












































很多 RAG 应用最危险的阶段,不是刚写完 Demo 的时候,而是它刚好“看起来能用”的时候。
你问几个问题,它能检索文档,能组织答案,甚至语气还挺像那么回事。于是团队开始接入业务流程。过一段时间,用户反馈来了:有些答案答非所问,有些答案听起来很完整,但追到来源文档里根本找不到依据。再往下查,才发现问题可能不在大模型,也可能不在 prompt,而是检索阶段早就把错误的 chunk 塞进去了。
RAG 的麻烦就在这里。它不是一个单点模型调用,而是一条链路。检索、重排、上下文拼接、提示词、生成模型,每一层都可能让最终答案变差。没有评估层,调 RAG 很容易变成玄学:今天改 chunk size,明天改 prompt,后天换 embedding model,最后没人知道质量到底是变好了,还是只是某几个样例看起来顺眼了。
一、RAG 评估的难点不在打分
传统机器学习任务的评估相对直接。分类任务有 label,有 prediction,算 accuracy、precision、recall、F1。虽然工程上也有不少坑,但至少“答案是否正确”这件事通常是明确的。
RAG 不一样。
第一个问题是输出开放。 同一个问题,可以有多种正确回答。只要事实一致、覆盖关键点,表达方式不同并不代表错误。用 BLEU、ROUGE 这类基于字符串重叠的指标去评估 RAG,很容易误伤好答案。它们适合机器翻译、摘要等特定任务的一部分场景,但很难承担 RAG 质量判断的主指标。
第二个问题是失败路径变多。RAG 至少有两个核心组件:
- Retriever:负责找资料
- Generator:负责基于资料回答
最终答案错了,可能是 Retriever 一开始就找错了文档;也可能是 Retriever 找对了,但 LLM 没有按资料回答,自己补了一段看似合理的内容。两种问题的修复方向完全不同。
这也是很多团队调 RAG 时容易陷进去的地方:只看最终答案,然后不断改 prompt。 如果根因是召回不到相关文档,prompt 写得再漂亮,也只是在错误上下文上做语言优化。
第三个问题是幻觉不一定显眼。 LLM 最擅长把不确定的内容说得很顺。对于用户来说,一个流畅、自信、结构完整的答案,往往比一个谨慎但略显保守的答案更有欺骗性。没有 groundedness 检查,也就是答案是否被检索上下文支撑的检查,这类问题很难被系统化发现。
所以,RAG 评估的重点不是“给最终答案打一个分”。更准确地说,它要回答几个工程问题:
- 检索到的内容和问题相关吗?
- 答案是否真正回答了问题?
- 答案里的事实是否被上下文支持?
- 和人工参考答案相比,最终回答是否事实正确?
- 当质量下降时,应该先修 Retriever,还是先修 Generator?
