过去两年,RAG 解决了很多 LLM 落地早期的问题:模型不知道的知识,可以从外部知识库里捞回来;上下文窗口不够,就切块、召回、摘要、重排。那时大家关心的是“怎么把相关资料塞进去”。
但 Agent 走到长期运行之后,问题明显变了。一个长周期任务可能持续几十轮、几百轮,期间会访问网页、调用工具、生成中间结论、修正计划,还可能跨天继续执行。个人智能助手更麻烦,它要记住用户偏好、生活事件、关系网络,还要理解这些信息会随时间变化。
这时再把所有东西都丢进 Context,本质上是在把记忆问题外包给模型的注意力机制。短期看能跑,长期看会遇到成本、延迟、噪声和推理退化的连环问题。MAG,Memory-Augmented Generation,正是在这个背景下被推到台前。
一、RAG 的边界被长期任务撞开了
早期 RAG 的核心矛盾很清楚:模型参数里没有某些知识,或者知识过期了,就从外部文档里检索相关片段,再交给模型生成答案。
典型链路大概是这样:

这个架构在知识问答、客服、文档助手里仍然有价值。它便宜、简单、可控,工程落地门槛低。
问题出在 Agent 场景里。
Agent 不只是回答一个问题,而是在一个不断展开的任务空间里行动。它会产生中间状态,会犯错,会回滚,会根据新信息调整目标。于是上下文不再是几段参考资料,而变成一条持续膨胀的行为轨迹。
两年前,大家主要被上下文窗口卡住。信息太多,只能做摘要、截断、滑动窗口。后来长上下文模型越来越多,128K、1M 甚至更大的窗口让“放不下”这个问题缓了一口气。
但放得下,不代表用得好。
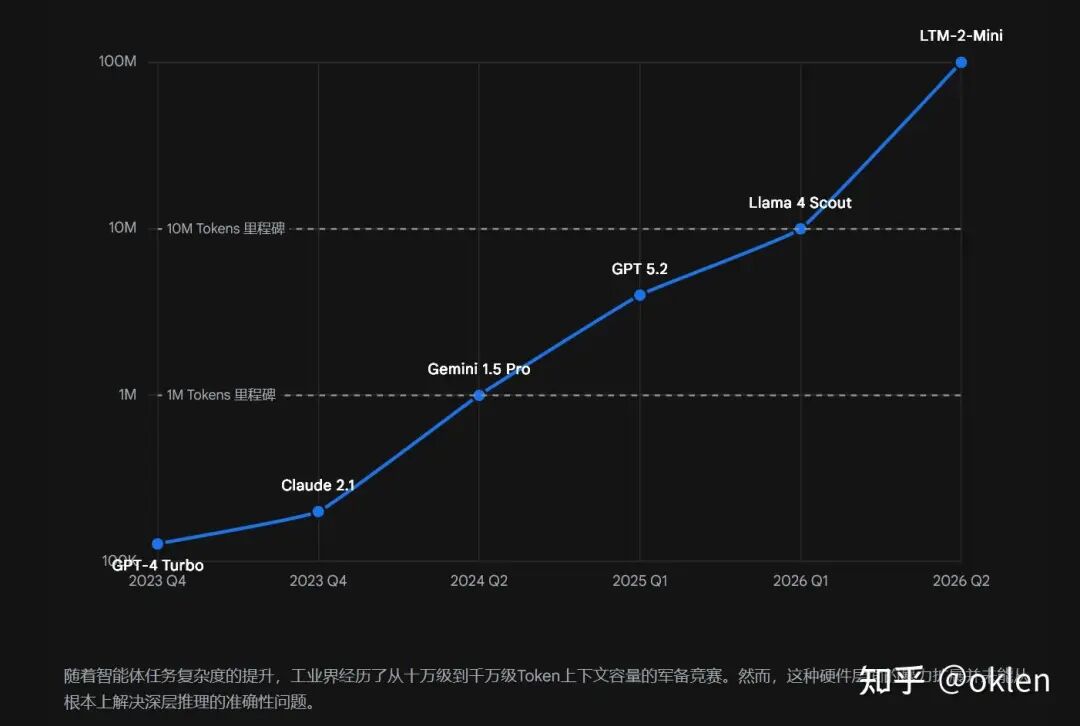
长上下文带来的第一个副作用是 Lost in the Middle。关键信息被淹没在大量片段中,模型很难稳定抓住真正有用的内容。后来长上下文训练、位置编码改进、检索增强注意力等技术把这个问题缓解了不少,很多“大海捞针”榜单也被刷得很高。
新的麻烦接着出现:Agent 的上下文接近无限,而且里面充满噪声。
一个 DeepResearch 类任务可能包含:
- 搜索 query 的演进过程
- 多轮网页抓取结果
- 工具调用日志
- 子任务计划
- 已废弃的假设
- 中间摘要
- 反复修订的结论
- 用户补充要求
- 多个 Agent 之间的协作记录
