LLM 交互最常见的痛点之一,是上下文的断裂。用户在一个会话里交代了项目背景和设备型号,换个话题或重新开启对话,模型又得从头问起。这种“金鱼记忆”限制了助手向长期伙伴的演进。OpenAI 这次推出的基于 Dreaming 技术的记忆系统,表面上是功能增强,本质上是交互架构从“无状态会话”向“有状态服务”的一次重大迁移。
过去我们依赖 Context Window 来维持短期记忆,但 Token 成本和长度限制决定了它无法承载用户全生命周期的信息。静态的“保存记忆”功能虽然解决了部分问题,但维护成本高且容易过时。新的尝试在于让系统具备后台整理和主动遗忘的能力,这涉及到数据流的异步处理、知识图谱的动态更新以及隐私边界的重新定义。
对于工程团队而言,理解这一变化不仅关乎产品体验,更涉及如何处理非结构化数据的长期存储与一致性校验。以下从架构设计、评估指标及控制平面三个维度展开分析。
一、从会话上下文到用户状态库
传统的 LLM 应用架构中,状态主要维持在 Session 层。每次请求携带历史消息,一旦 Session 过期或用户切换设备,上下文即丢失。2024 年 4 月推出的 Saved Memories 功能是一次补救,允许用户显式指令保存关键信息。但在真实场景中,依赖用户主动说“请记住”,效率极低且覆盖不全。
真正的难点在于隐式信息的提取。用户在闲聊中提到“下周去新加坡”,在另一次对话中说“不喜欢海鲜”,这些碎片分散在不同时间点的日志里。旧架构很难在不干扰当前响应的前提下完成聚合。
新系统试图构建一个独立于单次会话的用户状态库(User State Store)。这个库不再是简单的 Key-Value 存储,而是一个能够理解语义关联的结构化知识库。它需要解决两个核心矛盾:一是实时性,二是准确性。

如果完全依赖实时检索所有历史聊天记录,延迟会不可接受;如果仅靠缓存摘要,又容易丢失细节。OpenAI 的方案是在后台异步运行“梦境”进程。这个过程不直接参与用户当前的 Prompt 响应,而是定期扫描历史对话,提取潜在的记忆点,经过置信度评估后写入状态库。
这种设计将在线推理路径与离线数据处理路径解耦。在线时,模型优先查询状态库的高优先级摘要;离线时,系统负责清洗和更新这些数据。这类似于数据库中的 WAL(Write-Ahead Log)与 Compaction 机制的结合,只不过处理的是非结构化文本。
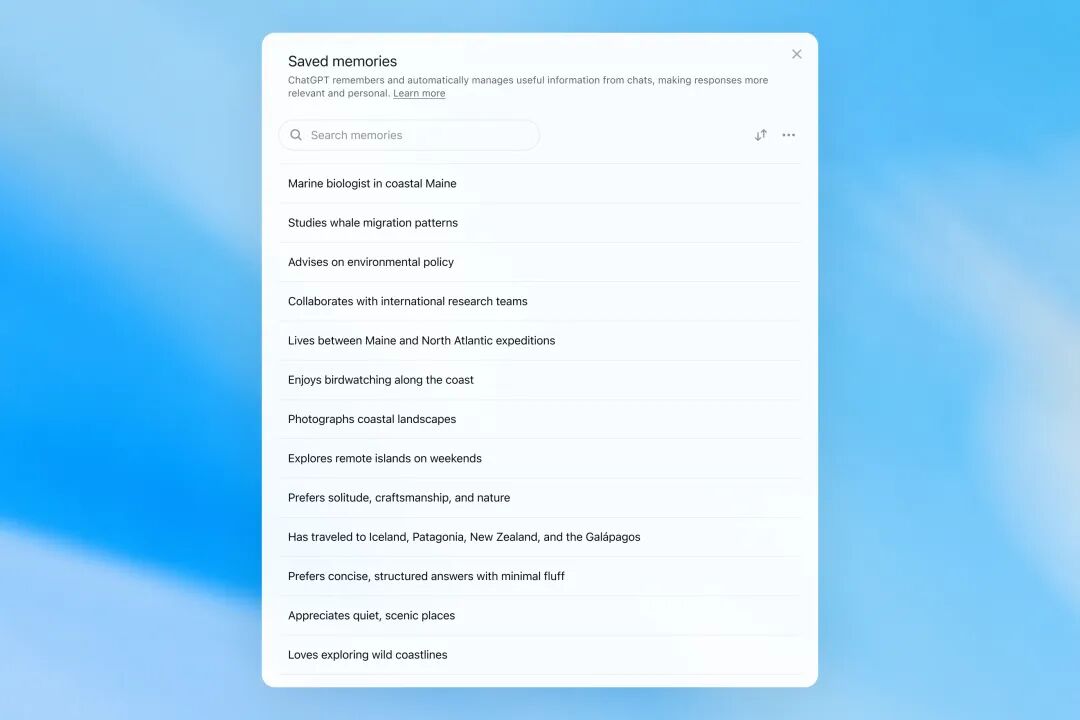