二、四个指标拆开看
一个更可落地的 RAG 评估体系,应该同时覆盖 Retriever 和 Generator。
可以把一次评估理解成三类对象之间的比较:
- 用户问题
- 检索到的文档 chunks
- 生成出来的答案
- 人工参考答案,若有
比较实用的四个指标是:
| 指标 | 比较对象 | 是否需要参考答案 | 主要定位 |
|---|---|---|---|
| Correctness | 生成答案 vs 参考答案 | 需要 | 最终事实正确性 |
| Answer Relevance | 问题 vs 生成答案 | 不需要 | 是否答到点上 |
| Groundedness | 检索文档 vs 生成答案 | 不需要 | 是否有上下文依据 |
| Retrieval Relevance | 问题 vs 检索文档 | 不需要 | 检索结果是否有用 |
这里有个很现实的工程点:四个指标里,只有 Correctness 需要人工参考答案。
这点非常重要。大规模标注 reference answer 成本很高,尤其是企业知识库、客服、法务、医疗、金融这类场景,标注不仅贵,还需要专业人员参与。 如果评估体系完全依赖人工标注,它很难高频运行,更别说接入 CI 或生产流量监控。
而 Answer Relevance、Groundedness、Retrieval Relevance 这三个指标,只需要问题、检索结果和生成答案。它们可以跑在离线数据集上,也可以抽样跑在生产 traces 上。
这不是说它们完美,而是它们足够便宜,能帮你持续发现趋势。
三、指标应该挂在链路哪里
RAG pipeline 里每个指标的位置,其实比指标名字本身更重要。
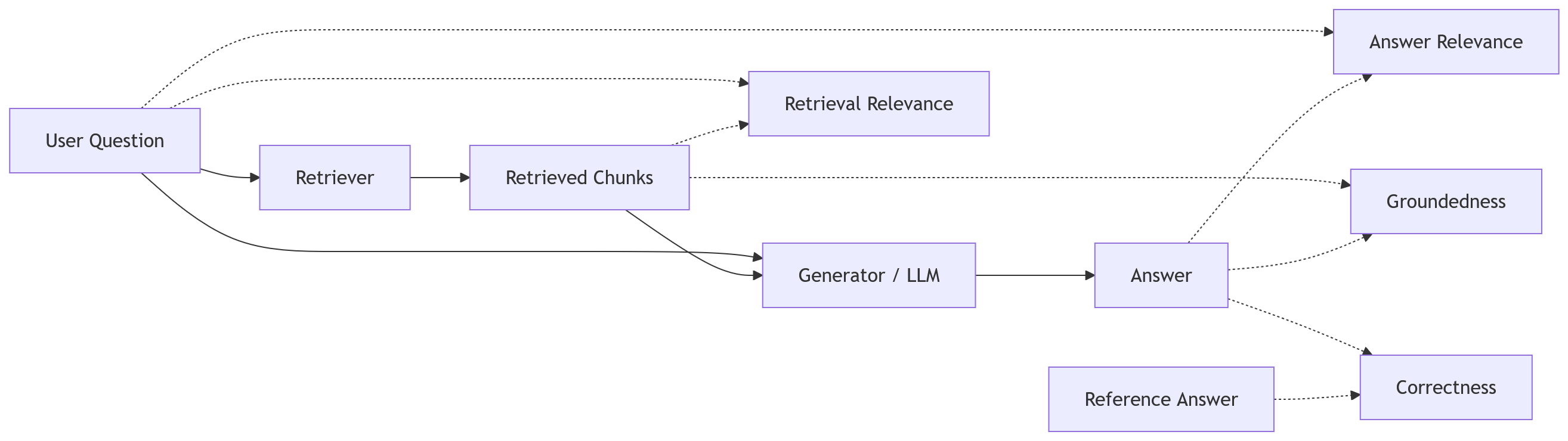
可以这样理解:
- Retrieval Relevance 发生在检索之后,判断文档有没有用
- Answer Relevance 发生在生成之后,判断答案是否回应问题
- Groundedness 发生在生成之后,判断答案是否被文档支撑
- Correctness 需要 reference answer,判断最终事实是否正确
很多团队只做 Correctness,甚至只做人眼 spot check。问题是,最终答案错了以后,你还是不知道错在哪里。
这就像线上接口变慢,只看用户请求耗时,不看数据库、缓存、下游 RPC、队列堆积。你知道它慢了,但不知道该动哪一层。
RAG 评估也是同一个道理。指标必须拆到组件级别,否则评估只能告诉你“坏了”,不能告诉你“该修哪里”。
四、诊断矩阵比总分更有用
当四个指标都有了之后,真正有价值的不是做一个综合分。
综合分对汇报友好,但对排障不友好。生产环境里更有用的是诊断矩阵。
可以用一个简化版本来理解:
| Retrieval Relevance | Groundedness | Answer Relevance | 可能问题 | 优先检查 |
|---|---|---|---|---|
| 低 | 低 | 不稳定 | 检索结果不相关,生成只能硬答 | embedding、chunk、召回策略、query rewrite |
| 高 | 低 | 高 | 文档找对了,但模型在编 | prompt 约束、引用机制、上下文注入方式 |
| 高 | 高 | 低 | 答案有依据,但没回答用户问题 | prompt 任务定义、问题理解、答案格式 |
| 高 | 高 | 高,但 Correctness 低 | 参考答案覆盖了更多事实,或 judge/数据集有问题 | reference answer、评估 prompt、业务口径 |
这里有一个很典型的场景:Retrieval Relevance 很低,但团队一直在优化生成 prompt。 这种优化大概率是无效的。因为 LLM 拿到的上下文就是错的,它再强也只是把错误上下文包装得更像正确答案。
