












































RAG 做到小规模 Demo 并不难。几十篇文档、几百个 chunk,向量检索一接,大模型一答,看起来很顺。但文档规模一上来,问题就变了。
当语料库增长到百万、千万级,模型编造内容的方式反而更多:检索会带回相似但不相关的上下文,chunk 可能丢掉关键实体,reranker 可能把“提到过”误判成“能回答”,生成模型再顺手补几句外部知识。最后用户看到的是一段很流畅、甚至带引用的答案,但引用未必真的支撑它。
这类系统要靠“模型更聪明”解决,通常会走偏。更现实的路线是:把一个普通生成模型包在一条有约束的 pipeline 里,让它只能回答有证据支持的内容;证据不够时,安全失败为拒答,而不是猜测。
这篇文章基于一个完整实现:
https://github.com/FareedKhan-dev/rag-zero-hallucinations
它的核心目标很明确:
- 在可回答问题上,尽量给出有引用、有证据的答案;
- 在不可回答问题上,把幻觉转成拒答;
- 检索底座能扩展到 1000 万 vectors;
- 每个 claim 都要经过证据检查,而不是只相信模型自己说“我引用了”。
一、近零幻觉靠系统约束
“近零幻觉”这个说法容易被误解。它不是说模型永远不会产生错误文本。只要系统里有生成模型,字面意义上的零幻觉基本不现实。
更可行的目标是:让错误答案尽量不要越过系统边界到达用户。
这意味着 pipeline 里要有一组防火墙:
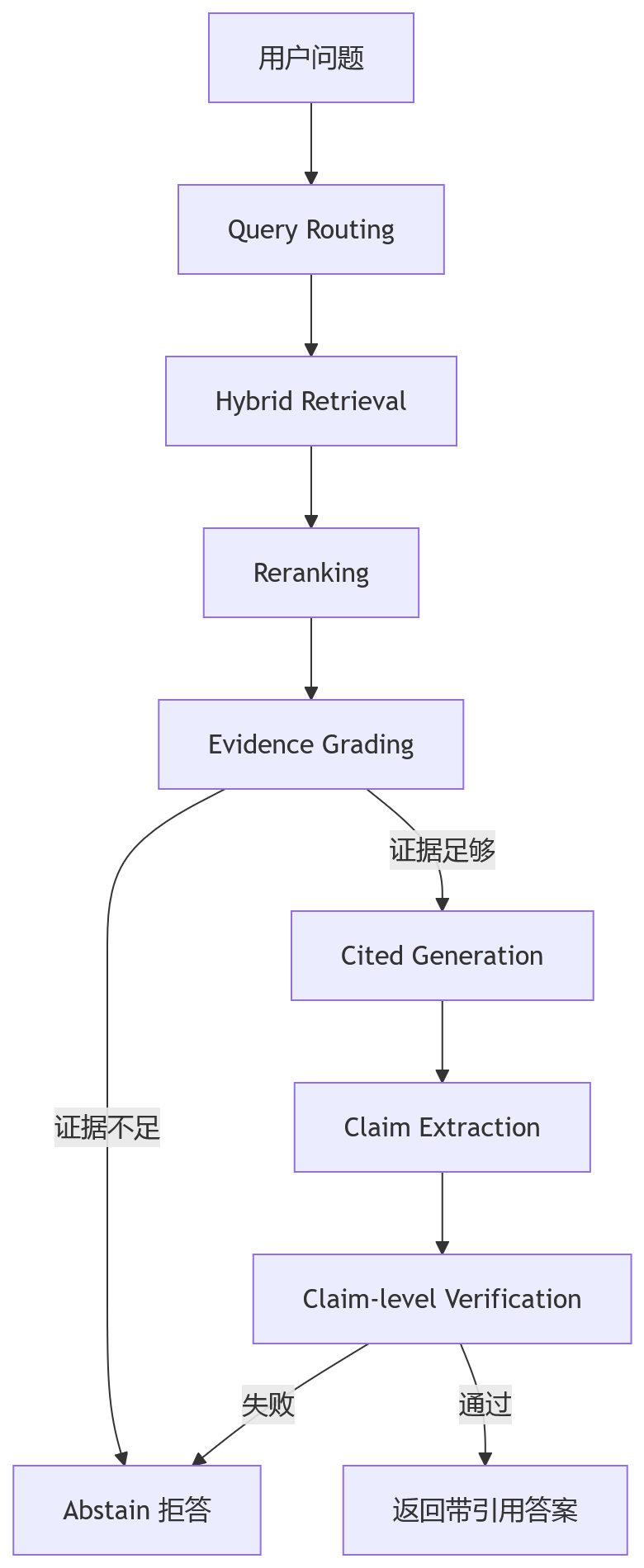
这里的关键不是某一个组件多先进,而是系统 contract 很清楚:
到达用户的每一句话,都必须能在 retrieved context 中找到支撑;找不到,就拒答。
这和很多 RAG Demo 的默认行为完全不同。普通 RAG 往往是:
- 检索一些上下文;
- 塞进 prompt;
- 让模型回答;
- 相信模型会“根据上下文”。
生产环境里,麻烦往往就在第 4 步。模型会根据上下文,也会根据预训练知识,也会根据问题暗示补全缺失信息。只靠 prompt 约束,挡不住所有情况。
所以这条 pipeline 把信任拆成了几层:
| 层级 | 目标 | 主要手段 |
|---|---|---|
| 检索层 | 尽量找回正确证据 | Dense BM25 RRF |
| 精排层 | 排除相似但无用内容 | Cross-encoder reranker |
| 生成层 | 强制引用上下文 | Inline citations abstain token |
| 验证层 | 检查每个 claim 是否被支持 | Claim extraction faithfulness judge |
| 策略层 | 失败时安全退出 | Abstention policy |
真正的工程权衡也在这里:要低幻觉,就必须牺牲一部分覆盖率。 系统宁愿不回答一些本可以回答的问题,也不愿在证据不足时输出一个自信但错误的答案。这不是模型能力问题,而是产品风险边界问题。
二、数据与评估先要站住
如果没有不可回答问题集,RAG 幻觉评估基本是不完整的。