如果全部保留,模型会被迫在一堆历史垃圾里做复杂推理。即使基础模型长上下文能力不错,推理质量也会下降,Token 成本还会持续上升。
Context Caching 能降低重复前缀的算力成本和首字延迟,但它解决的是 Infra 层的账单问题。上下文里有多少噪声、哪些状态该保留、哪些经验该沉淀,这些问题仍然没有被处理。
这就是 MAG 的切入点:把“记忆”从被动拼接 Prompt,升级为一个可管理、可压缩、可演化的系统组件。
二、MAG 关注的是记忆生命周期
MAG 和 RAG 最大的区别,不在于是否检索外部信息,而在于它开始显式管理记忆的生命周期。
一个可用的 Agent Memory 系统,至少要回答几个问题:
| 问题 | RAG 常见处理 | MAG 更关心的方向 |
|---|---|---|
| 记什么 | 文档片段、FAQ、知识库内容 | 事实、事件、偏好、计划、状态、经验 |
| 怎么存 | 向量库切块 | 向量、图谱、日志、摘要、参数化记忆混合 |
| 何时取 | 用户提问时检索 | 任务规划、工具调用、反思、生成前动态读取 |
| 怎么忘 | 很少处理,最多删除文档 | 过期、冲突、低价值、隐私敏感内容主动淘汰 |
| 怎么更新 | 重新入库或重建索引 | 流式更新、置信度演化、偏好漂移跟踪 |
| 怎么验证 | 相关性评分 | 一致性、时效性、因果链、可追溯性 |
这里面最难的是“记忆不是静态知识”。
文档知识库通常是相对稳定的,更新频率有限。而 Agent 的记忆更像运行时状态和长期经验的混合体。今天形成的结论,明天可能被新证据推翻;用户上个月的偏好,本周可能已经变化;一次失败的工具调用,也许下次能避免同样的坑。
所以 MAG 不是单纯把 RAG 做大,而是把 Agent 的上下文管理从“检索问题”推进到了“状态管理问题”。
从工程视角看,这个变化很关键。因为状态管理通常意味着复杂度上升:一致性、版本、淘汰策略、冲突合并、观测与回放都会冒出来。很多团队做到这里会卡住,不是模型不够强,而是系统没有把记忆当一等公民设计。
三、长周期任务里的上下文腐烂
复杂长周期任务是 MAG 最先被逼出来的场景之一。
以 DeepResearch 为例,系统要在大量资料中持续探索,并完成多跳推理。它关心的不是“某个片段里有没有答案”,而是多个证据之间如何形成链路。