反过来,如果 Retrieval Relevance 很高,但 Groundedness 很低,那说明资料找到了,模型没有老老实实基于资料回答。这时候更应该看 prompt 是否明确要求“只基于上下文回答”、是否需要引用来源、是否允许模型在缺失信息时回答“不知道”。
这是 RAG 评估里的核心权衡: 你不能只追求最终回答“好看”,还要能接受系统在证据不足时回答得保守。生产级系统里,尤其是知识问答、企业助手、客服、合规场景,保守通常比流畅但瞎编更值钱。
五、LangSmith 的位置
LangSmith 是做这件事的一个工具,但不是唯一工具。
如果你的应用已经在 LangChain 生态里,LangSmith 的接入成本比较低。它能记录 traces,跑离线 dataset evaluation,也能查看每个 evaluator 的解释。 如果你不在 LangChain 技术栈里,RAGAS、DeepEval、Arize Phoenix 也都有各自的位置。
这篇文章重点放在 LangSmith,是因为它能比较完整地展示一条 RAG 评估链路:
- RAG 应用支持 trace
- 应用返回 answer 和 documents
- 构建评估数据集
- 编写 evaluator
- 运行 client.evaluate()
- 根据矩阵定位问题
工具可以换,但这条方法论不应该省。
六、RAG 应用要先满足两个契约
评估层要接进来,RAG 应用本身需要满足两个很简单但关键的契约。
契约一:调用过程可追踪
你需要知道每次请求的输入、检索结果、prompt、模型输出。没有 trace,只能看最终答案,很多问题会被藏起来。
LangSmith 里可以用 @traceable() 标记函数。
契约二:返回答案时同时返回文档
这是很多原型代码会漏掉的地方。 业务接口可能只关心 answer,但评估器需要 documents。尤其是 Groundedness 和 Retrieval Relevance,没有检索文档就没法工作。
一个最小示例:
from langsmith import traceable
@traceable()
def rag_bot(question: str) -> dict:
docs = retriever.invoke(question)
answer = llm.invoke(
build_prompt(question, docs)
)
# 评估器需要同时拿到答案和检索文档
return {
"answer": answer,
"documents": docs
}
这里没有限定你的 retriever、vector store、embedding model、LLM 具体用什么。 对评估层来说,它只关心输入、输出和中间上下文是否可见。
很多团队后期补评估时会发现,原来的 RAG 函数只返回字符串答案,检索结果在内部变量里就丢了。线上排查只能重新跑一遍检索,但这已经不是当时那次请求的完整上下文了。这个坑不大,但很烦。
七、构建评估数据集
LangSmith 的数据集需要把输入和参考输出组织起来。
最小数据结构是:
from langsmith import Client
client = Client()
examples = [
{
"inputs": {
"question": "How does the ReAct agent use self-reflection?"
},
"outputs": {
"answer": (
"ReAct integrates reasoning and acting, "
"using tools and then observing the outputs "
"to reason about next steps."
