现在用 AI 学东西,门槛确实低了很多。以前一个概念卡住,可能要翻文档、搜博客、看视频;现在丢给 Claude,几秒钟就能得到一段看起来很顺的解释。
但这里有个很常见的问题:解释越顺,越容易让人产生“我懂了”的错觉。
很多人用 Claude 学习,实际是在做随机问答。想到什么问什么,看到答案点点头,收藏几个链接,过几天再回头,脑子里只剩一个模糊印象。这不是 Claude 不够强,而是学习过程本身没有结构。AI 给的是信息,理解要靠反馈、练习和回忆来建立。
所以,提示词的价值不只是“让 Claude 回答得更好”。更关键的是,把 Claude 放进一个学习系统里:它可以是老师、教练、考官、速查表生成器、资源过滤器,也可以是反复纠偏的陪练。
下面这 6 个提示词,适合用来学习几乎任何主题。技术、语言、设计、数据分析、产品方法,甚至一个新工具,都可以套进去。
一、先搭一条学习阶梯
很多学习失败,不是因为主题太难,而是路径太乱。
初学者最容易犯的错误,是太早冲进高级内容。比如刚学前端,就开始研究 React 性能优化;刚学机器学习,就看 Transformer 论文;刚学 Python,就想写自动化交易系统。结果是概念都见过,但没有一个真正踩实。
这类问题,最适合先让 Claude 帮你搭一条 learning ladder。
我想一步一步学习 [主题],不要跳过重要基础。
请你扮演一位专家老师和技能教练。把 [主题] 拆成 5 个清晰的难度等级,从完全新手到能够自信实践。
每个等级都请包含:
1. 等级名称
2. 这个阶段我应该理解什么
3. 达到这个等级的掌握标准是什么
4. 最重要的概念或技能
5. 一个能证明我可以进入下一阶段的里程碑
6. 一个动手练习或小项目
7. 学习者在这个阶段最常犯的错误
8. 进入下一阶段前的一个自测问题
请按照这个结构输出:
- Level 1:Complete Beginner(完全新手)
- Level 2:Basic Understanding(基础理解)
- Level 3:Practical User(实践使用者)
- Level 4:Problem Solver(问题解决者)
- Level 5:Confident Practitioner(自信实践者)
请保持解释实用、适合初学者,并专注于真实进步。不要塞太多理论。帮助我一层一层爬上去。
这个提示词的重点,不在于让 Claude 给你一份“知识目录”。
更有价值的是三件事:
| 维度 | 作用 |
|---|---|
| 等级划分 | 让你知道自己现在在哪一层 |
| 掌握标准 | 避免“看过就算会了” |
| 练习与里程碑 | 把学习变成可验证的过程 |
比如你用它学习 TypeScript,Claude 可能会把路径拆成:
- 能读懂基础类型
- 能给函数和对象建模
- 能理解泛型
- 能处理真实项目里的类型推导
- 能设计可维护的类型系统
这比直接问“TypeScript 怎么学”要靠谱得多。
工程里做系统设计时,最怕边界不清;学习也是一样。你不知道当前阶段该解决什么问题,就会不断被高级概念吸走注意力。学习阶梯的作用,就是先把边界画出来。
二、用 20 小时切入核心能力
有些主题不需要一上来就系统学习。
你可能只是想快速入门 Python,用它处理 Excel;或者想学一点数据分析,能看懂业务报表;或者想用 AI 工具提升写作和办公效率。这种情况下,追求“大而全”反而会拖慢进度。