暴力长窗口在这里很容易失效。原因有三个。
第一,信息密度太低。
长周期任务的上下文里,大量内容是中间过程:失败搜索、重复网页、无关段落、旧版本计划。它们曾经有用,但到了后续阶段已经变成噪声。
第二,复杂推理会被噪声拖垮。
很多长上下文评测测试的是“能不能找到针”,但真实任务经常是“找到几根针以后,判断它们之间的关系”。这对模型的要求高很多。上下文越乱,模型越容易把弱相关信息误当证据。
第三,成本曲线不友好。
长上下文不只是贵一点。对多轮 Agent 来说,每一步都带着膨胀的历史继续推理,成本会滚雪球。缓存可以缓解一部分,但不能改变输入越来越脏的事实。
这类现象现在常被叫做 Context Rot,上下文腐烂。名字有点狠,但很贴切:上下文并不是越长越好,未经整理的上下文会逐渐腐败,最后影响模型判断。
四、从切块检索到交互式阅读
针对超长文档,传统 RAG 的切块方式有个天然缺陷:它把连续逻辑切碎了。
一个复杂论证可能跨越几十页,前面定义概念,中间给出假设,后面才出现结论。单独召回某几个 chunk,Embedding 相似度可能够高,但逻辑链是断的。
MemWalker 这类交互式阅读架构提供了一个很有意思的方向:不要让模型一次性吞完整文档,而是先把长文本组织成可导航的结构,再让 LLM 像读者一样在结构里游走。
它的基本思路可以抽象成两层:
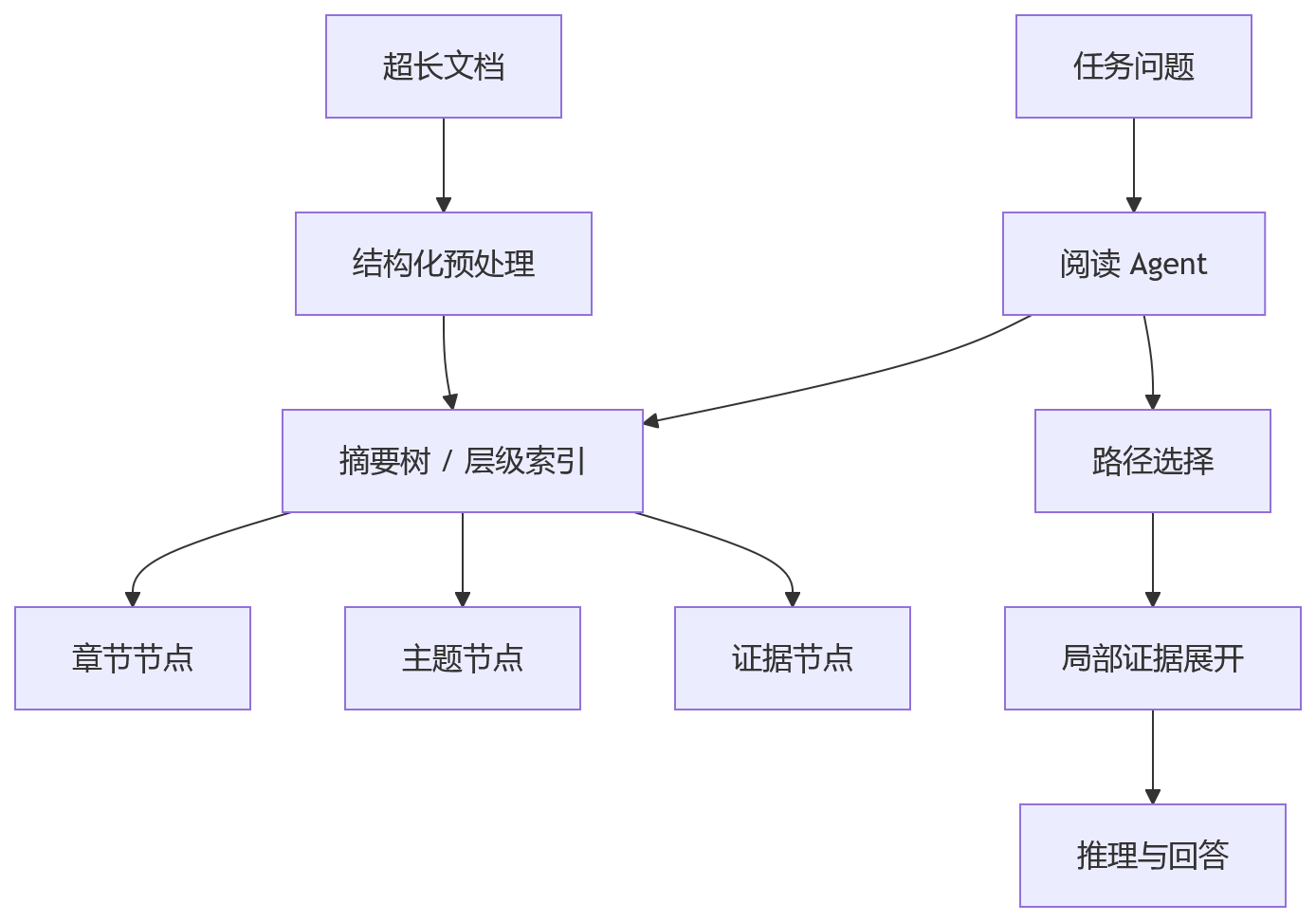
这比平铺向量检索更接近人类读长文档的方式。先看目录和摘要,判断应该钻到哪里,再局部细读。
但它不是银弹。
这类架构很吃模型的指令跟随能力和规划能力。节点摘要要稳定,路径选择要可靠,遇到不确定信息还要能回退。模型稍弱一点,可能在树上走着走着就偏了。
另一个工程问题是结构生成成本。面对千万 Token 级别的代码仓库、法务材料或科研资料,树节点本身也可能爆炸。生成、更新、合并、缓存都要设计好,否则索引还没用上,预处理成本已经压垮系统。
这里的取舍很现实:
- 平铺 RAG 便宜、快、好维护,但深层结构弱;
- 层级阅读推理质量更好,但构建成本和运行时复杂度更高;
- 在强约束生产环境里,通常需要先判断任务价值,再决定是否值得做重型结构化。
五、GraphRAG 重新组织多跳关系
当任务需要跨文档、多实体、多关系推理时,图结构的价值会变得明显。