对比旧版手动保存,新架构的优势在于自动化程度。但它引入了新的风险:误判。系统可能会将一次性玩笑误认为长期偏好,或者将过期的计划视为有效约束。因此,后续的控制机制显得尤为重要。
二、Dreaming 机制与评估指标
官方并未公开 Dreaming 的具体算法实现,但从行为表现和数据来看,其核心逻辑更接近于增量式的 RAG(检索增强生成)优化。系统需要在海量对话历史中识别出具有高价值的实体(Entity)和关系(Relation),并将其转化为可被调用的记忆片段。
这里的关键不在于“记住多少”,而在于“何时使用”以及“何时失效”。OpenAI 公布的一组内部评估数据揭示了这一点。在事实回忆测试中,任务成功率从 2024 年的 41.5% 提升至 2026 年 Dreaming V3 的 82.8%。这不仅是模型能力的提升,更是索引策略的改进。
更值得关注的是“随时间保持正确”这一指标的跃升。从 9.4% 到 75.1%,说明系统引入了时间衰减或版本管理逻辑。例如,当检测到用户完成了某次旅行,相关的“准备行李”类记忆会被标记为低优先级或归档,而不是永久置顶。
这种时间感知能力通常依赖于两种技术手段:一是在记忆元数据中记录创建时间和最后活跃时间,二是在检索阶段引入时间过滤器。对于工程实践来说,这意味着我们的向量数据库不仅仅是存 Embedding,还需要支持更复杂的 Metadata Filtering。
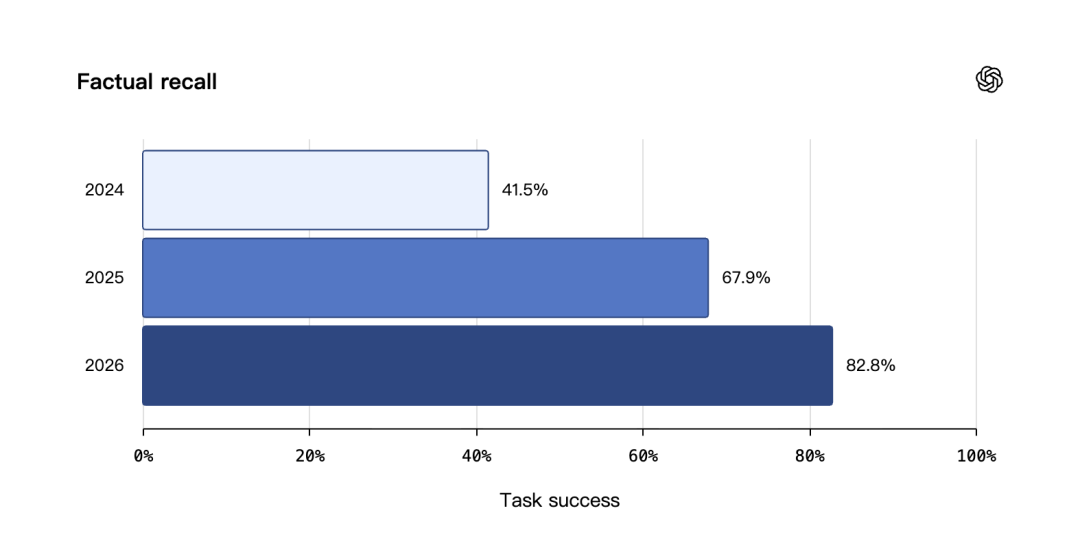
| 测试维度 | 2024 保存记忆 | 2025 Dreaming V0 | 2026 Dreaming V3 |
|---|---|---|---|
| 事实回忆成功率 | 41.5% | 67.9% | 82.8% |
| 偏好遵循率 | 31.4% | 55.3% | 71.3% |
| 时效正确率 | 9.4% | 52.2% | 75.1% |
值得注意的是,偏好遵循率的提升幅度小于事实回忆。这说明理解用户的隐性习惯比记忆显性事实更难。比如用户提到“喜欢安静”,系统能记住这个标签,但在推荐餐厅时是否能结合“带小孩”、“工作日”等其他变量进行加权,仍是一个复杂的推理问题。
三、控制平面与工程边界
记忆系统的落地,最大的阻力往往不在算法,而在治理。一旦系统开始自动收集用户信息,如何确保用户拥有控制权,是产品合规的底线。OpenAI 在此次更新中强化了“记忆摘要”和“来源追溯”功能,这是典型的控制平面设计。