只在 answerable questions 上测准确率,很容易得出过于乐观的结论。因为这类评估只问“系统能不能答对”,没有问“系统该不该闭嘴”。
这个实现里用了三类数据:
- HotpotQA distractor:提供多跳问题和 sentence-level gold supporting facts;
- SQuAD v2 impossible questions:提供不可回答问题;
- 手写 false-premise questions:专门测试系统会不会顺着错误前提编。
例如:
Which programming language did Isaac Newton invent in 1700?
一个普通生成模型很可能会开始编故事。一个可信 RAG 系统应该直接说证据不足。
HotpotQA 的价值在于,它不仅有问题和答案,还有 supporting facts。这样可以比较清楚地评估 retrieval recall:正确证据是否被检索回来了。
示例问题:
Were Scott Derrickson and Ed Wood of the same nationality?
Gold evidence 是两句话:
- Scott Derrickson 是 American director;
- Ed Wood 是 American filmmaker。
这类问题看起来简单,但对 RAG 很典型:需要同时找回两个实体的证据,并组合成答案。只找回一个,模型就容易猜另一个。
三、清洗和 Chunking 决定证据质量
很多团队调 RAG,第一反应是换 embedding model,或者把 top_k 调大。但如果 corpus 本身脏、chunk 切得差,后面模型再强也只是补锅。
这条 pipeline 在 indexing 前做了两件廉价但重要的事。
文本归一化
BM25 对原始字符非常敏感。不可见字符、连字、重复空格,都可能影响 tokenization。
import re, unicodedata
def normalize_text(s: str) -> str:
s = unicodedata.normalize("NFKC", s)
s = s.replace("", "")
s = re.sub(r"[ \t] ", " ", s)
return s.strip()
例如:
"the final report\twas ready"
会被归一化成:
"the final report was ready"
这种处理看起来不起眼,但在大规模文档里很值。RAG 的很多问题不是“模型不懂”,而是证据在进入索引前就已经变形了。
近重复去重
重复内容会带来两个问题:
- index 变大;
- top results 被重复 passage 挤满。
第二个更隐蔽。同一段内容的多个副本会让模型误以为某个证据“被多方确认”,实际上只是重复数据。
这里用 MinHash LSH 做近似去重。原因很直接:全量 pairwise 比较是二次复杂度,数据规模一上去根本跑不动。
class Deduper:
"""Drop near-duplicate passages via MinHash LSH over word shingles."""