更现实的做法,是先找出能产生 80% 效果的 20% 内容。
我想用 20 个专注小时学习 [主题]。
请你扮演一位专家老师和学习策略师。你的任务不是让我学完所有内容,而是先学最有用的部分。
请完成以下任务:
1. 找出能带来 80% 实际效果的 20% 核心概念、技能或原则。
2. 解释这些核心内容为什么重要,以及它们如何连接到真实使用场景。
3. 创建一个 10 节课的学习计划,每节课 2 小时。
4. 每节课都包含:
- 主要学习目标
- 需要学习的关键概念
- 一个实践练习或小项目
- 一个推荐资源,优先免费或适合初学者
- 完成这一节后的预期成果
5. 每节课结束后,给我 5 个复习问题,用来检查理解程度。
6. 完整计划结束后,设计一个最终项目,证明我已经能在真实场景中使用这个主题。
请保持计划适合初学者、实用,并专注于快速进步。
这个提示词适合解决“快速建立可用能力”的问题。
它有一个很重要的约束:不是学完整个主题,而是优先学最有用的部分。
这符合真实世界里的学习方式。工作中很少有人有时间完整啃完一门学科再开始使用。更多时候,是先建立最小可用能力,再在项目里补细节。
比如学习 SQL,20 小时内最重要的内容大概率不是数据库内核,而是:
SELECTWHEREJOINGROUP BY- 聚合函数
- 子查询
- 常见性能误区
- 用真实数据写分析查询
至于事务隔离级别、执行计划、索引结构,可以后面逐步补。不是它们不重要,而是学习阶段不同,优先级不同。
这里有个工程权衡: 快速入门路线会牺牲知识完整性,但能更快获得反馈。
如果目标是面试高级数据库岗位,这条路线显然不够;但如果目标是让运营同学能独立做基础数据分析,它反而更合适。学习计划要服务目标,不是服务知识体系本身。
三、让 Claude 当一个严格考官
被动阅读最容易制造幻觉。
你看懂了文章,划了重点,甚至还能说“这个我知道”。但只要让你关掉资料,自己解释一遍,问题就出来了。
这就是 active recall,主动回忆。
主动回忆不是重新看一遍,而是强迫大脑从内部取出信息。能取出来,说明有连接;取不出来,说明知识还停在熟悉感层面。
我刚学习了 [主题],现在想测试自己到底理解得怎么样。
请你扮演一位严格但有帮助的考试官。你的任务是通过 active recall(主动回忆)找到我理解的边界。
请先问我 10 个问题,一次只问一个。
规则:
1. 问题难度逐步增加:
- 第 1–3 题:beginner level(初级)
- 第 4–6 题:intermediate level(中级)
- 第 7–8 题:advanced level(高级)
- 第 9–10 题:expert level(专家级)
2. 每次只问一个问题,并等待我回答。
3. 每次我回答后,请做四件事:
- 给我的答案打分,满分 10 分
- 告诉我答对了什么
- 指出具体的缺口、错误或薄弱点
- 只重新解释我没掌握的那一部分,用简单语言说明
4. 如果我的回答很弱,先追问一个 follow-up question(追问问题),再进入下一题。
5. 如果我回答得很好,就稍微提高难度。
6. 最后请给我:
- 最终分数
- 我最强的部分
- 我最弱的部分
- 一个简短复习计划
- 5 个最终挑战题,帮助我真正掌握这个主题
不要一次性给出所有答案。请让整个过程像一次真实的学习面试。
这个提示词里最关键的设计,是“一次只问一个”。
很多人写提示词时,会让 AI 一次生成 20 道题和答案。看起来信息量很大,实际效果一般。因为你很容易跳过思考,直接看答案。
