Agent 落地最难的往往不是“跑通”,而是“证明”。
很多团队在 POC 阶段能拿到惊艳的效果,但一旦进入生产环境,面对千变万化的用户输入和复杂的业务约束,效果波动就成了常态。这时候如果没有一套可靠的评测体系,技术决策就会陷入“凭感觉”的困境。我们见过太多场景:因为无法量化回归风险,不敢上线;因为缺乏基准数据,无法判断 Prompt 优化是否真的有效。
传统的评测方式依赖人工抽检,或者简单的关键词匹配,这在简单任务上或许够用,但在复杂业务链路上完全不可行。人工评测不仅慢,而且主观性极强;规则评测则难以覆盖语义层面的偏差。核心矛盾在于:Agent 能力的提升是指数级的,但评测手段的演进却是线性的。
解决这个问题的关键,不在于寻找一个更聪明的评测模型,而在于把评测本身当成软件工程来做。也就是所谓的 Harness 工程化思路。最近尝试利用 Claude Code 这类具备强代码生成能力的工具来搭建评测框架,发现它能显著降低“造轮子”的成本,让团队能把精力集中在指标定义而非脚本编写上。
一、Harness 工程化评测的核心逻辑
Harness 这个词在测试领域并不新鲜,它指的是连接被测对象与测试环境的中间层。在 Agent 语境下,Harness 不再是一个简单的库,而是一套包含数据集管理、执行引擎、评分标准和结果分析的完整流水线。
传统评测往往是“人肉跑分”,或者写几个散落的 Python 脚本。Harness 模式要求我们将评测过程抽象为可复用的组件。这种抽象带来的价值是双向的:一方面,它隔离了 Agent 的具体实现细节,使得更换底层模型或调整 Prompt 时,评测逻辑无需重写;另一方面,它将非结构化的输出转化为结构化的数据,便于后续的趋势分析和归因。
一个标准的 Agent 评测架构通常包含三个核心闭环:
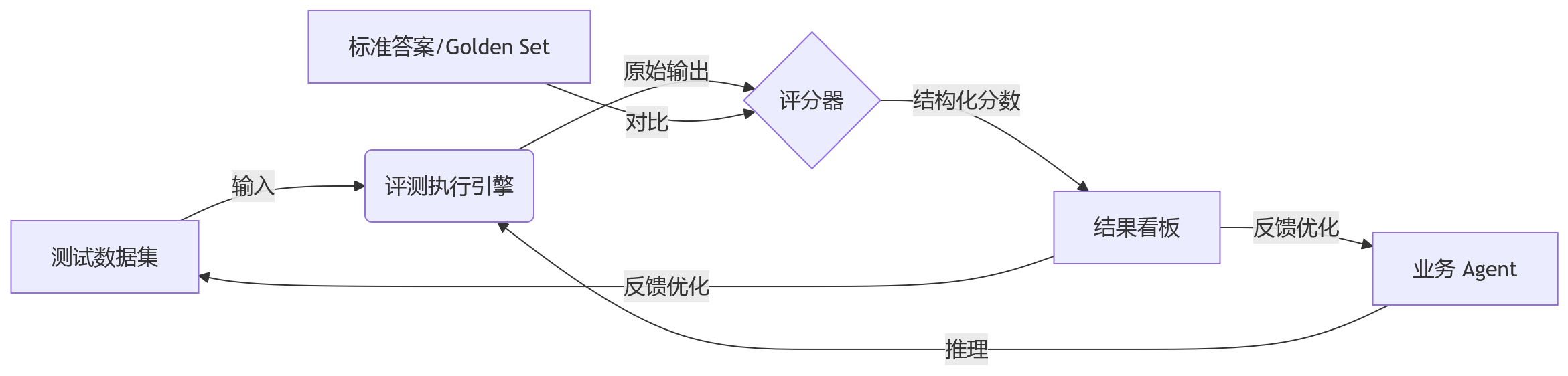
在这个架构中,最关键的是评分器(Scorer)的设计。早期大家倾向于用规则匹配,比如检查输出里是否包含特定字段。但随着 Agent 处理的任务越来越开放,规则维护成本会急剧上升。现在的趋势是采用 LLM-as-a-Judge,即利用一个大模型来判断另一个模型输出的质量。
但这引入了新的问题:评委本身的可信度如何保证?如果评委模型能力不足,会产生误判;如果评委成本过高,大规模跑分又不现实。这就是为什么我们需要工程化手段来平衡——通过分层评测策略,简单问题走规则,复杂问题走大模型评分,敏感问题引入人工复核。
二、基于 Claude Code 的五步搭建法
既然核心难点在于“搭建”这套基础设施的初始投入,那么利用编码能力强的模型来加速这一过程就显得尤为合理。这里提到的 Claude Code,并非指某个特定的产品,而是指代一类具备上下文感知和全栈代码生成能力的 AI 编程助手。用它来构建评测框架,本质上是利用其“理解意图并生成工程代码”的能力,缩短从想法到运行的路径。
整个过程可以拆解为五个关键步骤,每一步都对应着评测框架的一个工程组件。
1. 定义评估指标体系
不要一开始就动手写代码。先让模型帮你梳理指标。对于业务 Agent,指标通常分为三类:准确性(是否解决了问题)、安全性(是否有幻觉或违规)、效率(Token 消耗与响应时间)。
你可以直接输入业务场景描述,要求模型输出一套符合 Pydantic 规范的指标 Schema。这比手动设计数据结构要快得多,且更容易保持类型安全。例如,针对一个客服 Agent,指标可能包括 intent_match_score、policy_violation_flag 等布尔值或浮点数。
2. 生成黄金数据集(Golden Set)
高质量的评测离不开高质量的测试用例。手动构造几百条覆盖正常、异常、边缘情况的测试数据非常耗时。利用模型生成 Golden Set 是目前最高效的手段。
这一步的关键是提示词工程。你需要让模型扮演“测试工程师”,根据你提供的业务文档,生成不同难度等级的问答对。同时,必须要求模型生成对应的“预期行为描述”,而不仅仅是标准答案,因为 Agent 的输出往往具有多样性,死板的答案比对没有意义。