def __init__(self, threshold: float = 0.9, num_perm: int = 64):
self.threshold, self.num_perm = threshold, num_perm
def fit_transform(self, passages):
lsh = MinHashLSH(threshold=self.threshold, num_perm=self.num_perm)
kept, dropped = [], 0
for p in passages:
m = self._mh(p.text)
if lsh.query(m):
dropped = 1
continue
lsh.insert(p.id, m)
kept.append(p)
return kept, {"kept": len(kept), "dropped_near_dup": dropped}
这里的 trade-off 是:近似去重可能误删一些相似但有差异的段落。对知识库 RAG 来说,一般可以接受;但如果场景是法律条款、合同版本、审计记录,就要更谨慎,甚至要保留版本信息而不是直接删。
四、Chunk 不能只按长度切
固定长度 chunking 是最容易实现的,也是最容易伤害证据结构的。
如果一个 chunk 把实体和限定条件切开,后面检索回来的是半截证据,模型就会开始补。尤其是 multi-hop question,切坏一个实体,整条推理链都会断。
这个实现采用结构感知 chunking:
- 尽量按句子边界切;
- 控制 token budget;
- 保留少量 overlap;
- 使用 generator 自己的 tokenizer 计算 token 数。
class StructureAwareChunker:
def __init__(self, tokenizer, target_tokens: int = 256, overlap: int = 32):
self.tok, self.target, self.overlap = tokenizer, target_tokens, overlap
def chunk(self, passage):
sents = split_sentences(passage.text) or [passage.text]
chunks, cur, cur_tok = [], [], 0
for s in sents:
st = self._ntok(s)
if cur and cur_tok st > self.target:
chunks.append(self._make(passage, cur))
cur, cur_tok = ([cur[-1]], self._ntok(cur[-1])) if self.overlap else ([], 0)
cur.append(s)
cur_tok = st
if cur:
chunks.append(self._make(passage, cur))
return chunks
还有一个很有用的细节:contextual retrieval。
很多 chunk 单独看并不可检索。例如:
revenue grew 3 percent that quarter
这个句子如果脱离标题和上文,检索系统不知道是谁的 revenue、哪个 quarter。解决办法是在 chunk 前加一句短上下文:
This chunk discusses Acme Corp's Q2 2023 financial performance.
revenue grew 3 percent that quarter...
这句上下文由本地 LLM 生成,并作为索引文本的一部分。
这个设计的收益在 recall。RAG 的验证层再强,也只能验证检索回来的证据。证据没回来,后面只能拒答或猜。为了降低幻觉,前面要尽量把正确证据找回来。
五、Hybrid Retrieval 是底座
单一检索器很少够用。
Dense embedding 擅长语义相似和 paraphrase,但会模糊 rare name、编号、数字。BM25 擅长精确词匹配,但对换一种说法的问题很弱。
所以这里采用 hybrid retrieval:

Dense 和 sparse 的分数不可直接比较。BM25 score 和 cosine similarity 不在一个尺度上,强行归一化很容易引入奇怪偏差。
这里用 Reciprocal Rank Fusion,直接按排名融合:
def rrf_fuse(rankings: list[list[str]], k: int = 60) -> list[tuple[str, float]]:
scores: dict[str, float] = {}
for ranking in rankings:
for rank, cid in enumerate(ranking):
scores[cid] = scores.get(cid, 0.0) 1.0 / (k rank 1)
return sorted(scores.items(), key=lambda x: -x[1])
RRF 的好处是很朴素:两个检索器都觉得不错的结果,会排在只有一个检索器特别喜欢的结果前面。
然后用 cross-encoder reranker 对 top 150 做精排,保留 top 20。
这个顺序很重要:
- Dense/BM25 负责宽召回,便宜;
- Reranker 负责精排,贵;