一次一个问题,等待回答,再反馈,这才像一个真正的测试闭环。
可以把这个过程看成一个简单的学习反馈系统:

它比“再看一遍资料”更有效,因为反馈更具体。
真正在生产环境里,很多问题也是这样暴露的。你以为自己理解了缓存,直到线上出现缓存穿透;你以为自己理解了异步,直到排查一个并发 bug。学习里提前做主动回忆,本质上是在用低成本方式暴露理解缺口。
四、生成一页速查表
速查表不是偷懒工具。
它的价值是压缩和恢复。把一个主题压缩成一页结构化信息,需要你抓住主干;在考试、面试、会议或写代码前快速扫一眼,又能帮助你恢复上下文。
尤其是那些规则多、细节杂、容易混淆的主题,cheat sheet 很有用。比如:
- Git 常用命令
- 正则表达式
- Docker 命令
- HTTP 状态码
- SQL Join 类型
- TypeScript 类型工具
- Prompt 编写原则
可以用这个提示词:
我想要一份关于 [主题] 的 one-page cheat sheet(一页速查表)。
请你扮演一位擅长把复杂概念讲简单的专家老师。
请创建一份我能在 5 分钟内快速复习的速查表,用于考试、会议、面试或实际使用前快速查看。
请包含:
1. 用简单语言解释这个主题的简短定义。
2. 最重要的概念、规则、公式或步骤。
3. 使用清晰 bullet points(项目符号),不要写成长段落。
4. 如果有帮助,请加入一个简单的 labeled diagram(标注图)、flowchart(流程图)、table(表格)或 mental model(心智模型)。
5. 给出 3–5 个真实例子,展示这个主题在现实中如何运作。
6. 常见错误或容易混淆的地方。
7. 一个 “Before You Use This(使用前检查)” 清单。
8. 5 个 rapid-fire questions(快速问答题),测试我的记忆。
请保持实用、视觉化、适合初学者,并且容易扫描。避免不必要理论。让它像一张浓缩学习地图,而不是一篇长解释。
这个提示词里,我比较看重三个要求:
- 不要写成长段落
- 加入真实例子
- 列出常见错误
因为速查表最怕变成“缩短版教材”。如果都是长段解释,它就失去了快速扫描的意义。
比如你让 Claude 生成一份 HTTP 缓存速查表,好的输出应该能迅速告诉你:
| 概念 | 作用 | 常见字段 |
|---|---|---|
| 强缓存 | 不请求服务器,直接用本地缓存 | Cache-Control, Expires |
| 协商缓存 | 请求服务器确认资源是否变化 | ETag, Last-Modified |
| 缓存失效 | 本地缓存过期或被策略绕过 | no-cache, no-store |
同时它还应该提醒你:
no-cache不是“不缓存”,而是每次使用前要向服务器确认no-store才是真的不存储ETag通常比Last-Modified更精细
这种东西在真实工作里很有价值。不是因为它讲得多,而是因为它帮你在关键时刻少犯错。
五、让 Claude 过滤信息噪音
现在学习资源的问题,已经不是太少,而是太多。
搜索一个主题,课程、视频、博客、电子书、路线图、付费社群全都涌出来。很多人学着学着,就变成了资源收集员。收藏夹越来越满,实际进度没怎么动。
这时候 Claude 可以承担一个角色:学习资源策展人。
我想快速学习 [主题],但不想把时间浪费在低质量资源上。
