剖析在消费级硬件上运行 DeepSeek 模型的工程路径,涵盖架构设计、量化策略及流量劫持方案,解决网络依赖与隐私顾虑。
最近几个月,本地大模型推理的门槛确实降下来了。过去我们讨论在开发机上跑代码生成模型,往往得盯着企业级 GPU 或者昂贵的云端 Token 账单。现在情况变了,消费级显卡配合量化技术,已经能支撑起日常编码所需的上下文窗口和响应速度。这不仅仅是省钱的考量,更多是数据隐私和网络稳定性的硬性需求。很多团队开始尝试将原本指向公有云 API 的请求,转向本地服务节点,Codex++ 这类工具的出现,本质上是把这套复杂的工程链路封装成了可执行的方案。
这种转变并非没有代价。本地推理对显存的占用是线性的,且首字延迟(TTFT)受限于单卡算力。要在有限的资源下保证体验,需要在模型选型、推理后端、IDE 集成三个层面做精细的权衡。本文将基于 Codex++ 的实现逻辑,拆解这一架构背后的技术细节,重点分析如何在现有硬件条件下,通过合理的代理注入和资源配置,获得可用的满血编程能力。
一、本地推理架构与入口设计
理解任何本地化方案的起点,是理清数据流向。传统的云端代码助手,IDE 作为客户端直接发送 HTTP 请求到远程服务器。而在本地化场景中,我们需要在机器内部构建一个推理引擎,并让 IDE 能够无缝对接。Codex++ 的设计采用了双入口模式,分别对应不同的使用场景和技术栈。
第一个入口是直接插件模式。这种方式通过 IDE 扩展直接加载本地推理库,例如基于 llama.cpp 或 vLLM 的轻量级绑定。它的优势在于延迟极低,因为减少了网络跳数,所有交互都在进程内或 localhost 完成。但这种模式对 IDE 宿主环境的兼容性要求较高,不同版本的编辑器可能导致底层依赖冲突。
第二个入口是服务端代理模式。这是目前更通用的做法。独立启动一个本地推理服务,监听特定端口(如 127.0.0.1:8000),IDE 则配置为该服务的客户端。这种解耦设计允许我们在后台灵活切换模型版本,甚至动态调整批处理大小,而无需重启 IDE。对于生产环境而言,维护一个稳定的推理服务远比维护复杂的插件依赖更可控。
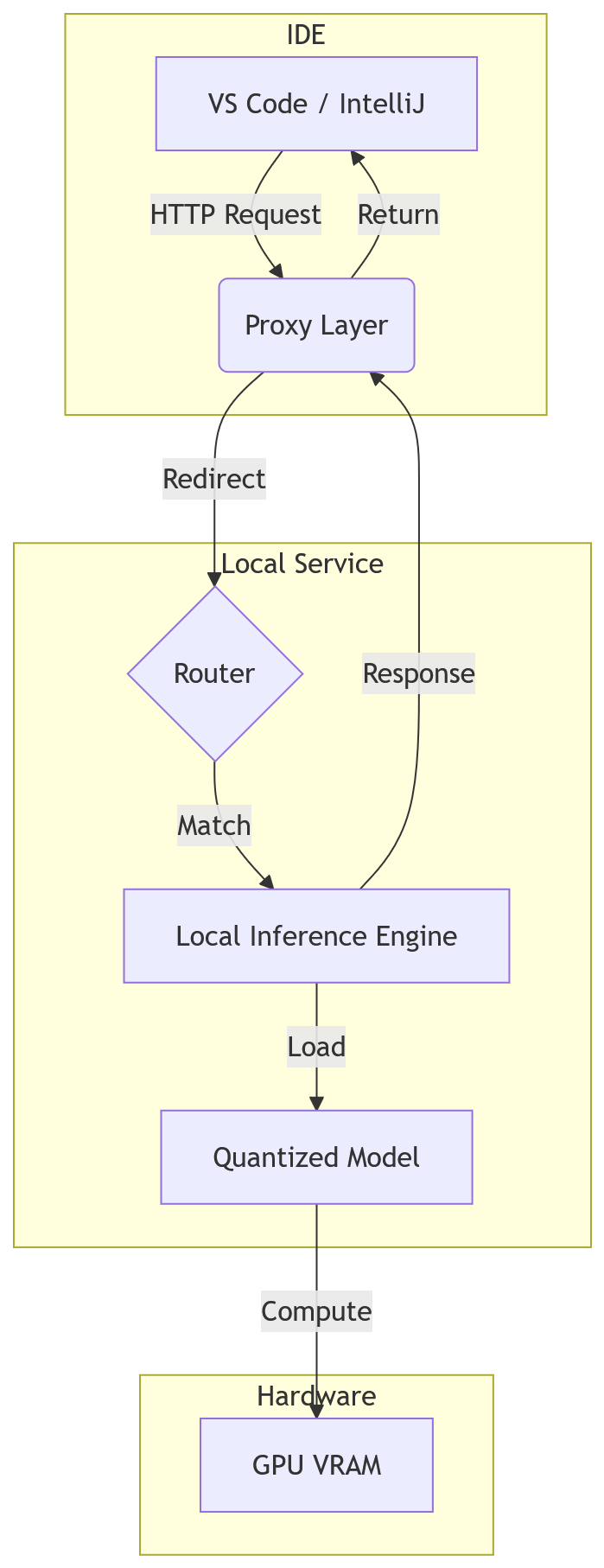
从架构上看,核心矛盾在于路由层如何识别并拦截请求。如果仅仅修改 IDE 的配置项,一旦官方更新扩展,配置极易失效。因此,成熟的方案通常包含一个中间件层,负责协议转换和鉴权。这不仅是为了转发请求,更是为了记录日志、监控显存水位以及处理超时重试。在实际落地中,建议将推理服务容器化,利用 Docker Compose 管理依赖,这样在不同开发机之间迁移环境时的成本会显著降低。
二、显存约束与模型量化策略
提到消费级显卡,绕不开的话题就是显存。一张常见的 8GB 或 12GB 独显,无法直接加载未经处理的 7B 或更大参数量的模型。FP16 精度下,仅权重部分就需要约 14GB 显存,加上激活值和 KV Cache,8GB 显卡根本跑不起来。这就是为什么必须引入量化技术。
目前的最佳实践是 INT4 量化。通过 GGUF 或 AWQ 格式,可以将模型体积压缩至原来的四分之一,同时保持绝大部分的语言理解和代码生成能力。对于代码任务而言,数学精度要求低于自然语言对话,INT4 带来的微小性能损耗在大多数场景下是可以接受的。Codex++ 在默认配置中通常会自动检测可用显存,并匹配对应的量化版本。
但这里有一个容易被忽视的细节:KV Cache 的增长。随着对话上下文的增加,缓存占用的显存会线性上升。如果在长文件分析场景下,很容易出现 OOM(Out Of Memory)崩溃。工程上的应对策略是设置最大上下文窗口限制,或者启用 Paged Attention 机制。后者类似于操作系统的虚拟内存管理,按需分配显存块,能有效提升显存利用率,防止碎片化。