- 只在 150 个候选上跑 reranker,成本与 corpus 总规模解耦。
这也是扩展到千万级文档时的关键工程点。无论底层 index 是 2 万 chunks 还是 1000 万 chunks,reranker 看到的仍然是固定数量候选。
六、引用生成只是第一道防线
很多 RAG 系统做到“带引用”就停了。但引用本身并不等于可信。
模型可能引用真实 passage,却说出 passage 没有支持的话。更糟糕的是,模型还可能编造一个看起来像真的 citation id。
所以生成阶段做了两件事:
- prompt 强制每句话带 citation;
- parse citation,只保留真实存在的 chunk id。
ABSTAIN_TOKEN = "INSUFFICIENT_EVIDENCE"
GENERATION_SYSTEM_PROMPT = (
"You answer strictly from the numbered context passages. Rules:\n"
"1. Use ONLY facts in the passages, never outside knowledge.\n"
f"2. If the passages do not contain the answer, reply with exactly: {ABSTAIN_TOKEN}\n"
"3. Every sentence MUST end with a citation to the passage id(s) it uses, like [abc123def456].\n"
"4. Be concise and factual."
)
Citation 解析也很关键:
def parse_citations(text: str, valid_ids: set[str]) -> tuple[list[str], str]:
found = _CITE_RE.findall(text)
valid = [c for c in dict.fromkeys(found) if c in valid_ids]
invalid = [c for c in dict.fromkeys(found) if c not in valid_ids]
cleaned = text
for bad in invalid:
cleaned = cleaned.replace(f"[{bad}]", "")
return valid, cleaned
如果模型输出:
Paris is the capital of France [a1b2c3d4e5f6].
The Louvre opened in 1793 [deadbeef0000].
而 deadbeef0000 不在 retrieved chunks 里,就会被移除。
这一步只能说明:模型引用的是系统提供过的 passage。 它还不能说明:这段 passage 真的支撑了答案。
真正决定可信度的是下一层。
七、Claim 级验证才是关键
整条 pipeline 最重要的防火墙,是 claim-level verification。
流程是:
- 把生成答案拆成 atomic claims;
- 找到被引用的 context;
- 用 faithfulness judge 给每个 claim 打 support score;
- 任何 claim 低于阈值,整段答案拒答。
class VerificationGate:
def check(self, cited, chunks):
claims = self.extractor.extract(cited.text)
used = [c for c in chunks if c.id in set(cited.cited_ids)] or chunks
context = "\n\n".join(c.text for c in used)
verdicts = []
for cl in claims:
s = self.verifier.support(cl, context)
verdicts.append(
ClaimVerdict(
claim=cl,
score=s["score"],
supported=s["score"] >= self.tau
)
)
min_support = min((v.score for v in verdicts), default=0.0)
passed = len(verdicts) > 0 and all(v.supported for v in verdicts)
return GateResult(passed, verdicts, min_support, len(verdicts))
为什么要 claim-level,而不是 answer-level?
因为长答案很容易出现这种情况:
- 80% 内容有证据;
- 20% 内容是模型补的;
- answer-level score 看起来还不错;
- 但用户真正受伤的是那 20%。
所以这里用 weakest claim,而不是平均分。答案可信度取决于最弱的那句话。
例如一个 false-premise draft:
Marie Curie was a physicist.
Marie Curie traveled to the Moon.
验证结果可能是:
[OK 0.95] Marie Curie was a physicist.
[XX 0.20] Marie Curie traveled to the Moon.
