












































RAG 这两年一直很热,但真正在 Agent 场景里用过的人,大概率都遇到过一个尴尬问题:模型越来越会推理,工具调用也越来越顺手,最后卡住的地方,反而是检索。
很多 Agent 失败并不是因为模型不会想,而是第一步就拿错了材料。尤其是多跳问题,答案分散在几篇文档里,单次检索没命中,后面再怎么规划、反思、重试,也很容易沿着错误方向越走越远。
这也是 SAG(SQL-Retrieval Augmented Generation)值得单独拿出来聊的原因。它没有选择把 RAG 继续复杂化成一套重型知识图谱系统,而是往数据库方向退了一步:把文本整理成 event/entity 结构,再用 SQL 做关系扩展。看起来朴素,但在多跳检索上,效果相当直接。
一、向量 RAG 的多跳短板
传统向量 RAG 的逻辑很顺:把文本 chunk 编码成向量,问题来了,把问题也编码成向量,然后找相似度最高的几段文本。
这个方案能成为主流,原因很现实:
| 特点 | 工程价值 |
|---|---|
| 部署简单 | 向量库 embedding 模型就能跑 |
| 成本可控 | 离线编码、在线 ANN 检索,吞吐容易做 |
| 对非结构化文本友好 | 不要求先建复杂 schema |
| 简单问答效果稳定 | 单文档、单事实问题通常够用 |
但向量检索有一个结构性弱点:它主要判断“像不像”,并不理解“谁和谁存在关系”。
比如一个问题:
A 公司收购了 B 公司,B 公司的 CTO 后来加入了 C 项目,C 项目影响了哪个产品路线?
答案可能分散在三篇文档里:
- 一篇讲 A 收购 B;
- 一篇讲 B 的 CTO 加入 C;
- 一篇讲 C 项目影响某条产品路线。
单独看任意一篇,它和完整问题的语义相似度都未必高。更麻烦的是,中间文档可能只提供桥接关系,不包含最终答案。向量检索如果第一跳没有抓住正确桥,后面基本就断了。
这就是多跳检索和普通相似文本检索的区别。
普通 RAG 像是在资料库里找“最像问题的段落”;多跳 RAG 更像是在找一条证据链。前者靠相似度,后者需要关系扩展。
在 MuSiQue 这种最多需要 4 跳推理的基准上,当前较强的结构化检索方案 HippoRAG 2,Recall@2 为 49.5%。这个数字的含义很直接:只看前 2 条返回结果,一半以上的问题拿不到关键证据。
对普通问答系统来说,这可能只是回答质量下降。对 Agent 来说,问题会被放大。
Agent 通常不是检索一次就结束,而是:

第一步检索偏了,后面的规划也会偏。多轮之后,错误不是线性累加,而是沿着推理链扩散。
所以在 Agent 场景里,Recall@2、Recall@5 这种靠前命中率很关键。不是说 Recall@10 没价值,而是上下文窗口、延迟、token 成本、干扰信息都会限制 Agent “拿一大堆材料慢慢挑”的能力。
二、GraphRAG 的方向与代价
GraphRAG 看到了向量 RAG 的问题。它的基本思路是:从文本中抽取实体和关系,构建知识图谱,然后沿着图谱做多跳检索。
方向是合理的。多跳问题天然需要结构,图结构刚好表达实体之间的连接。
但落到工程里,图谱 RAG 的复杂度不低。
一条文本可能被拆成很多三元组:
| 文本信息 | 三元组表达 |
|---|---|
| OpenAI 在 2025 年发布 GPT-5 | OpenAI → 发布 → GPT-5 |
| GPT-5 属于大语言模型 | GPT-5 → 属于 → LLM |