下表展示了不同配置下的显存预估与适用场景:
| 模型版本 | 精度 | 显存占用 (估算) | 推荐显卡 | 适用场景 |
|---|---|---|---|---|
| DeepSeek-Coder-1.3B | FP16 | ~3 GB | GTX 1650 / MX550 | 简单补全、语法检查 |
| DeepSeek-Coder-6.7B | INT4 | ~5 GB | RTX 3060 8G | 函数级生成、注释编写 |
| DeepSeek-Coder-6.7B | FP16 | ~14 GB | RTX 3090 / 4090 | 复杂重构、跨文件理解 |
| DeepSeek-Coder-33B | INT4 | ~20 GB | 多卡 / 专业卡 | 系统级架构建议 |
选择模型时,不要盲目追求参数量。对于日常编码,6.7B 的量化版本在速度和效果之间取得了较好的平衡。如果显存紧张,可以牺牲部分上下文长度来换取更快的响应。此外,注意驱动层面的优化,确保 CUDA 版本与推理后端兼容,避免因算子不支持导致的回退 CPU 执行,那样会让推理速度下降两个数量级。
三、流量劫持与代理注入配置
完成了本地服务搭建后,最后一步是让现有的开发工具“无感知”地使用本地模型。这就涉及到了流量劫持与代理注入。核心思路是将 IDE 发出的代码补全或聊天请求,从默认的云端地址重定向到本地服务。
最基础的实现方式是修改环境变量或配置文件中的 API Endpoint。但这存在风险,许多商业 IDE 会将密钥硬编码或通过 HTTPS 证书校验保护连接。如果遇到这种情况,单纯修改 URL 会导致握手失败。此时需要引入自签名证书或配置信任链。在 Linux 和 macOS 环境下,可以通过 SSL_CERT_FILE 环境变量指定本地 CA 证书;Windows 下则需导入到系统根证书存储区。
对于更隐蔽的注入,可以使用 MITM(Man-In-The-Middle)工具,如 mitmproxy 或自定义的 Nginx 反向代理。Nginx 配置示例如下,用于将特定域名转发到本地:
server {
listen 80;
server_name api.deepseek.com; # 示例目标域名
location /v1/chat/completions {
proxy_pass http://127.0.0.1:8080/v1/chat/completions;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
# 关键:处理 WebSocket 升级,支持流式输出
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
需要注意的是,这种配置涉及 DNS 欺骗或 hosts 文件修改。在生产环境中,建议仅在开发机进行此类操作,并明确标识,以免误触线上调试流程。另外,安全性方面,虽然流量不出局域网,但仍需防范本地恶意软件窃听。可以在本地服务层开启 mTLS(双向认证),确保只有受信任的 IDE 插件能访问推理接口。
还有一个实际问题是并发控制。如果多个 IDE 实例同时请求本地模型,可能会瞬间撑爆显存。建议在代理层加入限流器,按优先级排队请求。对于简单的代码补全,可以设置较短的超时时间;对于复杂的问答,则允许较长的等待。通过观察本地服务的负载指标,动态调整并发数,是维持稳定性的关键。
本地化部署并非完美方案,它带来了额外的运维成本和硬件门槛。但在数据合规性日益严格、网络波动不可控的今天,拥有一个完全受控的本地编程助手,其价值远超节省下来的 Token 费用。关键在于找到适合自身硬件条件的模型精度与上下文窗口组合,并在稳定性上多做投入。随着硬件迭代和推理框架优化,这一架构的适用范围只会更广。