第二个 claim 失败,整段答案拒答。
这个设计很保守,但它符合低幻觉系统的目标。你不能因为前半句是对的,就把后半句编造内容也放出去。
八、拒答是产品能力
很多产品把拒答当失败,其实在可信 RAG 里,拒答是核心能力。
系统把所有输出归成两类:
@dataclass
class FinalAnswer:
status: str # "answered" or "abstained"
answer: str
citations: list[str]
min_support: float
reason: str
拒答原因可以很清楚:
routed_no_retrievalmodel_abstainedunsupported_claimsverified
策略也不复杂:
class AbstentionPolicy:
def decide(self, route, false_premise, cited, gate):
if route == "no_retrieval":
return self._abstain("routed_no_retrieval", gate)
if cited.abstained:
return self._abstain("model_abstained", gate)
if gate is None or not gate.passed or gate.min_support I do not have enough supporting evidence in the available sources to answer this confidently.
不要给用户一种“系统大概知道但不愿说”的感觉。它不是知道,它是没有足够证据。
## 九、Agent Graph 让流程可控
这条 pipeline 不是简单直线。它有分支、有回路、有提前退出:
- 问候或主观问题,不走 retrieval;
- 证据强,直接生成;
- 证据弱,refine query 后重试;
- 多次重试仍不够,拒答;
- 生成后验证失败,也拒答。
用 LangGraph 表达这类控制流比较自然。

状态对象大概长这样:
```python
class AgentState(TypedDict, total=False):
question: str
route: str
query: str
evidence: list
grade: float
draft: Any
gate: Any
final: Any
hops: int
latencies: dict
Evidence grade 决定下一步:
def _after_grade(state: AgentState) -> str:
g = state.get("grade", 0.0)
if g >= CRAG_OK:
return "generate"
if g = MAX_HOPS:
return "generate" if g >= CRAG_BAD else "finalize"
return "refine"
这里有一个边界要注意:corrective loop 不能无限跑。 这个实现限制最多 3 hops。多给几次机会可以提高 recall,但 latency 会快速变差。真实系统里,这个参数要跟 SLA 一起设计,而不是只看回答质量。
示例问题:
Were Scott Derrickson and Ed Wood of the same nationality?
完整路径结果:
route=single_hop
hops=0
grade=1.00
status=answered
reason=verified
答案:
Yes, Scott Derrickson and Ed Wood were of the same nationality; both were American.
并带有两个 citation。
而对于:
Which programming language did Isaac Newton invent in 1700?
结果是:
grade=0.15
status=abstained
reason=unsupported_claims
系统没有进入生成阶段。这一点很关键:如果已经知道证据不足,就不要再给模型一次发挥空间。
十、评估结果看风险单元格
最终评估用了 200 个问题:
- 100 个 answerable;
- 100 个 unanswerable。
最重要的是 2x2 confusion matrix:
rows: answerable / unanswerable
cols: answered / abstained
[[46 54]
[ 2 98]]
唯一危险的格子是:
unanswerable answered = hallucination
也就是 100 个不可回答问题里,系统回答了 2 个,幻觉率 2%。
这个数字比单纯看准确率有意义得多。因为低幻觉 RAG 最怕的不是“不会答”,而是“不知道还硬答”。
当然,代价也很明显:
100 个可回答问题,只回答了 46 个。
coverage 只有 0.46。
这就是安全性代价。 阈值调高,幻觉率下降,覆盖率也下降;阈值调低,覆盖率上升,风险也上升。
| 目标 | 阈值倾向 | 结果 |
|---|---|---|
| 医疗、法务、金融风控 | 更高 | 少答,降低错误风险 |
| 内部知识助手、研发问答 | 中等 | 平衡覆盖率和可信度 |
| 内容创作、灵感辅助 | 更低 | 多答,允许用户再判断 |
这里没有通用最优点。阈值是产品决策,不是纯技术决策。
十一、Verifier 是上限
这条 pipeline 的瓶颈之一是 verifier。
