












































大模型交互的本质矛盾之一,在于模型的状态无意识与用户期望的持久化人格之间的错位。传统的对话系统设计基于无状态函数调用,每一次请求都应当是独立的。但在实际应用场景中,用户天然期待助手能记住之前的约定、偏好以及历史事实。这种期望如果无法通过技术手段满足,体验就会断裂。
近期 OpenAI 推出的 Dreaming 系统,表面看是功能更新,实质上是 LLM 应用层在状态管理(State Management)上的重要尝试。它不再依赖用户的显式指令来触发保存动作,而是转向后台自动化的信息抽取与状态维护。这标志着长上下文管理从“被动存储”向“主动推理”的转变。对于架构师而言,理解这一转变背后的技术取舍,比关注功能本身更具价值。
一、从显式指令到隐式合成的演进
早期的记忆功能往往采用显式 Key-Value 模式。用户在对话中明确发出“记住这个”的指令,系统将特定片段存入向量库或数据库。这种方式的优点是数据准确率高,因为经过了用户确认;缺点则是召回率低,大量有价值的上下文信息被淹没在对话流中未被提取。
新的 Dreaming 机制引入了后台异步处理逻辑。系统会在对话结束后或特定间隔内,自动读取历史对话日志,进行语义分析和摘要生成。这意味着记忆不再是静态的文本片段,而是经过二次加工的结构化信息。这种设计类似于后端服务中的 Event Sourcing(事件溯源),将原始对话作为事件流,定期生成快照(Snapshot)作为当前状态。
这种架构升级解决了两个问题。一是降低了用户的认知负担,无需刻意提醒模型记住什么。二是提升了信息的时效性,旧的记忆可以被新的状态覆盖或修正。不过,这也带来了新的风险:自动化提取可能产生幻觉,或者错误地归纳用户意图。因此,如何在自动化与准确性之间寻找平衡点,是这一阶段的核心挑战。
二、记忆质量的三个核心维度
评估一个长期记忆系统是否合格,不能只看“记住了多少”,更要看“怎么用”。根据 OpenAI 披露的技术指标,记忆质量主要围绕上下文延续、偏好保持和时间感知三个维度展开。
上下文延续的精度要求
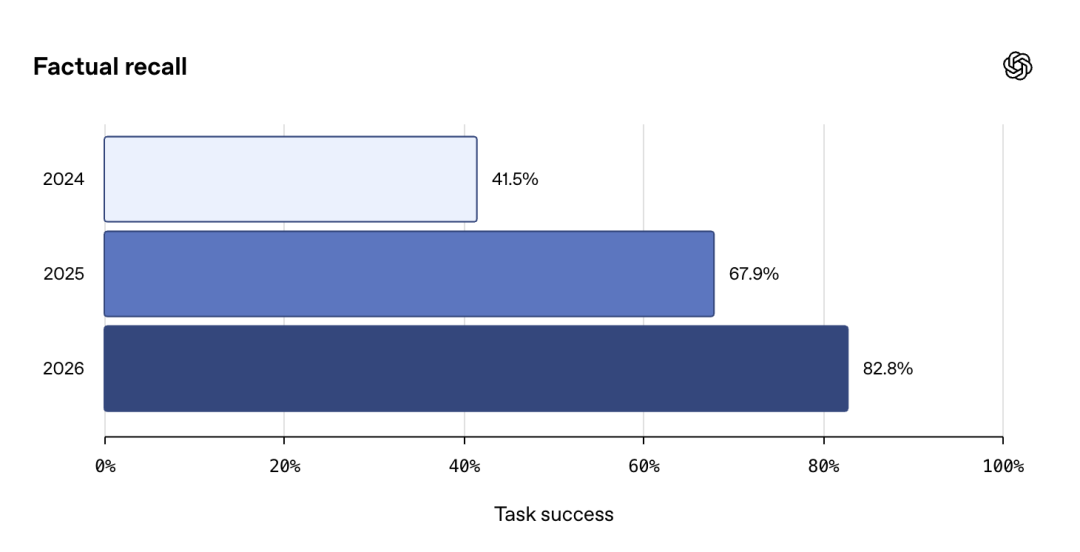
在专业场景下,记忆的准确性直接决定了工具调用的可用性。例如摄影器材配置案例中,模型需要精确区分机身型号、配件品牌及兼容性协议。普通的语义检索可能只能匹配到“闪光灯”,而无法精准定位到“适配 Mini Flash 3 的 TTL 触发器”。
这要求记忆系统具备细粒度的实体识别能力(NER)。在架构设计上,可能需要引入专门的中间层,对提取出的关键实体进行结构化存储,而非简单的 Embedding 向量存储。当用户再次提问时,系统优先检索结构化字段,再结合向量检索补充上下文。