)
},
},
]
dataset = client.create_dataset("RAG Evaluation Dataset")
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
这里的字段含义很直接:
inputs:传给 RAG 函数的输入,这里是questionoutputs:人工参考答案,也就是 reference answer
LangSmith 在执行评估时,会把 inputs 传给目标函数,把目标函数返回的结果和 outputs 一起传给 evaluator。
评估数据集的质量会直接决定评估有没有意义。 几个实践经验比较重要:
| 数据集设计点 | 建议 |
|---|---|
| 问题来源 | 尽量来自真实用户问题,不要只写理想问题 |
| 数据划分 | 开发调 prompt 的问题和评估问题要分开 |
| 覆盖范围 | 覆盖高频问题、边界问题、容易混淆的问题 |
| 参考答案 | 不追求文采,追求事实点清楚 |
| 更新策略 | 随着线上失败案例持续补充 |
有些团队会拿开发阶段反复调过的十几个问题当评估集。这个分数通常会很好看,但意义有限。因为 prompt 已经在这些问题上“过拟合”了。
评估集更像回归测试,不是演示脚本。
八、Evaluator 的基本结构
LangSmith 的 evaluator 本质上就是函数。
每个 evaluator 做三件事:
- 接收输入、输出、可选的参考答案
- 调用一个 judge LLM 判断
- 返回结构化分数
这里有几个工程细节值得保留。
评分模型 temperature 设为 0
评估需要尽量稳定。 同一个输入今天判通过,明天判失败,实验对比就没有意义了。
所以 judge LLM 通常设置:
temperature=0
这不能保证绝对确定性,但能减少不必要的波动。
使用结构化输出
不要让模型自由输出“看起来是对的”。 最好约束它返回固定 schema,例如:
{
"explanation": "...",
"correct": true
}
这样可以避免后续字符串解析、正则匹配,以及模型输出格式漂移导致的评估失败。
explanation 放在 score 前面
让 judge 先解释,再给结论。 这不是为了模拟人类思考,而是为了让评分过程更稳定,也方便后续分析失败模式。
更重要的是,生产里不要只存 True/False。 失败案例里的 explanation 往往比总体通过率更有排障价值。
九、Correctness 评估
Correctness 是四个指标里唯一需要 reference answer 的。
它判断生成答案相对于人工参考答案是否事实正确。注意,这里不应该苛刻比较措辞,也不应该因为答案多说了一些正确补充信息就判错。真正需要警惕的是事实冲突、关键事实缺失、答非所问。
示例代码:
from typing_extensions import Annotated, TypedDict
from langchain_openai import ChatOpenAI
class CorrectnessGrade(TypedDict):
explanation: Annotated[str, ..., "Reasoning for the score"]
correct: Annotated[bool, ..., "True if factually accurate vs ground truth"]
correctness_instructions = """
You are grading a student's answer against a ground truth.
Grade on factual accuracy only.
Extra correct information is fine.
Conflicting statements are not.
Explain your reasoning step by step before giving a final verdict.
"""
grader_llm = ChatOpenAI(
model="gpt-4.1",
temperature=0
).with_structured_output(
CorrectnessGrade,
method="json_schema",
strict=True
)
def correctness(
inputs: dict,
outputs: dict,
reference_outputs: dict
) -> bool:
prompt = f"""