请你扮演一位专家学习策展人。帮我找到学习 [主题] 最值得投入时间的 5 个 high-leverage resources(高杠杆资源)。
资源可以包括 books(书籍)、videos(视频)、courses(课程)、websites(网站)、newsletters(通讯)、communities(社区)或值得关注的 experts(专家)。
每个资源请包含:
1. 资源名称
2. 资源类型
3. 为什么它值得我花时间
4. 它具体能帮我学习 [主题] 的哪一部分
5. 最适合哪类学习者
6. 难度等级:beginner(初级)、intermediate(中级)或 advanced(高级)
7. 我应该如何高效使用它
8. 一个提醒:不要把时间浪费在哪些部分
列完之后,请按最佳使用顺序对这些资源排序。
然后只使用这些资源,给我一个简单的 7-day learning path(7 天学习路径)。
请专注于质量、清晰度和实际用途。不要推荐太多资源。我想要 signal(信号),不是 noise(噪音)。
这里最好特别注意一句:不要推荐太多资源。
AI 很擅长生成列表,一不小心就给你 20 个链接、10 本书、8 个课程。看起来很丰富,但对学习不一定有帮助。资源越多,决策成本越高,行动越容易推迟。
所以这个提示词限制为 5 个高杠杆资源,是合理的。
不过这里也有一个现实边界:Claude 的资源推荐不一定永远最新,也可能混入过时内容。尤其是工具类、框架类、平台类主题,版本变化很快。
更稳妥的用法是:
- 让 Claude 给出候选资源
- 自己检查发布时间、维护状态、作者可信度
- 优先选择官方文档、经典课程、活跃社区
- 避免沉迷“别人整理好的路线图”
可以把资源过滤标准简单设成这样:
| 标准 | 判断方式 |
|---|---|
| 权威性 | 是否来自官方、核心贡献者或长期实践者 |
| 时效性 | 是否适配当前版本和生态 |
| 可操作性 | 是否有练习、案例或项目 |
| 难度匹配 | 是否适合当前阶段 |
| 信息密度 | 是否废话少、结构清楚 |
资源不是越多越好。真正有用的是:少量高质量资源,加上明确的使用顺序。
六、用费曼循环逼近真正理解
费曼学习法有点像学习里的单元测试。
你以为代码没问题,跑一下测试才知道边界条件炸了。你以为自己懂一个概念,试着用简单话讲出来,漏洞马上出现。
如果不能用简单语言解释一个概念,通常说明理解里还有没打通的地方。
这个提示词可以让 Claude 变成一个反馈循环:
我想用 Feynman learning method(费曼学习法)深入理解 [主题]。
请你扮演一位有耐心的老师。
首先,请用简单语言向我解释 [主题],就像我是一个 12 岁的学生。
请使用:
- 简单词汇
- 真实生活例子
- 类比
- 不使用不必要 jargon(专业术语)
- 简短解释
解释完之后,请让我用自己的话把这个主题讲回来。
然后请审查我的解释,并完成以下任务:
1. 指出我解释正确的部分。
2. 找出所有缺口、错误、混淆点或遗漏概念。
3. 只重新讲解我说错或漏掉的部分。
4. 再让我用更清晰的方式解释一遍。
5. 重复这个 loop(循环),直到我的解释变得简单、准确、完整。
规则:
- 在我的解释清楚之前,不要继续推进。
- 不要塞入额外理论。
- 温和但明确地纠正我。
- 当我困惑时,用例子帮助我。
- 最后,请给我一份可以保存为笔记的最终简洁解释。
请让整个过程像一次互动学习对话,而不是一场讲座。
