你坐在电脑前干活,旁边有个东西一直看着你。你点了哪个按钮,填了哪些字段,在哪个页面停了一下,它都记下来。等你做完,它把这套流程整理成一个可复用的技能,下次你只要告诉它这次的输入变了哪里,它自己把活跑完。
这就是 Codex 新发布的 Record & Replay。
这个功能看起来像“录屏 自动回放”,但如果只这么理解,会低估它的意义。它真正指向的是另一件事:过去很多自动化依赖 API、脚本和结构化接口,现在 AI 开始尝试直接学习人类操作软件的方式。图形界面,这个原本为人设计的交互层,正在变成 AI 获取软件能力的一条入口。
一、适合录下来的不是所有操作
Record & Replay 瞄准的不是所有桌面任务,而是那些“重复、繁琐、带个人偏好,但又很难完整写成文档”的流程。
比如:
- 报销单填写;
- 订停车位;
- 创建符合团队规范的 issue;
- 上传视频并配置元数据;
- 拉周期性运营报表;
- 在内部系统里完成一串跨页面操作。
这些任务有个共同点:步骤通常不复杂,但细节很多。
真正麻烦的地方往往不是“点哪个按钮”这么简单,而是:
- 文件名怎么写;
- 某个字段默认填什么;
- 遇到多个选项时按什么规则选择;
- 哪些输入每次会变;
- 哪些配置是团队约定;
- 做完后怎么判断结果是对的。
这类知识很难靠一段 prompt 讲清楚。你当然可以写一份 SOP,但写过的人都知道,SOP 一旦涉及界面、账号、表单、异常分支,很快就会膨胀成没人愿意维护的文档。
Record & Replay 选择了一条更接近人类学徒的路径:你做一遍,它看一遍,再把过程抽象成一个 skill。
从产品流程看,它并不复杂。
你先在 Codex 应用里打开 Plugins,搜索并添加 Record & Replay 插件。
然后授权录制。
接着在 Mac 上正常把任务做一遍。
这期间 Codex 会观察你的窗口、鼠标、键盘、页面状态和上下文变化,捕捉流程里的关键动作。
任务完成后,你从菜单栏或悬浮层停止录制,也可以直接告诉 Codex 已经录完。
录制结束后,Codex 会复盘刚才的操作,并起草一个 skill。这个 skill 通常会包含几类信息:
- 什么时候应该使用这套流程;
- 执行前需要哪些输入;
- 每一步大致怎么做;
- 哪些地方需要根据当前任务调整;
- 完成后如何验证结果。
这里有一个细节很关键:skill 不是传统意义上的“固定脚本”。
固定脚本关心的是确定性输入、确定性路径和确定性输出。一旦页面结构变了、按钮位置变了、输入文件换了,脚本就容易崩。Record & Replay 生成的 skill 更像是一份可复用上下文。它告诉模型“这个任务应该如何完成”,但执行时仍然会结合当前页面、当前文件、当前对话里的输入做判断。
这也是它比普通宏录制更有想象空间的地方。
二、它复现的是流程,不是鼠标轨迹
很多人看到 Record & Replay,第一反应会想到 RPA 或者按键精灵。这个联想没错,但也不完整。
传统桌面自动化通常有几种路线:
| 方案 | 工作方式 | 优点 | 问题 |