QUESTION:
{inputs['question']}
GROUND TRUTH:
{reference_outputs['answer']}
STUDENT ANSWER:
{outputs['answer']}
"""
grade = grader_llm.invoke([
{
"role": "system",
"content": correctness_instructions
},
{
"role": "user",
"content": prompt
}
])
return grade["correct"]
LangSmith 会根据函数签名决定传什么数据。
如果 evaluator 接收 reference_outputs,它就会从数据集里传入人工参考答案。
如果 evaluator 只接收 inputs 和 outputs,它就不会依赖标注数据。
这个设计很实用。你可以把 Correctness 用在离线标注集上,把另外三个指标用在更大规模的无标注数据上。
十、三个无参考指标
另外三个 evaluator 的结构类似,区别在于比较对象不同。
Answer Relevance
它判断答案是否回应了用户问题。
def relevance(inputs: dict, outputs: dict) -> bool:
prompt = f"""
QUESTION:
{inputs['question']}
ANSWER:
{outputs['answer']}
"""
grade = relevance_llm.invoke([
{
"role": "system",
"content": relevance_instructions
},
{
"role": "user",
"content": prompt
}
])
return grade["relevant"]
这个指标能发现一种常见问题:答案看起来内容很多,但没有回答用户真正问的点。
比如用户问“这个接口为什么 429”,答案却泛泛解释了一遍限流机制。内容可能没错,但不 relevant。
Groundedness
它判断答案中的事实是否被检索文档支持。
def groundedness(inputs: dict, outputs: dict) -> bool:
docs = "\n\n".join(
doc.page_content for doc in outputs["documents"]
)
prompt = f"""
FACTS:
{docs}
ANSWER:
{outputs['answer']}
"""
grade = grounded_llm.invoke([
{
"role": "system",
"content": grounded_instructions
},
{
"role": "user",
"content": prompt
}
])
return grade["grounded"]
这个指标对生产级 RAG 很关键。
尤其在企业知识库场景里,系统不应该随便补充知识库里没有的东西。 即使模型知道某个行业通用知识,也要看业务是否允许它使用外部常识。很多场景下,答案必须以企业内部文档为准。
Retrieval Relevance
它判断 Retriever 找到的文档是否和问题相关。
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
docs = "\n\n".join(
doc.page_content for doc in outputs["documents"]
)
prompt = f"""
QUESTION:
{inputs['question']}
FACTS:
{docs}
"""
grade = retrieval_relevance_llm.invoke([
{
"role": "system",
"content": retrieval_relevance_instructions
},
{
"role": "user",
"content": prompt
}
])
return grade["relevant"]
这也是为什么 RAG 函数必须返回 documents。
没有这些文档,Groundedness 和 Retrieval Relevance 都没法运行。
十一、运行 LangSmith 评估
目标函数只需要把 LangSmith dataset 的 inputs 转成你的 RAG 调用即可。
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data="RAG Evaluation Dataset",