| GPT-5 发布时间是 2025 年 | GPT-5 → 发布时间 → 2025 |
这里的麻烦不在“能不能抽”,而在“能不能稳定、便宜、持续地抽”。
GraphRAG 通常要处理几类问题:
- 实体抽取:哪些词算实体;
- 实体归一:OpenAI、Open AI、该公司是不是同一个;
- 关系抽取:谓词怎么定义;
- 重复合并:相似实体和关系如何去重;
- 社区发现:大图上怎么聚类;
- 摘要生成:如何让图结构可读、可检索;
- 增量更新:新数据进来时如何维护旧图。
这些步骤很多都依赖 LLM。效果可以做得不错,但成本、延迟、可维护性都会上来。
HippoRAG 2 进一步证明了结构化记忆和多跳检索对 RAG 很重要。它依赖 Personalized PageRank 做图排序,在 benchmark 规模下表现不错。
但如果放到持续增长的生产数据里,全局图排序会带来很重的维护负担。数据每天写入,关系不断变化,如果每次都需要全局重建或大范围重排,系统就很难支撑高频增量。
这里有一个典型工程权衡:
| 方案 | 优势 | 代价 | 更适合的场景 |
|---|---|---|---|
| 向量 RAG | 简单、便宜、吞吐好 | 多跳弱,缺少关系结构 | FAQ、单文档问答、语义搜索 |
| GraphRAG | 关系表达强,多跳自然 | 构建和更新成本高 | 稳定知识库、低频更新、强结构场景 |
| HippoRAG 2 | 结构化记忆能力强 | 全局图排序对增量不友好 | benchmark、相对静态的数据集 |
| SAG | 轻量结构、SQL 扩展、增量友好 | 依赖 event/entity 抽取质量 | Agent 记忆、多跳问答、持续写入数据底座 |
这张表里最关键的一点是:工程上不只看检索效果,还要看数据生命周期。
如果数据是一次性导入、很少变化,重型图谱可以接受。 如果数据每天持续写入,Agent 还要实时使用,轻量结构往往更有生命力。
三、SAG 的 event/entity 索引
SAG 的思路很有意思:它没有继续堆复杂图谱,也没有把文本拆成一堆三元组,而是给每个 chunk 加一张轻量索引卡。
一个 chunk 对应:
- 一个 event:对该 chunk 中事项的完整摘要;
- 多个 entity:从原始 chunk 中抽取出的人物、组织、地点、时间、产品、话题等实体。
event 保留语义上下文,entity 负责索引和连接。
这和三元组路线差异很大。
| 结构 | 表达方式 | 主要问题 |
|---|---|---|
| 三元组 | 头实体 → 关系 → 尾实体 | 语义被切碎,关系谓词不稳定 |
| SAG 超边 | event ↔ 多个 entities | 结构较粗,但保留完整事项语义 |
三元组的问题在真实数据里很容易放大。同一段内容,不同模型可能抽出不同谓词:
- 使用;
- 基于;
- 提出;
- 支持;
- 发布;
- 参与。
谓词一旦不稳定,后续图检索和关系匹配都会受影响。尤其是跨领域数据,schema 很难统一,越想抽得精细,越容易维护不住。
SAG 把要求降低了:LLM 主要做两件事。
第一,把 chunk 总结成一个完整 event。 第二,从原文中尽可能抽取 entity。
event 像一条带上下文的事项记录,entity 像索引点。一个 event 同时连接多个 entity,在图论里更接近超边。
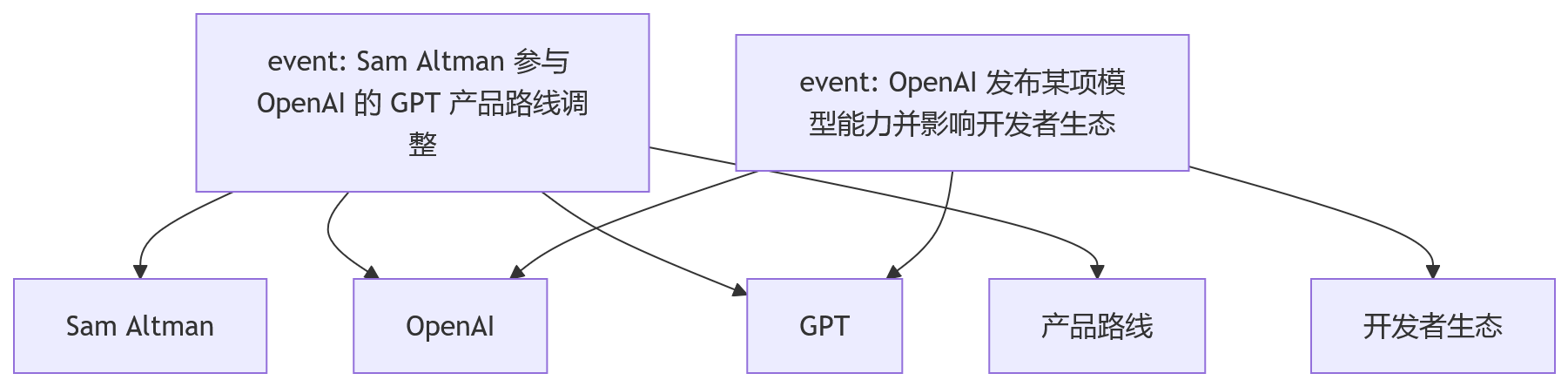
