












































最近 Agent 领域的动静很大,尤其是围绕“如何让智能体更懂业务”这一核心痛点。当大多数团队还在手动调试 Prompt、调整 Few-Shot 示例时,微软推出的 SkillOpt 项目直接把“技能训练”推到了台前。一周内获得数千 Star,说明市场对这种自动化的能力进化有强烈期待。
但这背后不仅仅是个新工具的问题,而是 Agent 开发范式的潜在转移。过去我们默认 Agent 的能力由基础模型和外部工具决定,现在则试图引入一个中间层——通过优化算法让 Agent 学会特定任务的执行策略。这听起来很诱人,但在工程落地时,我们需要厘清它到底优化了什么,代价又是什么。

一、技能参数的定义与边界
要讨论技能训练,首先得界定“技能”在 Agent 上下文中的具体形态。在传统的微调(Fine-tuning)视角下,技能意味着权重的更新;但在当前的大模型应用层,直接修改权重成本过高且灵活性差。SkillOpt 这类工具所指的“技能”,更多是指向任务执行过程中的决策参数或策略模板。
具体来说,Agent 的技能通常包含三个维度:
- 意图识别策略:如何准确判断用户请求属于哪个工具调用范畴。
- 推理链结构:解决问题时的思维步骤规划(Plan)。
- 参数映射逻辑:将自然语言转化为工具所需的 JSON 参数。
SkillOpt 的核心价值在于,它允许我们针对这三个维度进行局部优化,而不是重新训练整个基座模型。这就好比给司机换了一套更精准的导航逻辑,而不是把发动机拆了重装。
# 示意代码:技能优化对象的结构抽象
class SkillOptConfig:
def __init__(self):
self.prompt_template = "..." # 可优化的指令模板
self.tool_selection_policy = None # 路由策略参数
self.reward_model = "gpt-4-eval" # 用于评估技能效果的裁判模型
这种设计规避了全量微调的风险,但引入了新的复杂度。如果每个业务场景都需要单独训练一套技能参数,维护成本是否会超过人工编写 Prompt 的成本?这是架构师需要优先计算的一笔账。
二、闭环反馈与奖励机制
任何优化算法都离不开反馈信号。对于 Agent 来说,最大的难点在于缺乏明确的 Ground Truth。代码生成有单元测试可以验证,但客服对话、数据分析等任务的“正确性”往往难以量化。
SkillOpt 这类方案通常依赖两种反馈来源:
- 结果验证:任务是否成功完成(如 API 返回状态码 200)。
- 过程评分:由另一个大模型作为裁判(Critic Model),对 Agent 的输出进行打分。
这种基于强化学习的思路(类似 PPO 或 DPO 的变体)在理论上是通的,但在工程实现上存在延迟问题。
