR:
1. 潜在 Bug 和边界情况
2. 性能隐患
3. 安全风险
4. 可维护性
只输出中高风险问题。
如果没有明显问题,输出 LGTM。
输出中文,按严重程度排序。" \
--bare \
--output-format text > review.md
- name: Post Review Comment
uses: actions/github-script@v7
with:
script: |
const fs = require('fs');
const review = fs.readFileSync('review.md', 'utf8');
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: `## Claude Code Review\n\n${review}`
});
这个例子适合做“辅助 Review”,不建议一开始就让它阻断合并。原因很简单:AI Review 的误报和漏报都客观存在。先作为评论进入团队流程,观察一段时间,再决定是否接质量门禁,会稳很多。
自动生成 Changelog
Release 流程里,Changelog 很适合交给 AI 处理。因为它本质上是信息整理和面向用户的表达转换。
- name: Generate Changelog
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
git log v${{ env.PREV_VERSION }}..HEAD --oneline | \
claude -p \
"根据以下 Git 提交记录,生成结构化 Changelog。
分为 Features、Bug Fixes、Breaking Changes、Performance 四类。
每条用一句话描述,面向用户而非开发者。" \
--bare \
--json-schema '{
"type": "object",
"properties": {
"features": { "type": "array", "items": { "type": "string" } },
"bug_fixes": { "type": "array", "items": { "type": "string" } },
"breaking_changes": { "type": "array", "items": { "type": "string" } },
"performance": { "type": "array", "items": { "type": "string" } }
},
"required": ["features", "bug_fixes", "breaking_changes", "performance"]
}' > changelog.json
这里建议用 JSON 输出,而不是直接生成 Markdown。JSON 可以后续进入发布系统,再由模板渲染成不同格式,比如 GitHub Release、官网更新日志、内部通知。
AI Lint 接入 npm scripts
对于前端或 Node 项目,可以把 AI 检查放进 scripts:
{
"scripts": {
"lint:ai": "git diff --cached | claude -p '检查暂存区的代码变更,指出潜在逻辑错误、类型问题和不良实践。如果没有问题,输出 LGTM。' --bare --permission-mode dontAsk",
"precommit:ai": "claude -p '快速审查即将提交的变更,只输出 Critical 和 High 级别的问题。' --bare --allowedTools 'Read,Glob,Grep'"
}
}
不过 pre-commit 阶段要克制。如果每次提交都要等 AI 跑几十秒,开发者很快会绕开它。更合理的做法是:
- 本地 pre-commit 只做轻量检查
- PR 阶段做完整 AI Review
- 主干合并前只阻断明确高风险项
自动化工具一旦影响手感,就会被团队“民间禁用”。这个问题我见过很多次,和工具先进不先进关系不大,主要是流程摩擦太高。
Pipeline 中的多轮会话
有些任务不是一次调用能完成的,比如先分析,再执行:
- name: Analyze
run: |
claude -p "分析项目结构,列出最需要重构的 3 个模块。输出 JSON。" \
--bare \
--output-format json > analysis.json
- name: Execute Refactor
run: |
claude -p "根据上次的分析,开始重构排名第一的模块,确保测试通过。" \
--continue \
--permission-mode acceptEdits
多轮上下文能减少重复输入,但在 CI 里要谨慎使用。因为会话状态本身也是一种隐式依赖。对于关键流水线,更推荐把上一步产物显式保存成文件,再作为下一步输入:
cat analysis.json | claude -p "基于这份分析结果,生成重构计划。不要直接修改代码。"
显式数据流比隐式会话更容易排查问题。
十、Agent SDK 的位置
Headless 模式适合命令行自动化。但如果你要构建更复杂的业务 Agent,比如内部数据库迁移助手、代码生成平台、自动化修复系统,命令行就不够用了。
这时可以考虑 Agent SDK。
安装方式示例:
# Python
pip install claude-agent-sdk
# TypeScript / Node.js
npm install @anthropic-ai/claude-agent-sdk
Python 示例代码:
from claude_agent_sdk import Agent
agent = Agent(
model="claude-sonnet-4-20250514",
instructions="你是一个数据库迁移助手,负责分析 schema 差异并生成迁移计划。",
tools=["read_file", "write_file", "execute_sql"]
)
result = await agent.run("将 users 表从 MySQL 迁移到 PostgreSQL")
print(result)
SDK 的优势是控制力更强:
- 可以定义自定义工具
- 可以管理长期状态
- 可以接入内部权限系统
- 可以把 Agent 编排进业务流程
- 可以做更细粒度的日志和审计
但 SDK 也意味着你开始维护一个真正的 Agent 应用,而不是简单调用工具。这里会出现新的工程问题:
- 工具权限如何隔离
- 执行日志如何审计
- 错误恢复怎么做
- 成本如何归因
- 用户输入如何防注入
- Agent 产物如何验证
如果只是 PR Review、Changelog、日志分析,Headless 已经够用。 如果要做长期运行、状态复杂、深度接入内部系统的 Agent,再考虑 SDK 会更合理。
另外,Agent SDK 独立计费后,成本模型也要单独评估。对重度使用场景,最好提前把 Token 消耗、调用频次、失败重试和人工节省时间算清楚。AI 成本不一定高,但不能糊涂用。
十一、落地时的几个判断
Claude Code 的多 Agent 和 Headless 能把效率拉起来,但前提是任务适合被工程化。
比较稳的落地路径是:

不要一开始就追求全自动。更好的方式是先把 AI 放在“建议层”,等输出稳定后,再逐步进入“执行层”。
几个相对实用的原则:
- 读操作先行,写操作后置先让 AI 做分析、扫描、Review。自动改代码要等团队对质量有信心。
- 小 PR 优于大 PR并行 Agent 的产物越小,Review 和回滚越容易。
- 明确禁止项比开放式目标更重要比如“不修改业务逻辑”“不改变函数签名”“不调整公共 API”。
- **CI 里优先
--bare**可复现性比上下文便利更重要。 - 用结构化输出连接系统自然语言适合人看,JSON 才适合机器处理。
- 成本要前置评估 并行 Agent 提升的是吞吐,不是免费算力。Token、等待时间、Review 成本都要算进去。
Claude Code 走到多 Agent 和 Headless 这一步,已经不只是一个更聪明的命令行助手。它开始具备进入工程体系的形态:能并发、能隔离、能接流水线、能产出结构化结果。
但越接近工程系统,越不能只看演示效果。真正决定它能不能在团队里长期跑下去的,是任务边界、权限控制、结果验证、成本模型和人类 Review 的位置。
用它提速是对的,但别把它当魔法。更靠谱的姿势,是把 Claude Code 当成一组可编排的工程能力:小任务让它独立跑,大任务让它分工跑,关键路径让它辅助人跑。这样效率提升才不会变成另一种形式的技术债。