这种结构没三元组那么精细,但对 RAG 来说,精细不一定总是优势。
RAG 最后要回到原文证据。三元组太碎,容易丢上下文;event 保留了一段可读语义,entity 提供连接入口。很多时候,这比抽一堆不稳定谓词更可靠。
素材里提到一个细节值得注意:SAG 在抽取 event 时会做代词消歧,把“他”“该公司”“这个产品”替换成完整名称。这个设计很朴素,但很关键。
因为检索系统里的 event 要能独立被理解。如果 event 里全是上下文依赖的代词,向量检索、关键词检索、重排序都会被干扰。
一个更好的 event 应该像这样:
OpenAI 在 2025 年发布 GPT-5,并将 GPT-5 定位为面向开发者和企业应用的大语言模型产品。
而不是:
该公司在这一年发布了它,并将其定位为面向开发者和企业的产品。
后者对人类读连续上下文没问题,但对检索系统很不友好。
四、用 SQL 做多跳扩展
SAG 的系统分成两段:离线写入和在线检索。
离线阶段:
- 文档切成 chunk;
- 每个 chunk 提取 event;
- 每个 chunk 提取多个 entity;
- event、entity、chunk 关系写入 MySQL;
- event 和 entity 相关文本写入 Elasticsearch,支持向量检索和全文检索。
一个容易被忽略的设计是:event-entity 关系本身也有描述文本,也可以有自己的 embedding。
同一个实体在不同 event 中角色可能完全不同:
| entity | 关系描述 |
|---|---|
| OpenAI | 发布 GPT-5 的公司 |
| OpenAI | Sam Altman 参与管理的公司 |
| OpenAI | 影响开发者生态的模型平台 |
如果只存一个实体名“OpenAI”,召回会非常粗。 如果把实体在事件中的角色也编码进去,实体召回就更接近真实语义。
在线阶段,SAG 走两条路径。
结构化召回
问题进来后,LLM 先识别关键实体。系统用这些实体去索引中找相近实体,再通过 SQL JOIN 找到关联 event 和 chunk。
示意 SQL 大概是这样的:
-- 示意代码:根据候选实体扩展到关联 event
SELECT
e.id AS event_id,
e.summary AS event_summary,
c.id AS chunk_id,
c.content AS chunk_content
FROM entity_candidates ec
JOIN event_entity_rel r
ON ec.entity_id = r.entity_id
JOIN events e
ON r.event_id = e.id
JOIN chunks c
ON e.chunk_id = c.id
WHERE ec.query_id = :query_id
ORDER BY ec.score DESC, r.weight DESC
LIMIT 100;
这里的核心不是 SQL 多复杂,而是数据结构允许这么查。
只要 event 和 entity 的多对多关系在数据库里,关系扩展就可以通过 JOIN 完成,不需要全局图排序。
语义召回
同时,系统会直接用问题向量去检索语义接近的 event。
这条路径补的是另一类情况:用户问题本身已经和某些 event 很接近,没必要绕实体扩展。
结构化召回和语义召回是互补的:
| 路径 | 擅长 | 不擅长 |
|---|---|---|