3. 构建执行管道脚本
这是 Harness 的骨架。你需要一个能够批量读取测试集、调用 Agent API、收集输出并调取评分器的脚本。使用 Python 配合 LangChain 或类似框架是常见选择。
借助代码助手,你可以快速生成带有错误重试机制、并发控制以及日志记录的基础模板。这里有一个容易被忽视的细节:断言的稳定性。网络波动或模型延迟可能导致偶发失败,脚本中必须包含超时处理和降级逻辑,否则一次评测跑一半就挂了,数据是不可信的。
4. 配置自动化评分器
评分器可以是外部的大模型 API,也可以是本地部署的小模型。在这一步,需要生成适配不同评分模型的 Wrapper 代码。
如果是 LLM-as-a-Judge,Prompt 的格式至关重要。建议让代码助手生成标准化的评分 Prompt 模板,其中包含明确的评分准则(Rubric)。例如:“请根据以下维度打分:1. 信息完整性 2. 语气友好度 3. 事实准确性。总分 10 分。”并将输出格式限制为 JSON,方便解析。
5. 集成 CI/CD 流水线
评测不应是一次性的活动,而应嵌入开发流程。理想情况下,每次 Agent 版本的变更(如 Prompt 更新或知识库刷新),都应该触发自动评测。
配置 GitHub Actions 或 GitLab CI 脚本,当代码合并时自动运行评测套件,并将结果作为 Pull Request 的评论反馈给开发者。如果关键指标下降超过阈值,直接阻断合并。这需要配置环境变量管理和密钥安全,代码助手可以帮你生成基础的 YAML 配置文件,减少运维配置的手动工作量。
三、效率对比与现实约束
采用这套方案后,最直观的变化是评测周期的压缩。过去需要测试人员花一周时间准备数据、人工打分、统计 Excel,现在变成开发人员提交代码后,CI 自动跑分,半天内出报告。
为了更清晰地展示差异,我们可以对比一下传统方式与 Harness 工程化方式在几个维度的表现:
| 维度 | 传统人工/脚本评测 | Harness 工程化评测 |
|---|---|---|
| 准备周期 | 数天至数周 | 数小时至一天 |
| 覆盖范围 | 随机抽样,易漏边缘 Case | 全覆盖,可针对性生成 Case |
| 客观性 | 依赖个人经验,主观性强 | 基于统一 Rubric,可追溯 |
| 迭代速度 | 版本回归成本高 | 支持每日多次回归 |
| 维护成本 | 脚本分散,难以复用 | 模块化,易于扩展 |
然而,工程化并不意味着银弹。在实际落地中,有几个现实约束必须正视。
首先是成本问题。如果评测集规模很大,且全部依赖 LLM-as-a-Judge,Token 费用会是一笔不小的开支。合理的做法是建立分级评测机制:90% 的常规 Case 用规则或小模型校验,只有 10% 的复杂 Case 才调用高成本的评审模型。
其次是“评委偏见”。用于评测的模型本身可能存在偏好,比如倾向于长文本或特定风格。这会导致评测结果不能真实反映业务质量。解决办法是定期轮换评测模型,或者引入多模型投票机制(Ensemble Voting),以平滑单一模型的偏差。
最后是数据隐私。如果业务数据敏感,不能直接传给公共大模型进行评测。这时需要在本地部署小模型作为 Judge,或者对数据进行脱敏处理。这会增加架构的复杂度,但属于安全合规的必要代价。
四、关于演进的思考
从人工抽检到自动化 Harness,本质上是测试左移在 Agent 领域的体现。我们不再等待上线后再发现问题,而是在代码提交前就通过系统化的手段暴露风险。
在这个过程中,Claude Code 这类工具的价值不在于替代人类做决策,而在于消除重复劳动。它让我们能快速验证想法,快速搭建原型,从而有更多时间去思考那些真正影响业务本质的问题:指标定义是否准确?数据分布是否具有代表性?评测结果能否指导产品改进?
技术演进总是伴随着工具的革新。当评测变得像写单元测试一样简单时,Agent 的开发门槛才会真正降低。目前来看,Harness 工程化已经具备了成熟的条件,剩下的只是如何在具体业务场景中做好成本与精度的平衡。这没有标准答案,只能靠每一次真实的迭代去打磨。