|---|---|---|---|
| 脚本/API | 调用结构化接口 | 稳定、快、可测试 | 依赖接口开放 |
| RPA | 基于 UI 元素或坐标操作 | 能覆盖无 API 系统 | 对界面变化敏感 |
| 宏录制 | 记录鼠标键盘动作 | 上手简单 | 泛化能力弱 |
| Record & Replay | 观察人类操作并生成 skill | 能沉淀流程语义 | 执行速度和可靠性仍受 GUI 约束 |
Record & Replay 的目标不是精确复刻你鼠标移动了多少像素,而是从你的操作中抽取流程语义。
比如上传 YouTube 视频的演示里,Codex 观察的是一整套任务:
- 选择视频文件;
- 填标题和描述;
- 上传缩略图;
- 添加字幕;
- 设置隐私选项;
- 处理视频文件和字幕文件的对应关系;
- 根据任务目标选择 Private 或 Unlisted;
- 在出现环境问题时寻找可用替代路径。
如果只是录鼠标轨迹,这套流程几乎没有复用价值。因为下次视频文件名会变、标题会变、字幕文件会变,甚至 YouTube Studio 的界面状态也可能不同。
真正有价值的是把这些操作抽象成:
- 这个任务需要一组视频资产;
.mp4和.srt之间存在配对关系;- 标题、描述、缩略图、隐私设置属于可变输入;
- 某些配置有默认规则;
- 结束时要确认上传状态和配置结果。
这类信息才是工作流的骨架。
所以更准确地说,Record & Replay 不是把电脑操作录成录像,而是把一次操作转译成 AI 可执行的工作流描述。
这会带来一个工程上的权衡:它比纯 API 慢,也更容易受界面变化影响,但它能覆盖大量没有 API、API 不完整、或者根本没法接入的系统。
在企业里,这类系统非常多。老后台、内部管理台、供应商系统、财务系统、CRM、各种低代码平台,很多都不是为了自动化友好而设计的。你想让它们开放 API,排期可能排到明年;你想靠人手操作,又耗时间。GUI 自动化虽然不优雅,但在现实里经常是唯一能跑通的路。
这就是它的实际价值。
三、Computer Use 是底层抓手
Record & Replay 能成立,前提是 Codex 已经具备“用电脑”的能力。
OpenAI 工程师 Jason 曾经梳理过 Codex 操作电脑的几条路径,大致可以分成三类:Computer Use、Chrome 扩展、应用内浏览器。再加上 Appshot 这种“指向上下文”的机制,它们共同构成了 Codex 理解和操作软件环境的能力层。
这里可以用一张简单的图看它们的关系:
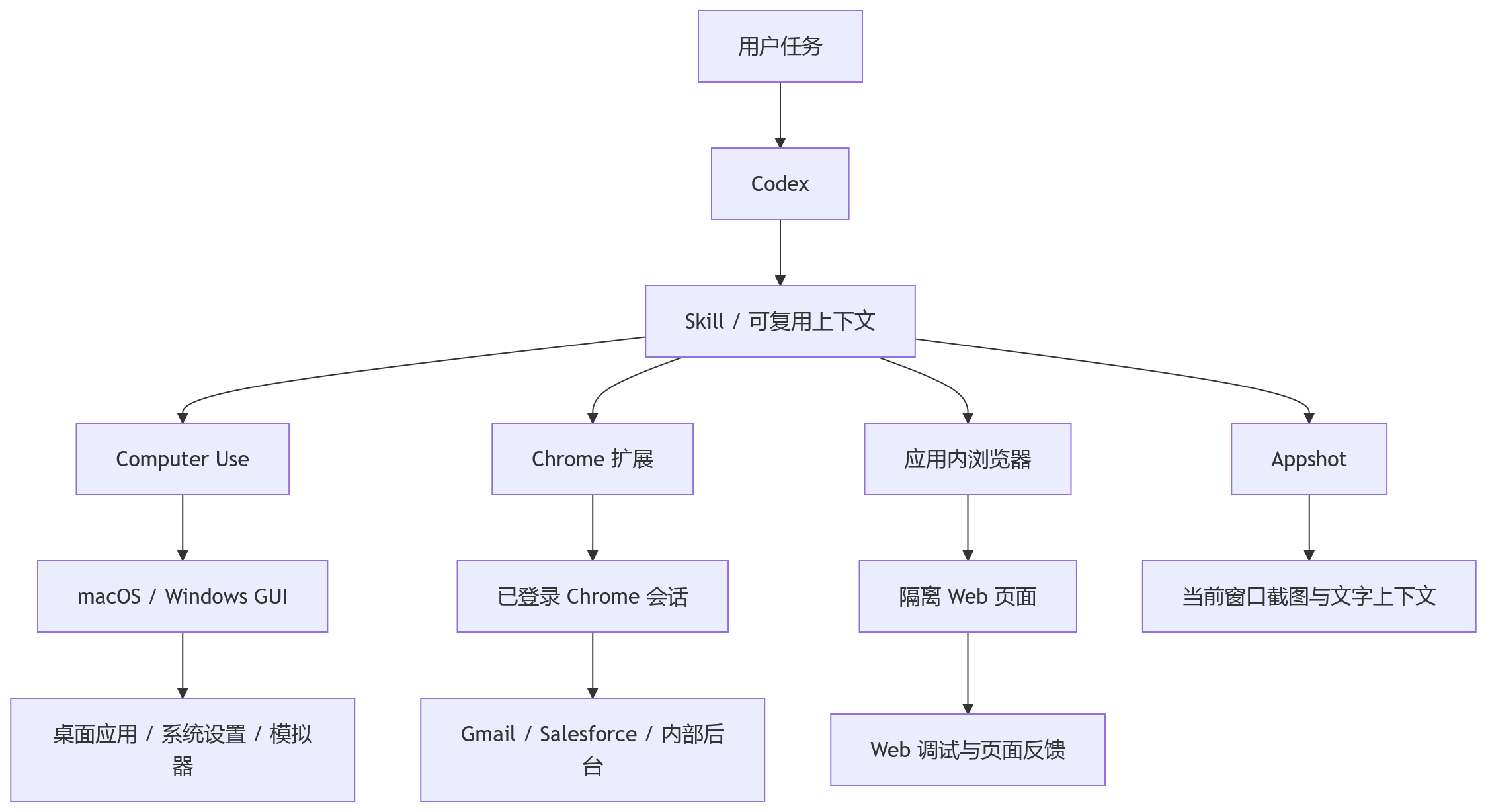
第一条路是 Computer Use。
它能在 macOS 和 Windows 上观察并操作图形界面,通过窗口、菜单、键盘、鼠标和剪贴板去控制授权过的应用。
它的覆盖面最广。没有 API 的桌面应用、系统设置、开发工具、模拟器,甚至通过 iPhone 镜像操作手机界面,这些都属于 Computer Use 的能力范围。
代价也很明显:慢。