这个提示词的设计很关键:它不急着推进新内容,而是反复修正当前理解。
很多学习计划的问题,是进度感太强。今天学 3 章,明天刷 20 个视频,后天开始看高级教程。进度看起来很漂亮,但理解质量很差。
费曼循环更慢,但它能把理解压实。
它适合这些场景:
- 学一个抽象概念,比如闭包、事务、向量数据库
- 准备面试,需要讲清楚原理
- 写技术文章前,检查自己有没有真懂
- 学完一节课后,把知识转成自己的语言
一个比较好的使用方式是:不要只让 Claude 解释,而是一定要自己讲回来。
如果少了“自己讲回来”这一步,费曼学习法就退化成普通解释了。
七、把 6 个提示词串成学习闭环
单独看,这 6 个提示词都能用。但更好的方式,是把它们组合起来。
一个完整的 Claude 学习流程可以这样设计:
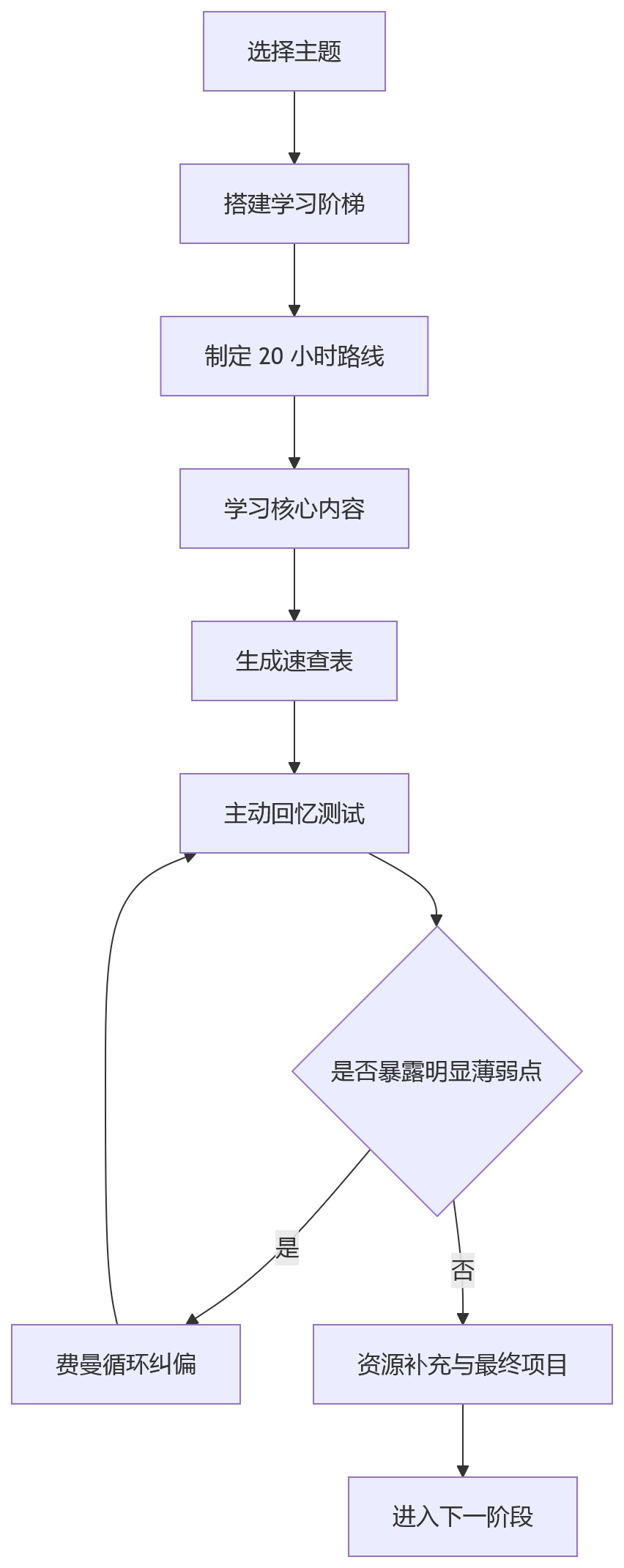
如果用更工程化一点的视角看,它其实是一个闭环系统:
| 环节 | 对应提示词 | 解决的问题 |
|---|---|---|
| 路径规划 | 学习阶梯 | 不知道从哪里开始 |
| 快速切入 | 20 小时路线 | 不知道先学什么 |
| 知识压缩 | 一页速查表 | 记不住、抓不住重点 |
| 理解验证 | 主动回忆测试 | 误以为自己懂了 |
| 资源过滤 | 高杠杆资源 | 信息过载 |
| 纠偏深化 | 费曼循环 | 解释不清、理解不稳 |
这里有个很实际的判断: Claude 最适合补足学习过程里的反馈环节,而不是替你完成学习本身。
它可以帮你拆路径、生成练习、设计问题、纠正表达、推荐资源。但真正让知识进入脑子的,还是你自己的回忆、解释、练习和输出。
如果只把 Claude 当搜索引擎,你会得到更多答案。 如果把它当学习系统的一部分,你才更可能形成能力。
八、一个更实用的使用建议
这些提示词不要一次全用。
更推荐按学习阶段选择:
| 你的状态 | 优先使用 |
|---|---|
| 刚接触一个主题 | 学习阶梯 |
| 想快速入门 | 20 小时路线 |
| 学完一部分但不确定掌握程度 | 主动回忆测试 |
| 准备考试、面试、会议 | 一页速查表 |
| 资料太多不知道看什么 | 高杠杆资源 |
| 概念总是说不清 | 费曼循环 |
另外,使用 Claude 学习时,最好每次都补充三个上下文:
我的当前水平:[完全新手 / 有一点基础 / 已经实践过]
我的学习目标:[考试 / 面试 / 工作使用 / 项目落地 / 兴趣了解]
我的时间限制:[例如 7 天、20 小时、每天 1 小时]
同一个主题,不同目标下的学习路径完全不同。
比如“学习 Docker”:
- 面试目标:要讲清镜像、容器、网络、Volume、Dockerfile
- 工作目标:要会写 Dockerfile、排查容器启动问题、处理日志和环境变量
- 架构目标:要理解容器编排、镜像仓库、CI/CD、Kubernetes 的关系
上下文给得越清楚,Claude 越不容易输出一份泛泛而谈的计划。
最后可以把这 6 个提示词理解成一组学习工具,而不是固定模板。真正有用的地方,不是它们写得多完整,而是它们把学习拆成了几个可操作的动作:
- 规划路径
- 聚焦核心
- 主动测试
- 压缩复盘
- 过滤资源
- 反复纠偏
AI 降低了获取信息的成本,但没有取消理解的成本。 会问问题只是开始,会设计反馈闭环,才是用 AI 学习真正拉开差距的地方。[DONE]