| 结构化召回 | 沿实体关系找多跳线索 | 实体识别错误时会受影响 |
| 语义召回 | 直接命中语义相近事项 | 对隐含关系和桥接证据较弱 |
消融实验也能说明问题。纯语义路径的 Recall@5 只有 56.2%,加入少量结构化事项候选后,可以提升到 80.0%。
查询时扩展
SAG 的多跳能力来自查询时扩展。
系统先找到一批 event,然后反查这些 event 关联的 entity,再用这些 entity 找新的 event。每一轮只引入之前没有出现过的新内容。
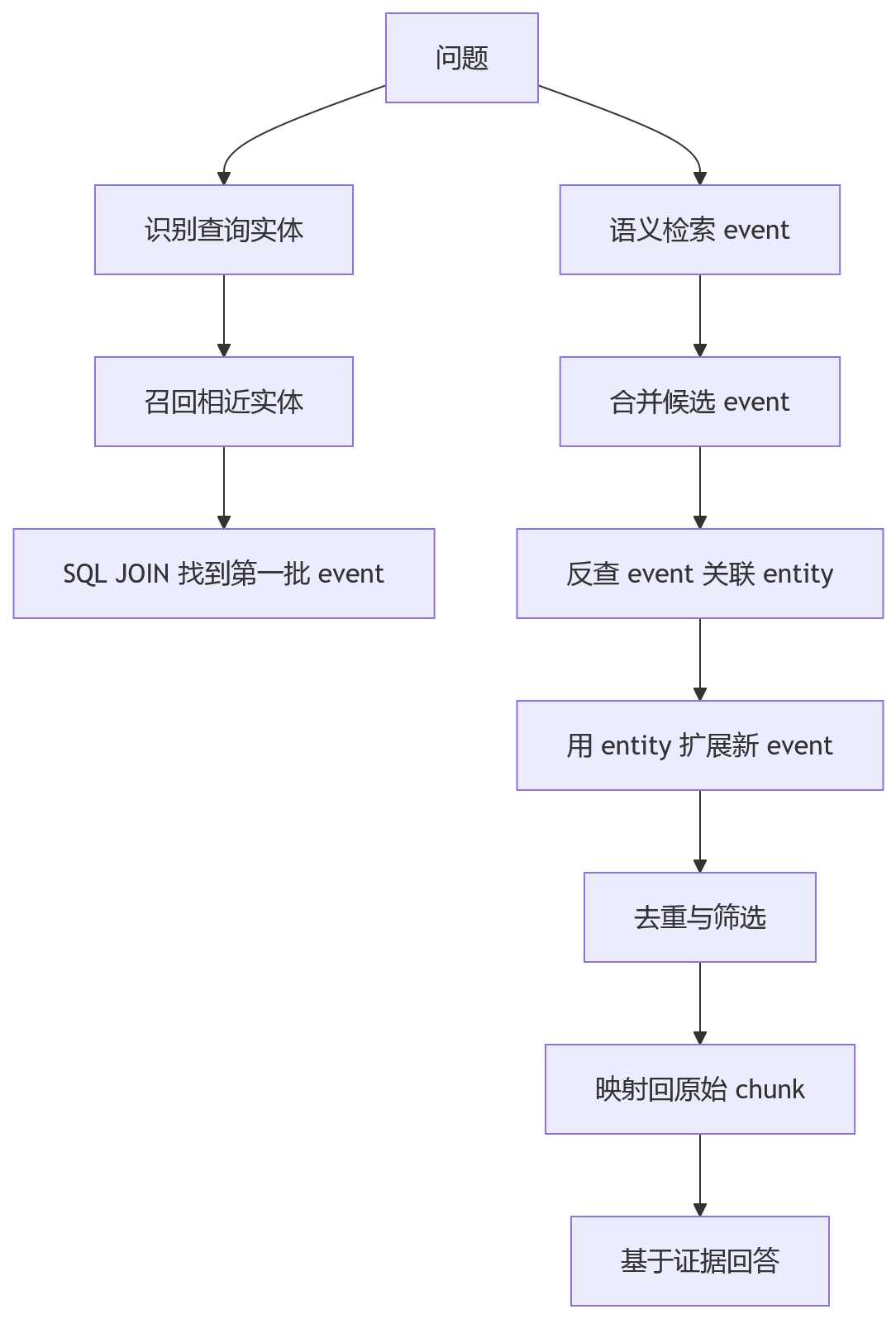
这就是 SAG 工程上比较克制的地方。
它没有要求系统维护一张全局可推理图,也没有让 LLM 在线临时构建复杂关系网络,而是把多跳检索压回数据库里的局部扩展。
说白了,就是 JOIN。
这不是贬低。很多生产系统里,最稳定的方案往往就是把问题整理成数据库能处理的形状。
五、性能提升来自结构
SAG 在 HotpotQA、2WikiMultiHop、MuSiQue 三个多跳基准上做了对比。相同 embedding 模型 BGE-Large-EN-v1.5 和 LLM Qwen3.6-Flash 配置下,结果很明确:
| 指标 | SAG | HippoRAG 2 | 差值 |
|---|---|---|---|
| 平均 Recall@2 | 79.3% | 68.2% | 11.1 pp |
| MuSiQue Recall@2 | 64.1% | 49.5% | 14.6 pp |
| MuSiQue Recall@5 | 80.04% | 65.1% 左右 | 明显领先 |
MuSiQue 是更能体现差异的数据集,因为它最多需要 4 跳推理,而且每条推理链都不能随便跳过。SAG 在这里优势突出,说明 event/entity 索引确实更适合复杂关联问题。
这里还有两组对比很有参考价值。
第一组是超边和三元组。
| 结构 | MuSiQue Recall@5 |
|---|---|
| 三元组 | 77.16% |
| SAG 超边 | 80.04% |
更简单的结构效果反而更好。原因不难理解:三元组保留的语义更碎,向量检索时容易匹配到关键词重合但关系无关的片段。event 把多个实体压在一个完整事项里,多跳扩展时连接更密,误差传播更少。
第二组是 embedding 模型鲁棒性。
HippoRAG 2 原论文使用更强的 NV-Embed-v2,在 MuSiQue 上 Recall@5 达到 74.6%。但换成 BGE-Large-EN-v1.5 后,下降到 65.1%,损失接近 10 个百分点。
SAG 在 BGE-Large-EN-v1.5 下达到 80.0%,换成 NV-Embed-v2 后提升到 81.7%,变化不大。
这个结果说明,SAG 的收益主要来自索引结构和检索算法,而不是单纯依赖更强的 embedding 模型硬拉。
这点对生产环境挺重要。
因为模型升级并不总是免费的。更强 embedding 往往意味着更高成本、更慢写入、更复杂部署。一个检索架构如果必须绑定顶级 embedding 才能跑出效果,落地空间会被压缩。
SAG 的结构鲁棒性,降低了底层模型选择压力。
六、生产环境里的现实价值
Benchmark 好看是一回事,生产环境能不能跑是另一回事。
SAG 适合规模化,主要靠几个工程特性。
chunk 天然并发
每个 chunk 的 event/entity 抽取可以独立进行。写入侧可以批量并发,不需要像全局图构建那样强依赖整体状态。