AI 要看界面,判断状态,点一下,等页面响应,再确认结果。它不像 API 调用那样一次请求拿到结构化返回值,而是在一个不够稳定的视觉环境里持续试探。
这也是 GUI 自动化天然的工程成本。界面可能延迟,弹窗可能打断,按钮文案可能变,窗口焦点可能丢。真正在生产环境里,麻烦往往出在这些边角状态,而不是主流程。
第二条路是 Chrome 扩展。
它接管你已经登录好的 Chrome,适合处理依赖账号、cookie、认证会话的网站任务。比如 Gmail、Salesforce、企业内部仪表盘、后台系统。
它比纯视觉控制更贴近浏览器上下文,能理解多标签页,也能利用当前登录状态。但边界也更敏感:它带着你的身份在操作。发送邮件、提交表单、发布内容、购买、转账,这些动作都应该保留人工确认。
第三条路是应用内浏览器。
它运行在 Codex 对话内部,适合开发调试 Web 应用。它隔离你的真实浏览器环境,不碰你的 cookie、扩展和登录态。对于开发者来说,这个边界很有用。AI 可以改代码、打开页面、截图、定位问题、再改一轮,形成一个比较紧的反馈环。
Appshot 则更像上下文入口。
它不直接操作电脑,而是把当前窗口的视觉和文字信息交给 Codex。比如你看到一个报错、一封邮件、一个复杂表单,连按两下 CMD 键,把窗口内容送进对话里,AI 就能围绕它分析和回答。
Record & Replay 依赖的核心还是 Computer Use。录下来的 skill 要能复现,底层必须有人替它操作窗口、鼠标和键盘。
不过在实际执行时,Codex 并不一定只用 Computer Use。一个 skill 可以结合当前环境里的工具:有插件就用插件,有 MCP 就用 MCP,浏览器可用就用浏览器,GUI 实在绕不过去再用视觉控制。
这个策略很实用。
因为从工程角度看,自动化工具的优先级通常应该是:
- API / MCP / 插件;
- 浏览器结构化能力;
- GUI 视觉操作;
- 人工确认。
越往前越稳定、越快、越可测试;越往后越灵活,但也越脆弱。
四、录制很简单,录好不简单
Record & Replay 降低了创建 skill 的门槛,但不代表随便录一段就能稳定复用。
这里有几个很现实的使用建议。
录制时尽量短而完整。 不要把一个过大的业务流程一次性录完。比如“从素材准备到发布全渠道内容”听起来很诱人,但中间状态太多、分支太多,复现失败时也难定位。更好的方式是拆成几个小 skill:准备素材、上传视频、配置元数据、发布检查。
录制前先告诉 Codex 目标和变量。 比如这次任务的目标是什么,哪些输入每次会变,哪些字段有默认值。这样它在生成 skill 时更容易区分“流程规则”和“本次样例”。
用真实输入,但不要录敏感信息。 密码、验证码、支付信息、密钥、客户隐私数据,都不应该出现在录制里。AI 自动化一旦进入真实账号和真实数据环境,权限边界就要比普通工具更保守。
录完后补充隐性偏好。
很多规则在操作里看不出来。比如 issue 标题要带模块名前缀,报表文件名要用 yyyyMMdd,视频描述固定加一段免责声明。这些最好在录制后显式补给 Codex,让它写进 skill。