evaluators=[
correctness,
groundedness,
relevance,
retrieval_relevance
],
experiment_prefix="rag-evaluation-v1",
metadata={
"model": "gpt-4.1",
"chunk_size": 250,
"embedding": "text-embedding-3-large",
"prompt_version": "2024-06-22"
},
)
运行时,LangSmith 会对 dataset 中的每条 example 执行一次 target,记录输入、输出、trace,并把这些结果传给 evaluators。
UI 里通常会看到:
- 每个样例一行
- 每个 evaluator 一列
- 每个指标的通过/失败
- judge 给出的 explanation
- 对应 trace,包括检索文档和模型输出
这里的 metadata 不是可有可无的装饰。
RAG 实验最怕“过几天自己也不知道改了什么”。 模型换了、prompt 改了、chunk size 调了、embedding model 换了、top_k 改了,都会影响结果。没有 metadata,实验记录会变成一堆不可解释的历史截图。
工程上至少应该记录:
| 维度 | 示例 |
|---|---|
| LLM | gpt-4.1、claude、qwen 等 |
| Embedding | 模型名称和版本 |
| Chunk 策略 | chunk size、overlap |
| Retriever 参数 | top_k、score threshold |
| Prompt 版本 | prompt hash 或版本号 |
| 数据集版本 | dataset name、revision |
这类版本信息平时看着啰嗦,但一旦线上质量回退,它能救命。
十二、常见误区
只评估最终答案
这是最常见的问题。
最终答案评估当然重要,但它只能告诉你结果好坏,不能告诉你链路哪里坏。 RAG 系统一定要把检索指标和生成指标分开看。
如果 Retrieval Relevance 下降,优先看:
- query rewrite 是否失效
- embedding model 是否适合当前语料
- chunk 切分是否破坏语义
- top_k 是否过小或过大
- 文档更新后索引是否重建
如果 Groundedness 下降,优先看:
- prompt 是否允许模型发挥
- 是否要求引用来源
- 上下文是否过长导致关键信息被稀释
- 是否需要答案拒答策略
用开发问题做评估集
开发阶段调 prompt 用过的问题,不适合作为核心评估集。
这和单元测试有点像。你不能只测自己刚刚手动验证过的 happy path。 RAG 评估集应该保留一部分 held-out test set,避免 prompt 对固定问题过拟合。
同一个模型生成和评分
如果同一个模型既生成答案,又负责评价答案,可能会产生风格偏好。
这不一定会让结果完全失效,但会引入偏差。更稳妥的做法是:
- 生成模型和 judge 模型分开
- 或者至少使用不同配置
- 对关键样本保留人工复核
这里也有成本权衡。更强的 judge 模型更贵,但更弱的 judge 可能误判更多。 生产里可以分层处理:日常大规模抽检用成本较低的 judge,关键版本发布前用更强模型和人工抽样复核。
只看布尔值
True/False 适合做门禁,不适合做分析。
比如 CI 里可以设置 correctness 低于阈值就阻止部署。但排障时,一定要看 explanation。很多系统性问题会先在解释里暴露出来:
- judge 反复提到“answer contains unsupported claims”
- 多个失败样本都集中在某类文档
- 某些问题下检索结果总是缺少定义段落
- 答案格式正确,但漏掉关键限制条件
这些模式比一个总通过率更有价值。
十三、自动化评估的边界
LLM-as-judge 不是银弹。
它适合做规模化、持续性的质量观测,也适合做版本对比和回归检测。但它不适合替代所有人工判断。
优点很明显:
- 成本低于人工逐条审核
- 可以高频运行
- 能接入 CI/CD
- 能覆盖生产抽样流量
- 能提供解释,辅助定位问题
缺点也必须承认:
- judge 本身会误判
- prompt 设计会影响评分
- 对专业领域问题可能不够可靠
- 对模糊业务口径的判断可能不稳定
- 不同 judge 模型之间可比性有限
所以更靠谱的体系通常是混合的:
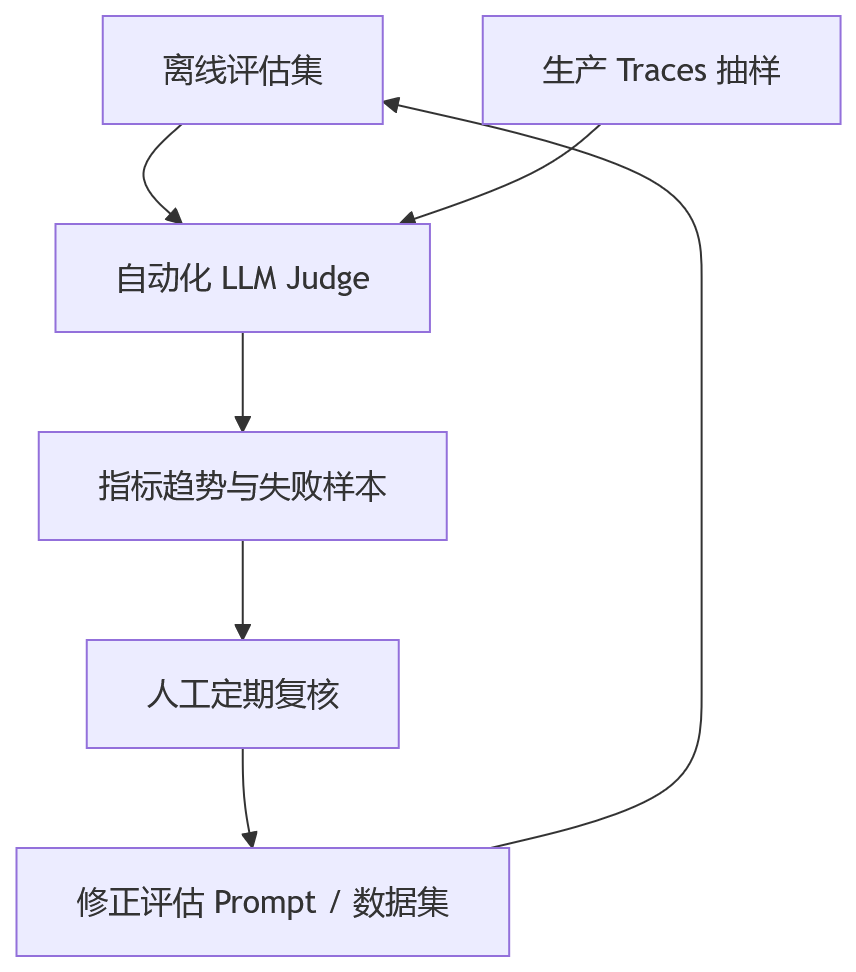
自动化评估负责广度和频率。 人工审核负责校准方向,发现 judge 的系统性偏差。
这也是工程上的现实选择。纯人工太慢,纯自动又容易自嗨。组合起来才比较稳。
十四、工具选择不用先站队
LangSmith 适合已经使用 LangChain/LangGraph 的团队。trace、dataset、evaluation、UI 都比较顺。
RAGAS 更偏框架无关,提供了 faithfulness、answer relevance、context precision、context recall 等指标。如果你的 RAG 系统不是 LangChain 技术栈,RAGAS 可能接得更轻。
DeepEval 覆盖范围更宽,不只服务 RAG,也可以评估摘要、分类、对话等多类 LLM 输出。
Arize Phoenix 更偏可观测性和生产监控,适合关注模型版本、漂移检测、trace 分析的场景。
简单对比一下:
| 工具 | 更适合的场景 | 主要取舍 |
|---|---|---|
| LangSmith | LangChain 生态、trace evaluation 一体化 | 生态绑定更明显 |
| RAGAS | 框架无关的 RAG 指标评估 | 需要自己接更多工程链路 |
| DeepEval | 多类型 LLM 应用评估 | 指标多,需要团队定义好口径 |
| Phoenix | 生产观测、漂移、trace 分析 | 更偏监控平台,不只是离线评估 |
先把方法论想清楚,再选工具。 工具能降低接入成本,但不能替你定义“什么叫好答案”。
十五、把评估层做进工程流程
如果只在上线前手动跑一次评估,它的价值会打折很多。
更实用的做法是把 RAG 评估放进日常工程流程。
评估集先于应用稳定
在构建 RAG 应用早期,就应该开始积累问题集。
真实用户问题会逼你看到很多边界:
- 问法不标准
- 缩写很多
- 上下文缺失
- 多意图混杂
- 问题本身带错误假设
- 需要跨文档综合
这些问题会反过来影响 chunk 策略、metadata 设计、召回方式和 prompt 设计。
CI 中跑核心评估
不是所有评估都要每次提交跑。成本太高,也没必要。
可以分层:
| 阶段 | 评估方式 |
|---|---|
| Pull Request | 小规模核心集,快速回归 |
| Merge 前 | 中等规模评估集 |
| 发布前 | 完整评估集 强 judge |
| 线上运行 | trace 抽样 无参考指标 |
如果 prompt 修改导致 correctness 或 groundedness 明显下降,CI 应该阻止部署。 这比上线后等用户反馈要便宜得多。
指标分开报告
不要只给一个 RAG Quality Score。
至少要长期跟踪:
- Correctness
- Answer Relevance
- Groundedness
- Retrieval Relevance
并且按问题类型、文档类型、业务场景拆分。 整体分数稳定,不代表局部没有劣化。很多生产问题都藏在细分维度里。
失败样本要沉淀回数据集
线上发现的失败案例,不应该只修一次。
它们应该进入评估集,成为之后的回归样本。 否则同类问题很可能在下一次 prompt 调整、模型切换、索引重建后重新出现。
这件事听起来像常识,但很多团队做不到。原因也简单:短期看不出收益,长期不做一定会还债。
十六、RAG 调优要从可见性开始
生产级 RAG 的难点,不只是把 LangSmith 接上,也不只是写四个 evaluator。
真正难的是建立一种工作方式:每次改动都知道自己改了什么,每次质量变化都能定位到组件,每次失败都能沉淀成后续回归样本。
最小闭环其实并不复杂:
- RAG 函数返回 answer 和 documents
- 建一个包含真实问题的数据集
- 写 Correctness、Relevance、Groundedness、Retrieval Relevance 四个 evaluator
- 用
client.evaluate()跑实验 - 用 metadata 标记版本
- 根据诊断矩阵决定先修 Retriever 还是 Generator
- 把失败案例沉淀回评估集
RAG 从 Demo 到生产,中间差的往往不是“再换一个更强模型”。 很多时候,差的是评估历史、trace 可见性、回归门禁,以及团队愿不愿意承认:看起来不错,不等于系统可靠。
没有评估层的 RAG 调试,本质上是在用更贵的方式反复猜同一个问题。 把评估层补上以后,RAG 才开始像一个可以迭代的工程系统,而不是一段靠运气运行的 prompt。