纯向量检索依赖语义相似度。它擅长找“看起来相关”的片段,却不擅长表达“谁影响了谁”“哪个事件发生在前”“两个实体之间经过哪些中间节点连接”。
GraphRAG 的思路是把文本中的实体、关系和社区结构提前抽取出来:

这带来了一个重要变化:Agent 不再只是在向量空间里找相似片段,而是可以沿着关系边做路径遍历。
比如一个科研综述任务要回答“某类方法为什么在某个阶段性能突然提升”,纯向量检索可能召回一堆论文摘要。图结构则可以把模型架构、数据集、评测指标、发布时间、引用关系连起来,让 Agent 从“现象”走到“原因链”。
常见做法包括:
- 抽取实体:论文、模型、数据集、任务、机构、指标;
- 抽取关系:提出、改进、引用、评测于、优于、失败于;
- 聚类社区:把相关方法族组织成社区;
- 为社区生成- 查询时结合图遍历和局部文本证据。
GraphRAG 的优势很清楚:多跳推理、全局总结、关系解释都更强。
代价也不小。
图谱构建依赖抽取质量,LLM 抽关系会带入偏差;本体设计太粗,图没用,太细,维护成本爆炸;动态数据进来后,增量更新和冲突合并也很麻烦。
所以 GraphRAG 更适合高价值、强结构、需要可解释链路的任务,比如企业知识库、科研分析、投研、法务、代码依赖分析。对于普通 FAQ 或低复杂度问答,上来就搞图谱,很可能是架构过度设计。
六、几类记忆架构的工程取舍
长期 Agent 的 Memory 很难靠单一架构解决。不同记忆形态对应不同问题。
| 架构流派 | 典型模式 | 核心优势 | 长周期失败模式 |
|---|---|---|---|
| 纯向量检索 | 平铺向量 RAG | 部署简单,并发高,延迟低 | 语义漂移明显,难表达深层关系 |
| 层级调度 | 分层摘要、MemGPT 类机制 | 高价值信息可复用,适合有限窗口管理 | 淘汰策略出错会丢关键状态 |
| 图谱结构 | GraphRAG、知识图谱 | 适合多跳关系和全局总结 | 构建开销大,本体设计复杂 |
| 时序网络 | 时序知识图谱 | 适合状态连续演化和因果追踪 | 依赖 Schema,流式清洗要求高 |
| 事件日志 | 工具调用与检查点 | 可回放、可审计、适合故障恢复 | 日志膨胀快,缺少语义压缩 |
| 情节记忆 | 跨任务经验片段 | 适合经验复用和模式识别 | 边界难切,跨场景容易失真 |