流程做完就停。 不要录着录着顺手回消息、切浏览器、改别的文件。Record & Replay 需要的是一条干净的任务轨迹。录制数据越杂,skill 越容易学偏。
这其实和教新人做事差不多。你不能一边演示报销,一边顺手处理 Slack、翻邮件、查账单,还指望对方准确学到“报销流程”。AI 也一样,只不过它更容易把噪声认真记下来。
五、它和插件不是一回事
Codex 的 Record & Replay 会生成 skill,但这不等于所有工作流都应该靠录制解决。
如果只是个人使用,或者某个流程变化频繁、文档化成本太高,录制很合适。它快,低门槛,足够贴近个人习惯。
但如果你要把一套能力分发给整个团队,或者要做权限管理、版本管理、依赖管理、多个 skill 打包、应用集成、MCP 服务器接入,那就应该认真做成插件。
可以简单区分一下:
| 场景 | 更适合 Record & Replay | 更适合插件 |
|---|---|---|
| 个人重复任务 | 是 | 不一定 |
| 快速沉淀隐性流程 | 是 | 成本偏高 |
| 团队统一分发 | 勉强 | 是 |
| 需要版本控制 | 弱 | 强 |
| 需要稳定接口 | 弱 | 强 |
| 需要接 MCP / 外部服务 | 有限制 | 更合适 |
| 流程经常变 | 是 | 维护成本高 |
Record & Replay 更像是技能的快速原型工具。它把“我怎么做”快速变成“AI 可以怎么做”。
插件更像正式交付物。它适合标准化、规模化和治理。
这两者的关系有点像脚本和内部平台。脚本解决局部效率问题,平台解决组织级复用问题。很多团队的问题不是不会做平台,而是太早做平台。流程还没稳定,先录一个 skill 跑起来,反而更符合工程常识。
六、能力边界要看清楚
这次 Record & Replay 也有明确限制。
目前它只在 macOS 上可用,首发不覆盖欧盟、英国和瑞士,并且必须开启 Computer Use。
如果组织管理员使用 requirements.toml 统一管理 Codex,还要注意 [features].computer_use。这一项会同时影响 Computer Use 和 Record & Replay。也就是说,如果这里被设置为 false,Record & Replay 也会一起消失。
这类配置问题在团队环境里很常见。用户觉得功能“不见了”,最后查半天发现是组织策略关掉了底层能力。
另外,Codex 应用、CLI 和 SDK 并不只能接 OpenAI 自家的模型。通过 config.toml 配置 model_providers,可以指向 Ollama、LM Studio 这类本地模型,也可以接 Mistral、Azure、Amazon Bedrock 等第三方提供方。使用 --oss 参数还能运行本地 provider。
这说明 Codex 更像一个开放客户端,而不仅是某个单一模型的壳。Record & Replay 生成的 skill、Computer Use 的执行能力、插件和 MCP 的组合,最终都在这个客户端里汇合。
但这里也要保持克制。