实现里用本地 32B LLM 作为 faithfulness judge,在 HaluBench 上测得:
AUROC = 0.702
这比随机好,但谈不上强。
这个结果反而值得重视。很多 RAG 方案把 verifier 写进架构图里,就默认它可靠。但 verifier 自己也需要评估,否则只是把幻觉从 answer 转移到了 score 上。
目前这个 verifier 的意义在于:
- 它足以把一部分 unsupported claims 挡下来;
- 它不是完美裁判;
- 替换更强 verifier,可能是提升系统质量最直接的方向。
好在架构上它是可替换组件。无论用更强 LLM judge、NLI cross-encoder,还是专门训练的 faithfulness model,外层 gate 不需要变。
十二、千万向量不是瓶颈
标题里的 1000 万 文档,核心在 vector index。
这里使用 LanceDB 做 on-disk vector store,并在 100k、1M、10M synthetic vectors 上做 benchmark。向量维度是 1024,索引用 IVF_PQ。
结果:
| 向量规模 | 构建时间 | 磁盘占用 | p50 延迟 | p95 延迟 |
|---|---|---|---|---|
| 100,000 | 41.82s | 0.39GB | 8.5ms | 10.59ms |
| 1,000,000 | 81.22s | 3.884GB | 11.34ms | 14.46ms |
| 10,000,000 | 347.04s | 38.825GB | 16.91ms | 18.48ms |
1000 万向量 p95 约 18ms。这个结果说明一件事: 大规模 RAG 的慢点通常不在 vector search,而在围绕检索的模型调用。
需要注意一个 caveat:这里的 scale benchmark 用的是 synthetic random vectors,所以它证明的是 latency、disk、build path,不证明真实语料的 retrieval quality。真实 recall 仍然取决于 embedding、chunking、query rewriting、reranking 等整条链路。
但从工程角度看,on-disk ANN index 的方向是成立的。磁盘占用线性增长,查询延迟增长很慢,这正是千万级系统需要的形态。
十三、真正耗时的是模型调用
阶段延迟大概如下:
| 阶段 | p50 | p95 | 平均 |
|---|---|---|---|
| total | 4.001s | 17.668s | 5.823s |
| retrieve | 3.074s | 11.393s | 4.166s |
| verify | 1.534s | 3.878s | 1.758s |
| generate | 1.451s | 2.484s | 1.619s |
| refine | 1.471s | 2.888s | 1.575s |
| route | 0.168s | 0.206s | 0.170s |
| grade | 0.127s | 0.431s | 0.161s |
retrieve 阶段看起来最慢,但里面真正贵的是 embedding、reranking、可能的 corrective loop。vector search 本身只有毫秒级。
这对优化方向有很强提示:
- batch reranker;
- cache query embedding;
- cache retrieval results;
- 减少不必要的 hops;
- 对 verifier 做轻重分层;
- 对低风险问题降低验证强度;
- 对高风险问题保持严格 gate。
很多团队一看到 RAG 慢,就想换向量数据库。实际不一定有用。先把 latency profile 打出来,通常会发现瓶颈在 LLM calls 和 cross-encoder reranking 上。
十四、这条路线的边界
这套 pipeline 很适合下面几类场景:
- 企业内部知识库;
- 技术文档问答;
- 私有语料检索;
- 合规要求较高的问答;
- 需要引用来源的研究助手;
- 不允许文档离开本地环境的系统。
但它也有边界。
第一,coverage 会下降。 如果业务目标是“尽量都回答”,这套系统会显得保守。
第二,verifier 决定上限。 Claim-level gate 再严,也依赖 judge 判断是否支持。judge 不够强,会有误杀,也会有漏放。
第三,多跳问题仍然难。 Decomposition 和 corrective retrieval 能缓解,但复杂推理链很容易在某个环节断掉。
第四,引用不等于版权和权限安全。 这条 pipeline 解决的是 faithfulness,不自动解决访问控制、数据脱敏、租户隔离等问题。生产环境还要把 ACL 和 retrieval filter 放进索引层。
第五,千万向量不等于千万文档。 文档会被切成 chunks。一个文档可能对应多个 vectors。规划容量时要按 chunk 数算,不要只按文档数算。
这条 pipeline 的价值,不在于某个组件多新,而在于它把 RAG 的可信边界讲清楚了。
检索层尽量找证据,重排层提高证据质量,生成层强制引用,验证层逐 claim 检查,策略层在失败时拒答。每一层都不完美,但组合起来能把很多“自信编造”挡在系统外。
从工程视角看,这比追逐一个“不会幻觉的大模型”更现实。模型会犯错,就让系统默认不信任它;证据足够再放行,证据不足就拒答。