用户现在可以看到系统认为自己记住了什么,并能进行修改或删除。更重要的是“记忆来源”功能,通过书本图标展示回答依据是来自历史聊天、文件还是 Gmail。这在一定程度上解决了黑盒模型的信任问题,符合可解释性 AI 的发展趋势。
然而,删除操作存在滞后性。OpenAI 明确指出,关闭保存记忆不会自动删除已生成的内容,用户需要单独清理。这是因为分布式系统中,数据往往存在多个副本或缓存层级。彻底清除一条记忆,可能需要触发后台的垃圾回收流程,甚至涉及模型微调数据的剔除。
在成本控制方面,OpenAI 提到计算资源减少了约 5 倍。这得益于批处理优化和更高效的向量索引。对于 Free 用户开放该功能,意味着单位 Token 的成本已经降低到可承受范围。这对于自建 Agent 的团队是一个信号:异步记忆处理必须考虑 ROI,不能为了追求完美而牺牲响应速度。
隐私合规依然是悬在头顶的剑。特别是在欧洲经济区等严格监管区域,Gmail 和文件连接功能受限。开发者在设计类似系统时,必须区分“用于上下文检索的数据”和“用于模型训练的数据”。默认情况下,企业版内容不应进入公共训练集,这需要物理隔离或逻辑加密的支持。
四、从工具到外置自我
随着记忆容量的扩大和准确性的提升,ChatGPT 正在脱离单纯的“问答机器”定位。当一个系统掌握了你的项目进度、家庭习惯和过往决策逻辑,它实际上成为了你认知的延伸。
这种转变带来了新的架构挑战。未来的 Agent 架构不能仅仅是 Prompt+Model,更需要包含一个持久的 Memory Layer。这个 Layer 需要支持版本回溯、权限分级和跨设备同步。目前 OpenAI 提供的“记忆历史”功能,本质上就是 Git 版本控制在个人数据上的应用。
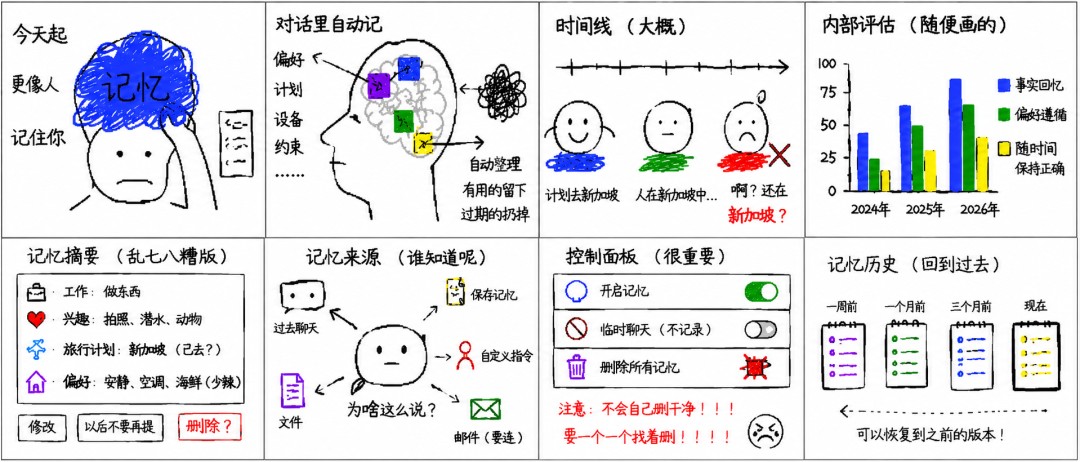
但这也会引发边界问题。如果 AI 记住了太多关于你的信息,谁来保证这些信息不被滥用?虽然平台提供了临时聊天和关闭记忆的选项,但普通用户往往缺乏足够的敏感度来管理这些数据权限。
从工程角度看,记忆系统的完善标志着 AI 产品进入了深水区。接下来的竞争点将不再是模型参数量,而是谁能更高效、更安全地管理用户的全生命周期数据。对于技术决策者而言,如何在个性化体验与数据主权之间找到平衡点,将是未来几年持续面临的课题。
当 AI 开始替你记住生活,它不仅仅是在提供服务,更是在构建一种新型的数字共生关系。这种关系的稳定性,最终取决于我们对这套记忆系统底层的信任程度。