| 参数化记忆 | LoRA / 小模型微调 | 调用快,隐式吸收高频知识 | 更新风险高,容易遗忘或污染 |
这里有个很重要的工程判断:记忆系统要分层。
把所有东西都塞进一个向量库,看起来简单,后期会越来越痛。任务状态、事实知识、用户偏好、执行日志、长期经验,本来就有不同的生命周期。
一个更稳的设计通常会拆成几条线:
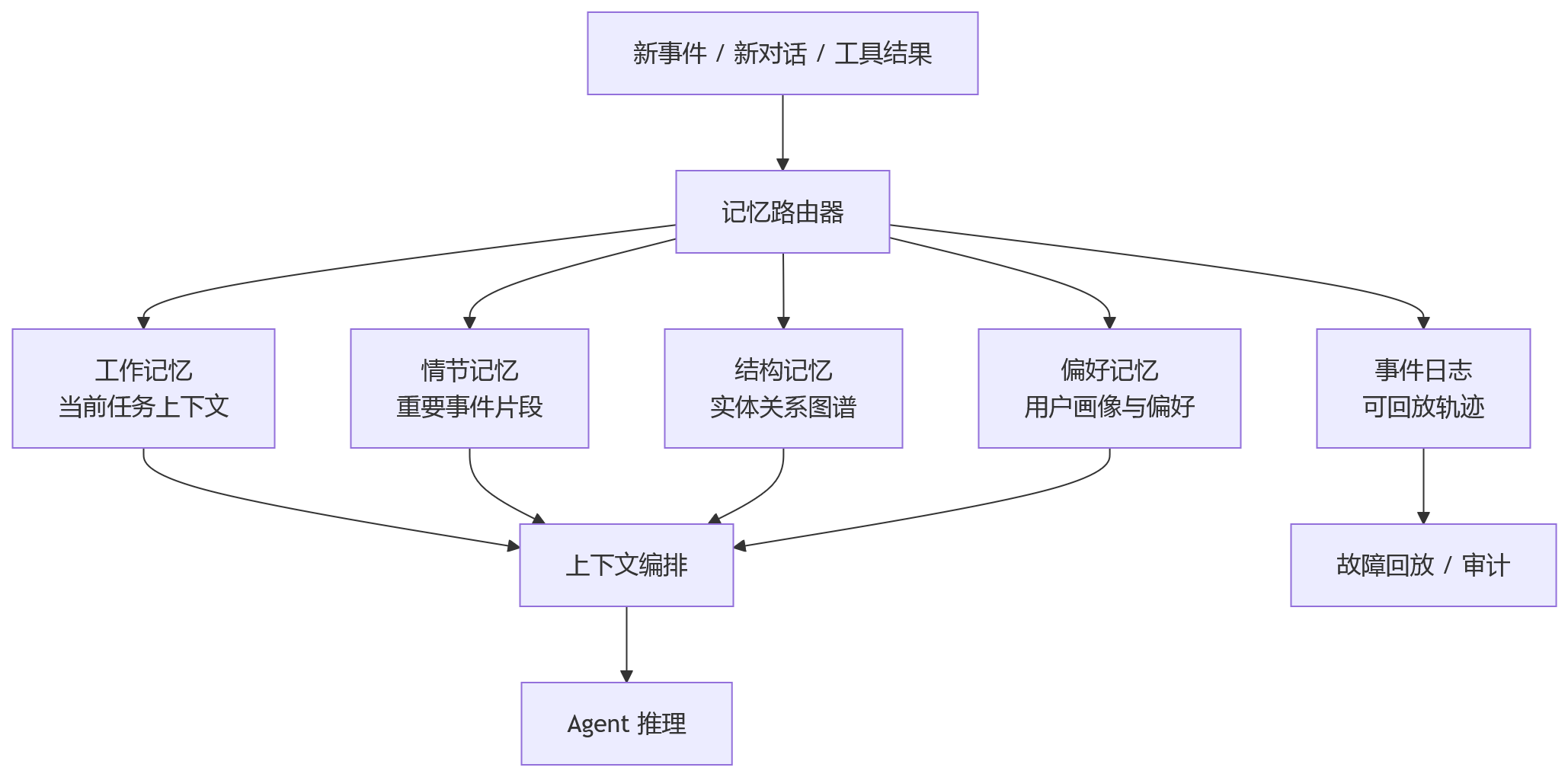
这套设计看起来复杂,但它解决的是长期可维护性问题。
工作记忆负责当前任务,不应该无限增长;事件日志负责审计,不应该直接喂给模型;图谱负责关系,不适合存所有原始细节;偏好记忆要关注时效性,不能把三年前的偏好当成今天的事实。
很多 Agent 项目跑到后期会出现“记忆越多越笨”的现象,根因往往是没有区分这些层。
七、上下文工程会成为 Agent 的核心能力
现在越来越多团队开始用 Context Engineering 这个词。它听起来像 Prompt Engineering 的升级版,但实际更接近一套运行时资源调度系统。
关键动作包括:
- 根据任务阶段选择不同记忆源;
- 对已完成子任务做高密度摘要;
- 把失败路径和废弃假设降权;
- 对关键事实保留可追溯证据;
- 对用户偏好做时效判断;
- 在生成前控制上下文长度和信息密度;
- 在任务结束后沉淀长期记忆。
这和操作系统的内存管理有点像。不是所有数据都能放进高速缓存,也不是所有历史都值得常驻内存。真正难的是调度策略。
一个长周期 Agent 可以采用类似下面的流程:
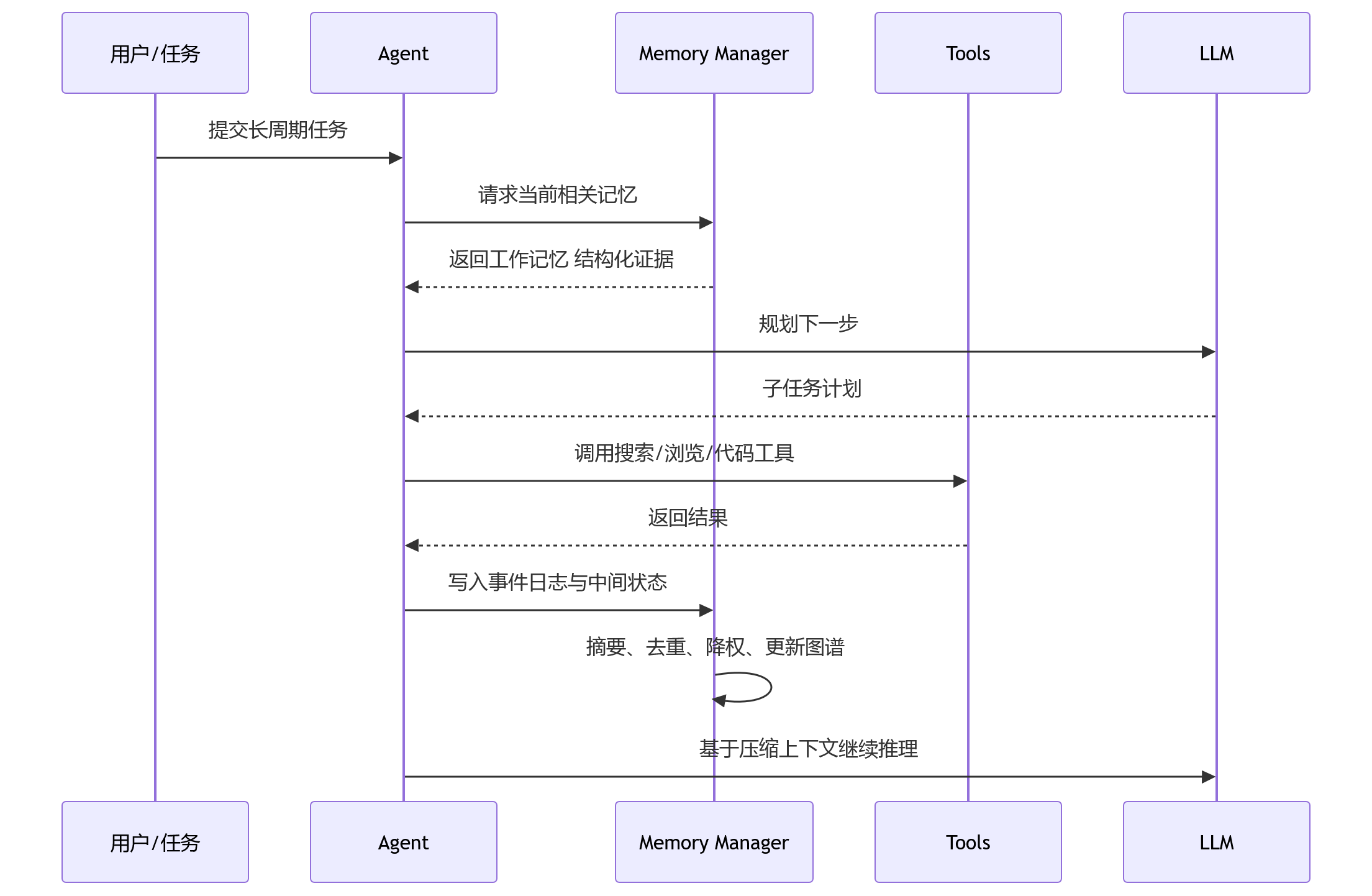
这里的核心不在于摘要本身,而在于“什么时候摘要、摘要到什么粒度、哪些信息必须保留原文证据”。
过早摘要会丢细节,过晚摘要会污染上下文。摘要太粗,后续推理缺证据;摘要太细,压缩效果差。实际工程里通常要按任务类型调策略,没有一套参数能通吃。
八、个人助手的记忆更难,因为人会变
个人智能助手是另一类高优场景。
长周期研究任务的问题偏理性:证据、计划、推理链。个人助手的问题更碎,也更敏感。它要处理日常对话、邮件、日程、位置、消费、联系人、偏好、情绪,还要避免把用户不想被记住的信息长期保存。
传统 RAG 在这里会暴露两个典型问题。
第一个是语义依赖失效。