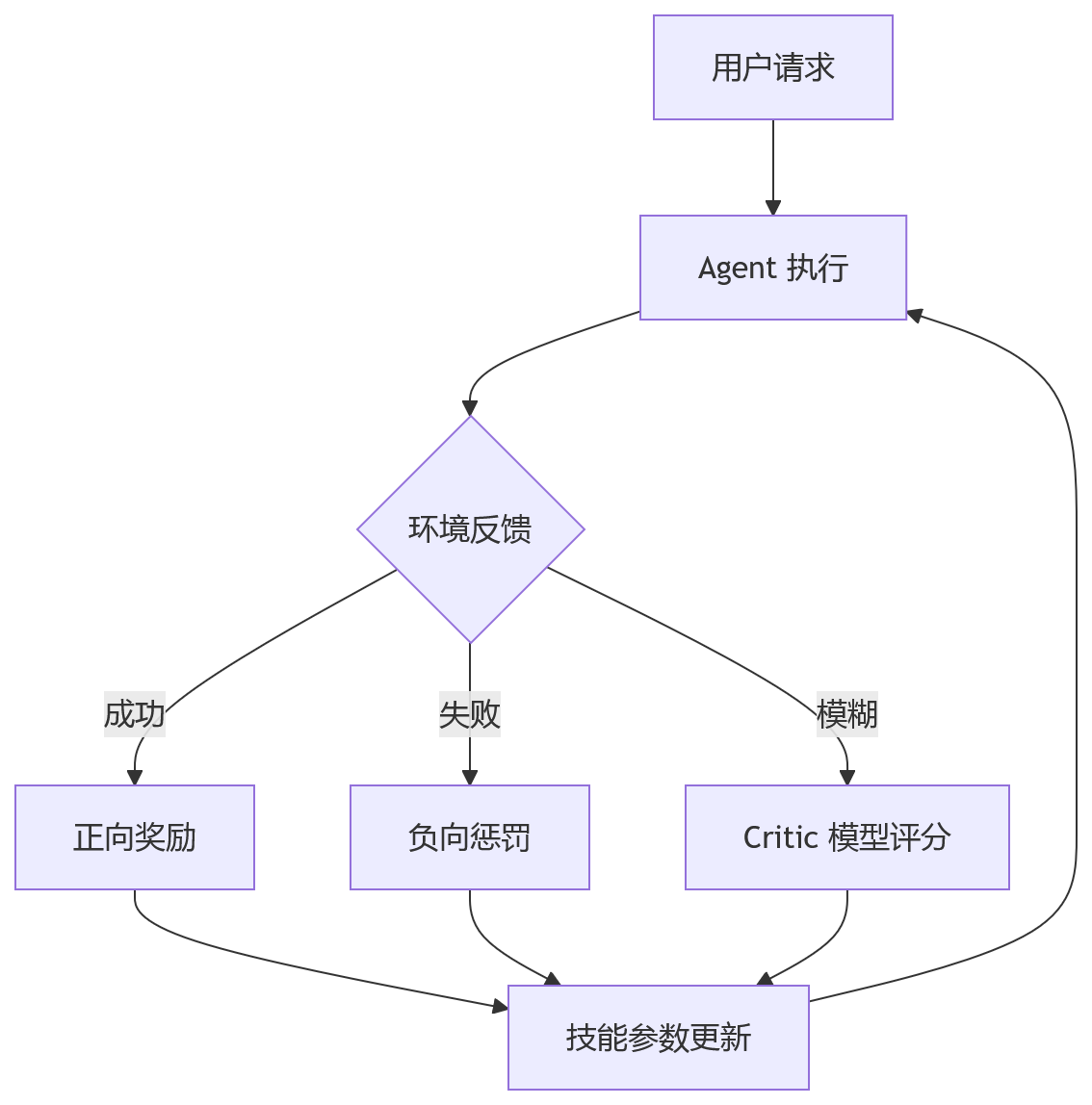
上图展示了典型的优化闭环。这里的关键矛盾在于 Critic 模型的准确性。如果裁判本身对业务理解不足,Agent 就会学会“讨好裁判”而非解决实际问题。我在过往项目中见过类似的尝试,初期效果提升明显,但随着数据分布偏移,模型开始产生幻觉,导致性能不升反降。
因此,在设计优化回路时,必须引入人工校验环节,或者限制优化的范围(例如只优化参数提取部分,不优化推理逻辑)。
三、工程落地的现实约束
回到实际场景,当我们考虑引入 SkillOpt 这样的技能训练框架时,不能只看 Demo 里的准确率提升曲线。生产环境有三大硬约束:
| 维度 | 传统 Prompt 工程 | 技能训练 (SkillOpt) |
|---|---|---|
| 迭代速度 | 分钟级,即时生效 | 小时/天级,需训练收敛 |
| 推理成本 | 低 | 高(需额外计算梯度/采样) |
| 可解释性 | 强,易于排查 | 弱,黑盒参数调整 |
| 冷启动难度 | 低 | 高,需构建初始数据集 |
第一点关于迭代速度。在业务快速变化的阶段,比如双 11 期间活动规则频繁调整,等待技能模型训练收敛可能来不及。此时硬编码的规则引擎反而更靠谱。
第二点是推理成本。如果为了提升 5% 的准确率,增加了 30% 的 Token 消耗或计算时间,这在 SLA 敏感的场景下是不可接受的。我们需要明确技能训练的 ROI 阈值。只有当任务复杂度极高,且 Prompt 工程无法稳定覆盖长尾 Case 时,才值得投入训练成本。
第三点是最容易被忽视的可解释性。当 Agent 表现异常时,如果是 Prompt 写得不好,我们可以直接改文本;如果是隐式参数漂移,排查链路会非常深。这就要求系统必须具备完善的版本管理和回滚机制,确保每次技能更新都是可追溯的。
四、适用场景与选型建议
SkillOpt 的出现确实代表了 Agent 进化的一个方向,即从“通用能力”走向“领域特化”。但它并不是万能药。
对于标准业务流程,比如订单查询、天气播报,结构化 Prompt 配合 Function Calling 已经足够成熟,引入训练机制属于过度设计。真正的机会在于那些非结构化、多步骤且容错率高的场景,比如复杂的代码重构助手、个性化营销文案生成等。
在这些场景中,人类专家的经验难以完全通过 Prompt 固化,而通过历史成功案例反哺 Agent 的策略参数,能带来边际效益的提升。建议在引入此类技术前,先建立一套离线评估集(Evaluation Set),用客观数据说话,而不是依赖主观感觉。
技术演进的本质是在约束条件下寻找最优解。Agent 技能的训练化是必然趋势,但何时做、怎么做,取决于你对业务稳定性与灵活性的权衡。保持理性,关注底层机制,比追逐热点更重要。