偏好建模与个性化推荐
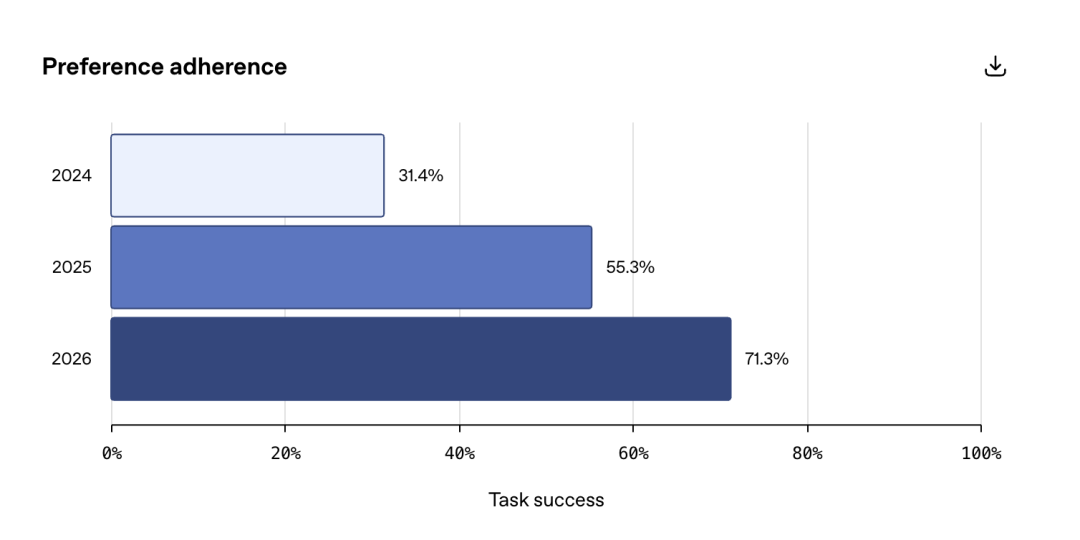
偏好记忆属于高维特征数据。用户喜欢安静餐厅、对空调敏感、素食主义等,这些信息分散在不同的对话轮次中。系统需要将这些碎片信息聚合为一个稳定的用户画像(User Profile)。
工程上通常采用多向量索引策略。除了常规的内容向量,还需要为“偏好”、“限制条件”建立独立的索引空间。在生成回答前,先检索偏好空间,将其作为 System Prompt 的一部分注入当前上下文。这种方式虽然增加了检索开销,但能显著减少模型在生成阶段的幻觉概率。
时间感知的状态流转
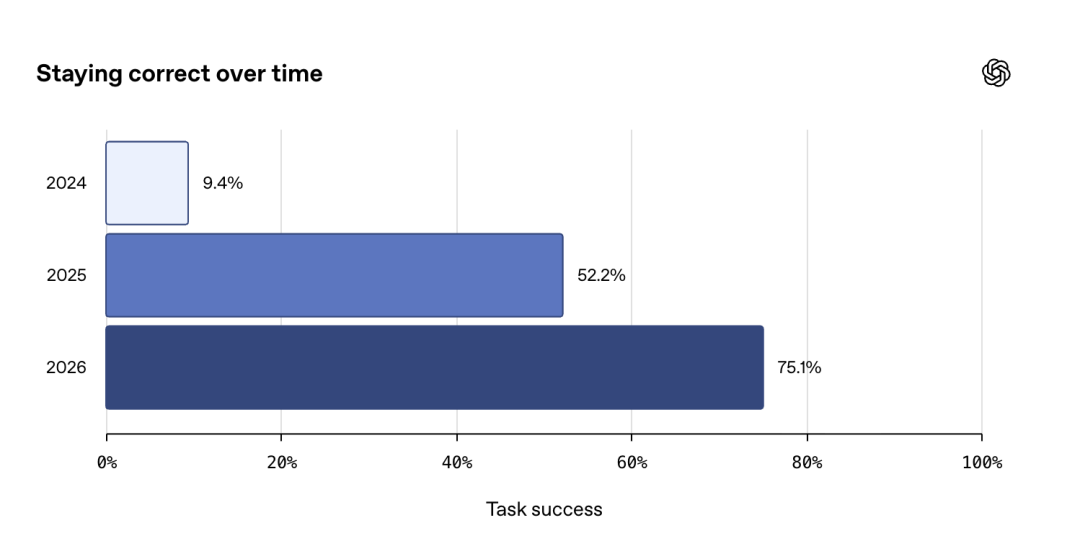
这是最具技术难度的部分。传统记忆系统容易陷入“状态固化”陷阱,即一旦记录“我在某地”,该状态会永久生效。现实世界中,人的位置、职位、计划都是随时间衰减或变更的。
Dreaming 系统引入了时间戳和状态有效期概念。后台进程不仅记录内容,还监控内容的“新鲜度”。例如,当检测到新的地理位置信息,或时间跨度超过预设阈值(如一周未提及旅行),系统会自动标记旧记忆为过期或降级权重。这种动态更新机制,类似于分布式系统中的租约(Lease)机制,确保内存中始终保留的是最新有效状态。
三、算力成本与规模化落地的平衡
任何功能若无法在成本可控的前提下规模化,都难以成为产品级特性。此前限制免费用户使用高级记忆功能的核心瓶颈,正是算力成本。对海量历史对话进行实时解析和检索,消耗的计算资源远超单次对话生成。
此次更新声称将算力成本降低了 5 倍。从技术推断,这可能得益于以下几个优化方向:
- 小模型蒸馏:使用轻量级模型专门负责记忆抽取和摘要任务,而非由主模型承担所有工作。
- 增量更新策略:避免全量重算,仅对新产生的对话片段进行增量处理,合并入现有记忆图谱。
- 压缩与剪枝:对低价值、重复或过期的记忆片段进行自动清理,减少向量库规模。
成本的降低使得记忆功能可以从“增值特性”下沉为“基础设施”。这对开发者意味着,构建具有长期记忆的 Agent 应用门槛正在降低。然而,随着记忆能力的普及,隐私合规和数据主权的问题也会更加凸显。用户需要明确的控制权来查看、修改或删除模型所“记得”的内容,这在未来的架构设计中将是不可回避的一环。
从技术演进的视角看,长期记忆系统只是通往通用智能代理的第一步。真正的挑战不在于如何存得更久,而在于如何让机器像人一样,懂得遗忘无关紧要的细节,并在恰当的时机唤醒关键经验。这需要更复杂的决策逻辑,而不仅仅是检索效率的提升。