这对大规模数据处理很友好。尤其是企业知识库、用户记忆、工单、文档、邮件这类数据,新增频率高,批处理和流式写入都需要考虑。
实体复用靠 SQL
SAG 没有做特别重的 entity resolution。入库前做简单字符串归一,再通过 SQL 查重,同名同类型实体直接复用。
听起来有点粗糙,但符合它的设计定位:entity 是索引点,event 才承载主要语义。
如果把实体归一做得过重,系统会重新回到图谱工程那套复杂流程。SAG 的取舍是接受一定实体噪声,用 event 的语义完整性兜底。
关系都是局部的
新数据进来,只需要:
- 切 chunk;
- 抽 event;
- 抽 entity;
- 写入 event/entity/chunk 关系;
- 更新索引。
不需要重建全局图,也不需要跑全局 PageRank。
这就是它和重型 GraphRAG 的分界线。
GraphRAG 更像是在维护一套知识地图。 SAG 更像是在给每条数据加可 JOIN 的语义索引。
Zleap AI 团队提到,SAG 已经在 5 亿级数据规模的生产环境中稳定运行,在线检索延迟保持在秒级以内。这个量级至少说明,它不是只能停留在论文里的玩具方案。
同时团队提供了 Wikipedia Demo: https://wiki.zleap.com
Demo 支持快速模式和高精度模式。快速模式省掉 LLM 精排,更关注响应速度;高精度模式增加 LLM 重排序,更关注召回质量和最终证据排序。
七、为什么它适合 Agent
Agent 和普通 RAG 问答的最大差异,是检索会进入任务链路。
普通问答系统常见模式是:

Agent 更常见的是:

检索准确率会直接影响整条链路的稳定性。
如果第一次查错,Agent 会基于错误材料规划下一步。 如果第一次没查到,Agent 可能会换一个错误方向继续查。 如果每次都返回太多上下文,LLM 又会被噪声拖慢,甚至被无关信息带偏。
所以对 Agent 来说,更好的检索不是“尽量多给”,而是“尽早给对”。
SAG 的价值也在这里:
- Recall@2 提升,意味着更早拿到关键证据;
- 多跳扩展,意味着能沿实体关系继续找线索;
- event 保留上下文,减少碎片证据造成的误判;
- SQL 增量写入,适合持续增长的记忆和知识库;
- 快速/高精度模式,可以按场景在延迟和准确率之间切换。
Agent 记忆也是一个很适合 SAG 的场景。
长期记忆并不是一堆孤立文本。同一个用户、项目、偏好、任务,会在不同时间反复出现。新的记忆可能补充旧记忆,也可能修正旧记忆。
纯向量记忆更像是在找相似片段。但 Agent 真正需要的是知道:
- 哪些是历史背景;
- 哪些是当前状态;
- 哪些实体持续出现;
- 哪些事项之间存在时间顺序;
- 哪些旧结论已经被新事件覆盖。
SAG 的 event/entity 结构天然能承载这类信息。只要在 SQL 表里补上时间、来源、版本、状态字段,它就可以变成一种可持续更新的 Agent 记忆索引。
一个简化 schema 可以长这样:
-- 示意代码:SAG 风格的记忆表结构
CREATE TABLE events (
id BIGINT PRIMARY KEY,
chunk_id BIGINT NOT NULL,
summary TEXT NOT NULL,
occurred_at DATETIME,
source_type VARCHAR(64),
status VARCHAR(32),