用户可能问:
咱们去日本旅行时给老妈买的礼物放哪了?
这句话里没有商品名,也没有明确日期。纯向量检索很难靠表面相似度定位到“2023 年 4 月日本旅行”“给母亲买珍珠项链”“回家后放在书房抽屉”这些分散事件。
更合理的做法是构建个人知识图谱:
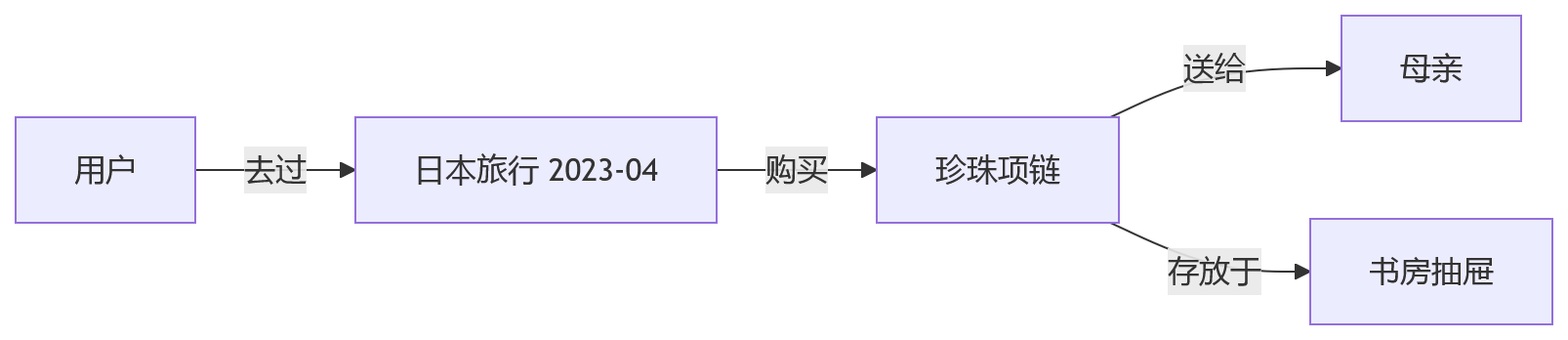
LLM 在这里承担两个角色:
- 后台抽取器:从日常对话和事件中抽实体、关系、时间;
- 前台推理器:根据模糊问题在图谱上做多跳查询。
第二个问题是偏好漂移。
人不是配置文件。用户以前喜欢冰美式,现在可能改喝茶;过去偏好高频通知,现在可能希望安静;某些饮食禁忌也可能随健康状态变化。
如果系统只会把历史记录切片召回,就容易把旧经验当成当前偏好。这个问题在个人助手里很致命,因为它会显得固执、不敏感,甚至冒犯用户。
处理偏好漂移通常有几种路线:
| 方案 | 优点 | 代价 |
|---|---|---|
| Prompt 动态注入 | 易落地,适合闭源 API | 占窗口,复杂偏好容易冲突 |
| Reranker 重排 | 对现有系统侵入小 | 只能影响候选结果,不能深层改变生成倾向 |
| 用户画像图谱 | 可解释,适合长期维护 | 抽取和更新策略复杂 |
| Decoding 阶段干预 | 低延迟个性化强 | 需要白盒模型和推理引擎支持 |
| 个性化 LoRA | 高频偏好可内化 | 更新成本、遗忘风险、隔离治理要求高 |
一些 Drift 类方法尝试把偏好对齐下放到解码阶段。它会根据用户近期交互估计偏好方向,在模型生成 Token 时调整 logits,让输出更贴近用户当前状态。
这个思路很优雅,但工程限制明显:它通常需要白盒模型访问能力,也考验推理引擎对自定义算子的支持。对于闭源 API 或极高并发云端服务,动态 Prompt、轻量画像和重排仍然是更稳的妥协。
这就是典型的工程 trade-off:白盒个性化效果好,但基础设施要求高;黑盒 API 接入快,但个性化只能在外围绕一圈。
九、混合记忆系统会成为主流形态
真正落地的 Agent Memory,大概率会走向混合架构。
单一向量库不够,纯图谱太重,全部微调风险太高,事件日志又太原始。合理的系统会把不同记忆放在不同层里,再通过 Memory Manager 做统一调度。