模型可替换,不代表效果完全等价。GUI 理解、长流程规划、异常处理、上下文保持,这些能力非常吃模型质量。接本地模型当然有隐私和成本优势,但在复杂桌面自动化里,稳定性要实际测,不适合直接拍脑袋上生产。
七、GUI 正在变成 AI 的接口
过去很多年,自动化的基础是 API。
软件把能力封装成接口,外部系统通过接口调用。这个路径稳定、清晰、可观测,也符合工程系统的基本逻辑。只要 API 设计得好,自动化就能做得很扎实。
但 API 有一个现实问题:它取决于软件愿意开放什么。
很多系统没有 API;有 API 但覆盖不全;有 API 但权限申请麻烦;有 API 但文档过期;还有些 SaaS 产品故意把关键能力藏在付费版本里。于是大量业务流程仍然卡在人类手工操作上。
Record & Replay 代表的方向,是让 AI 直接进入人类原本使用的软件界面。
这会改变自动化的边界。
以前的边界是“有没有接口”。 现在边界开始变成“AI 能不能看懂并稳定操作”。
这两者有很大差别。
API 自动化是软件主动暴露能力。GUI 自动化是 AI 从人类界面里反向提取能力。前者更可靠,后者覆盖面更广。工程上最合理的做法不是二选一,而是分层使用:
- 能用 API 的地方,优先 API;
- 能用 MCP 或插件的地方,优先结构化集成;
- 浏览器任务尽量利用 DOM 和会话能力;
- 实在没有接口,再用 Computer Use;
- 高风险动作保留人工确认。
这套分层会成为未来 AI Agent 落地时很重要的架构原则。因为没有任何团队愿意把核心业务完全押在“AI 看屏幕点按钮”上,但也很少有团队能等所有系统都开放完美 API 再开始自动化。
八、人开始训练软件使用者
Record & Replay 最有意思的地方,不是它让 Codex 多了一个功能,而是它改变了人与软件之间的关系。
过去,操作系统负责组织软件,人负责在软件之间切换、复制、填写、判断和提交。很多知识其实不在系统里,而在人的手上。比如某个后台该怎么填,某个报表该怎么导,某个异常该怎么绕。
人是软件之间的胶水。
当 AI 能跨应用观察、理解并执行任务时,它开始接管一部分胶水工作。用户的关注点会从“我该怎么操作软件”,逐渐转向“我要完成什么任务”。
这对软件产品也会有影响。
如果未来大量软件操作由 AI 完成,界面设计的优先级会发生变化。漂亮的布局、复杂的交互、隐藏式菜单,对 AI 来说未必重要。它更关心的是:
- 页面状态是否清晰;
- 按钮和字段语义是否明确;
- 操作结果是否可验证;
- 异常信息是否可理解;
- 是否有结构化接口可走;
- 自动化过程是否稳定。
这并不意味着 GUI 会消失。人仍然需要界面,尤其在探索、判断、审批和异常处理时。但 GUI 的另一个使用者出现了:AI。
从这个角度看,Record & Replay 其实把人的操作经验变成了训练材料。你做一遍,它学一遍;你补充偏好,它沉淀成 skill;下一次它带着这份经验去执行。
今天我们还在学习怎么使用工具。往后很多重复工作里,更重要的能力可能是:把你怎么使用工具,教给 AI。