embedding_id VARCHAR(128),
created_at DATETIME NOT NULL
);
CREATE TABLE entities (
id BIGINT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
type VARCHAR(64) NOT NULL,
normalized_name VARCHAR(255) NOT NULL,
created_at DATETIME NOT NULL,
UNIQUE KEY uk_entity (normalized_name, type)
);
CREATE TABLE event_entity_rel (
event_id BIGINT NOT NULL,
entity_id BIGINT NOT NULL,
role_description TEXT,
weight FLOAT DEFAULT 1.0,
PRIMARY KEY (event_id, entity_id)
);
这个结构不复杂,但它能回答很多纯向量库不好回答的问题:
- 某个用户最近提到过哪些项目;
- 某个项目的状态在过去一个月怎么变化;
- 某个产品决策关联了哪些人、会议和文档;
- 某个偏好是长期稳定的,还是最近刚出现的。
这类查询如果只靠向量检索,往往会变成“看起来相关”的文本堆叠。放到关系表里,很多问题反而简单了。
八、边界也要看清楚
SAG 很实用,但也不是所有 RAG 场景都该上这套结构。
如果你的场景只是简单 FAQ、单文档问答、政策条款检索,传统向量 RAG 可能已经够了。SAG 的离线抽取、event/entity 存储、SQL 扩展都会引入额外复杂度。
如果你的数据本身已经有很强 schema,比如 ERP、CRM、订单、库存、权限系统,直接 Text-to-SQL 或结构化查询可能更合适。没必要先把结构化数据转成文本,再抽 event/entity。
如果你的业务对实体消歧要求极高,比如医疗、法律、金融风控,SAG 的轻量实体归一可能不够,需要更严格的主数据管理、别名体系和审核流程。
比较合理的判断是:
| 场景 | 是否适合 SAG |
|---|---|
| 多文档多跳问答 | 很适合 |
| Agent 长期记忆 | 很适合 |
| 企业知识库持续增量写入 | 适合 |
| 简单 FAQ | 不一定需要 |
| 强结构业务数据库查询 | 优先考虑原生结构化查询 |
| 高精度实体主数据场景 | 需要补充更强实体治理 |
SAG 的工程意义,在于它找到了一条中间路线。
向量 RAG 太弱,GraphRAG 太重。SAG 没有试图把所有知识都整理成完美图谱,而是把每个 chunk 变成一个带实体索引的事项,再用数据库完成局部关系扩展。
这条路线的判断很务实: RAG 不一定需要一张昂贵的大图,但需要数据之间能被连接。 Agent 不一定需要一次拿回很多上下文,但需要尽早拿到正确证据。 生产系统不一定追求最精细的知识表示,但必须支持持续写入、持续更新、持续查询。
从这个角度看,SAG 真正带来的变化并不是“又一个 RAG 变体”,而是把 RAG 的核心问题往前推了一层:
数据进入 Agent 系统时,应该被组织成什么样?
SAG 给出的答案很明确:用 event 保留完整语义,用 entity 建立连接点,用 SQL 做多跳扩展。它没有把系统设计得很炫,但刚好抓住了 Agent 数据底座最现实的几个矛盾:准确率、增量更新、查询延迟和工程可维护性。[DONE]