一个企业级或个人级 Agent 的混合记忆系统,可以大致分成五层:
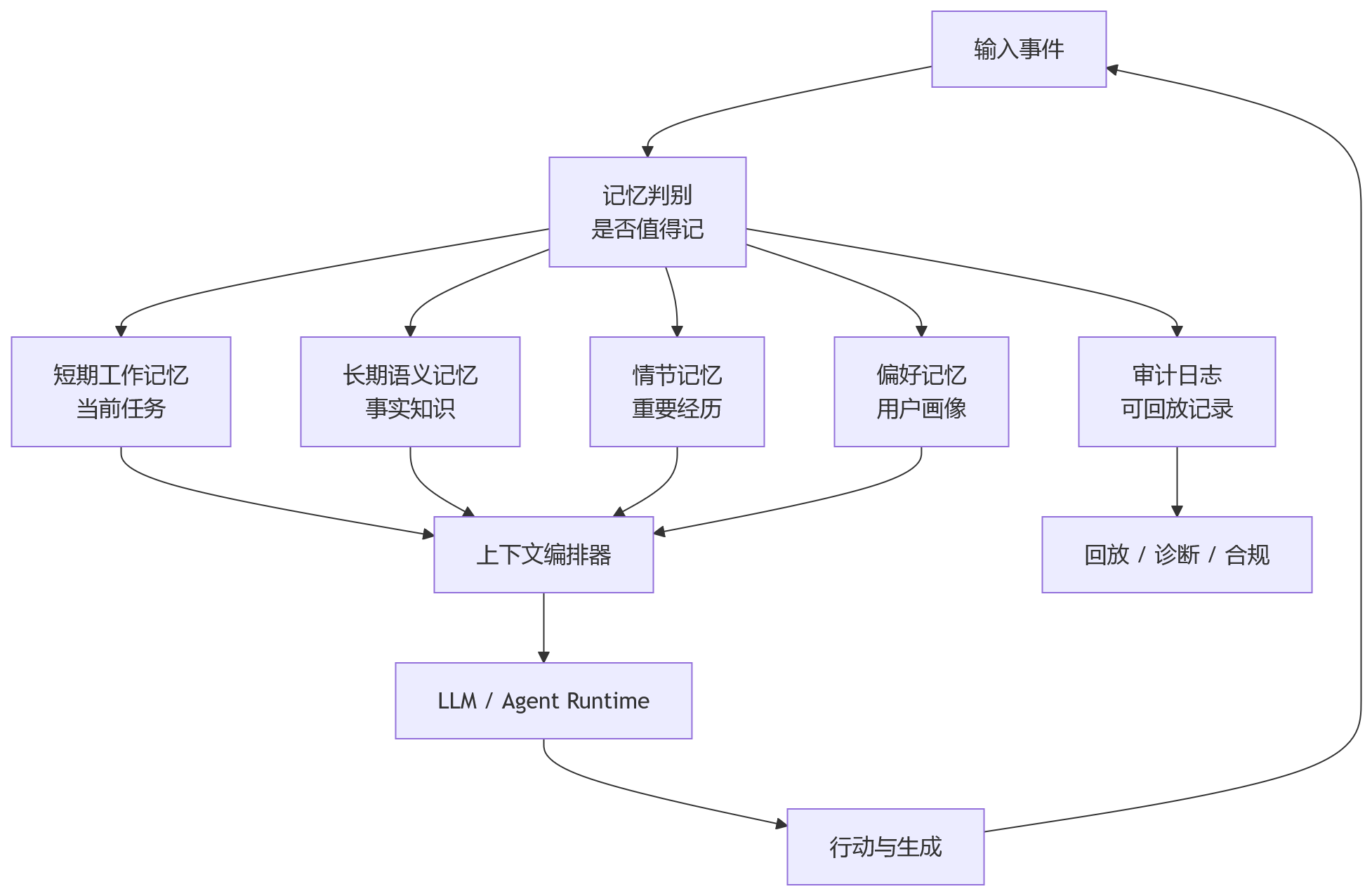
这里有几个细节很容易被低估。
第一,记忆写入要有门槛。
不是每句话都值得长期保存。否则系统很快变成垃圾场。写入策略要考虑频率、重要性、置信度、隐私敏感度和未来可用性。
第二,记忆读取要有预算。
给模型的上下文应该是被编排过的,不是把所有相关结果一股脑塞进去。读取阶段需要排序、压缩、冲突检测和证据绑定。
第三,记忆更新要处理冲突。
用户说“我现在不喝咖啡了”,这不是新增一条偏好那么简单。它应该降低旧偏好的权重,标记时间范围,甚至触发相关推荐策略更新。
第四,记忆删除要被认真设计。
个人助手绕不开隐私和合规。用户要求删除某段记忆时,系统不仅要删除向量库记录,还要处理摘要、图谱边、缓存、日志可见性和可能的参数化记忆影响。
十、参数化记忆的诱惑与风险
外部记忆再怎么优化,也有一个物理限制:检索、排序、拼接、推理都要时间。对于高频、稳定、强个性化的知识,把它内化到模型参数里很有吸引力。
MemVerse 这类思路代表了一个方向:Agent 在低负载时,从外部多模态记忆中抽取训练样本,通过周期性蒸馏或 SFT,把一部分长期经验压进轻量模型或用户专属适配器里。

从架构上看,它像一个快慢系统:
- 慢系统:外部图谱、日志、文档,负责可追溯和深度推理;
- 快系统:参数化记忆,负责高频事实和个性化直觉调用。
这个设计有吸引力,但风险也大。
微调不是简单缓存。它会改变模型行为。新知识写进去以后,可能覆盖旧能力,这就是连续学习里的灾难性遗忘。更麻烦的是,错误记忆一旦参数化,排查和删除都比外部数据库困难得多。
比较稳的工程路线通常不会直接污染大模型底座,而是采用隔离层:
- 用户级 LoRA Adapter;
- 端侧小模型个性化微调;
- 可回滚的 Adapter 版本;
- 经验回放缓冲区;
- EWC 等连续学习约束;
- 参数化记忆与外部证据的双轨校验。
这里要区分在线和离线。
实时交互阶段,需要低延迟,适合 Prompt 动态编排、Reranker、解码期干预。低负载阶段,可以做异步蒸馏或小规模适配器更新。白天靠快速调度,晚上做低成本巩固,这比每次交互都尝试训练模型现实得多。
十一、Memory 系统最终会走向自优化
当记忆系统变复杂后,靠人工调参数会越来越吃力。
召回失败、图谱边错误、摘要丢关键信息、偏好更新不及时、日志回放成本过高,这些问题都需要持续诊断。更前沿的方向是让 Agent 参与 Memory 架构本身的优化。
比如一个自治研究管道可以做这些事:
- 分析失败回答对应的召回链路;
- 发现某类实体抽取遗漏;
- 调整图谱 Schema 或关系权重;
- 修改摘要策略;
- 为高频失败 Query 增加专门索引;
- 自动生成评测集回归测试;
- 对 Memory 写入规则做 A/B 验证。
这类系统听起来有点“AI 自己改 AI”,但落到工程上并不玄。它更像自动化运维和 AutoML 的结合:让模型负责提出候选改动,人或安全策略负责审核和放行。
真正要警惕的是闭环污染。Agent 如果基于错误答案更新记忆,再用错误记忆指导下一轮推理,会形成自我强化的错误链。Memory 自优化必须配套评测、版本、回滚和审计,否则系统会越来越自信,也越来越偏。
十二、落地 MAG 时先想清楚边界
MAG 的价值很大,但它不是所有场景都需要。
如果你的业务只是标准知识问答,文档规模有限,问题也不需要跨文档推理,传统 RAG 加重排和少量摘要就够了。过早引入图谱、长期记忆和个性化微调,只会增加维护成本。
如果你的 Agent 满足这些特征,MAG 才真正值得投入:
- 任务持续时间长,历史状态会影响后续决策;
- 需要跨多文档、多实体、多轮工具调用推理;
- 用户偏好会长期影响输出;
- 系统需要可回放、可审计、可解释;
- 上下文成本已经明显影响体验或账单;
- 旧经验能提升后续任务效率。
比较务实的演进路径是:
- 先把事件日志打全,保证可观测和可回放;
- 再做工作记忆压缩,避免上下文失控;
- 对高价值实体关系引入轻量图谱;
- 对用户偏好做时效建模和冲突处理;
- 最后再考虑参数化记忆和自动优化。
Agent 的长期记忆架构,本质上是在有限上下文、有限算力和不断变化的信息之间做调度。RAG 解决了“去哪找资料”,MAG 要解决的是“什么值得记、何时该忘、如何让记忆服务推理”。
这一步看起来没有模型参数增长那么性感,却更接近 Agent 真正进入生产环境后必须面对的问题。长期运行的智能体,拼到最后不是谁能塞进更多 Token,而是谁能把记忆管理得足够干净、稳定、可控。[DONE]