AI Agent 正在快速进入企业生产环境,但安全团队的响应往往滞后于业务落地。过去我们习惯把“用户”作为信任的最小单元,配合“应用”作为访问边界。但在 Agent 场景下,一个账号背后可能是多个自主决策的智能体,它们能跨系统调用 API、读取敏感数据、甚至触发资金流转。传统的基于会话(Session)和令牌(Token)的验证机制,很难捕捉到 Agent 在动态执行过程中的真实意图。
Google 近期提出的 Beyond Zero 概念,核心在于将信任边界进一步下沉。这不仅仅是技术升级,更是对“信任”定义的重构。如果继续用管人的方式管 Agent,要么过度限制导致业务无法跑通,要么放开权限埋下巨大隐患。我们需要重新审视架构中的授权逻辑,找到适应智能体时代的安全基线。
一、传统零信任在 Agent 面前的失效
零信任(Zero Trust)理念流行多年,核心假设是“永不信任,始终验证”。但在实际落地中,大多数企业的实践停留在网络层或网关层,本质上是“应用级零信任”。只要通过了身份认证(IAM),拿到了有效的 JWT 或 Session ID,后续对该应用的访问通常被视为可信。
这种模式在人类操作场景下是合理的,因为人类的行为具有连续性和可解释性。但在 AI Agent 介入后,矛盾开始暴露。
Agent 的工作模式通常是链式调用。一个简单的任务可能涉及查询数据库、调用支付接口、发送通知等多个步骤。在传统架构中,Agent 获取一次令牌,就能在这些微服务间自由穿梭。一旦令牌泄露,或者 Agent 本身被 Prompt Injection 攻击诱导,攻击者获得的是整个应用层面的权限,而不是单个操作的权限。
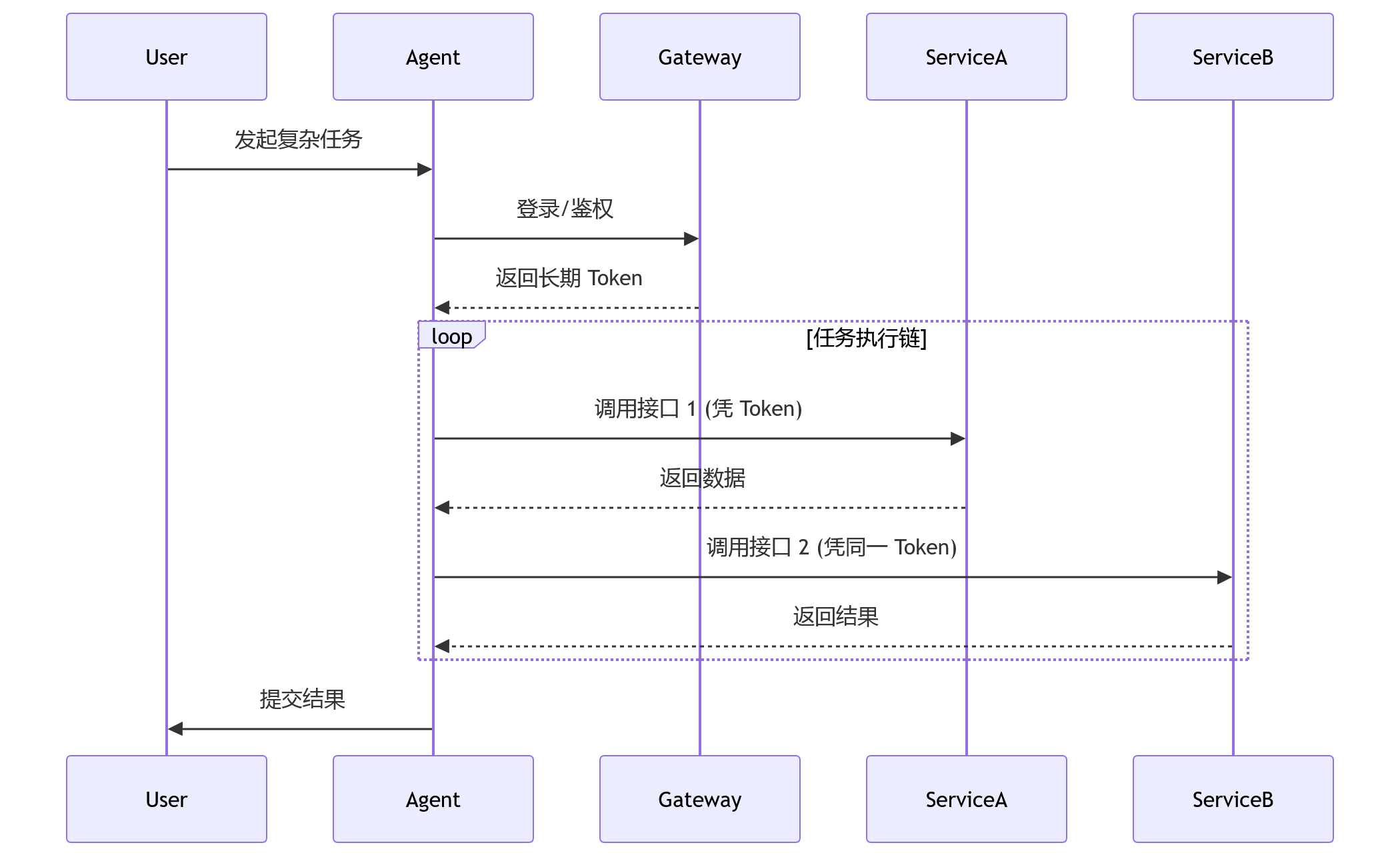
上图展示了典型的传统流程。鉴权只发生在入口,内部服务之间缺乏细粒度的校验。对于 Agent 而言,这意味着它可以在不经过再次确认的情况下,执行超出原始意图的操作。比如,用户让 Agent“查询订单”,Agent 为了完成上下文理解,可能会调用“导出账单”接口,而后者在风险等级上远高于前者。
这里存在一个根本性的错位:安全策略是基于静态角色定义的,而 Agent 的行为是动态且不可预测的。很多团队在初期尝试给 Agent 分配“超级管理员”角色以便开发,上线后却难以回收,这就是典型的“权限膨胀”。
二、动作级授权的核心逻辑
Beyond Zero 架构试图解决的核心问题,就是把信任单元从“应用(Application)”缩小到“动作(Action)”。
这不是简单的增加鉴权点,而是改变策略引擎的判断维度。传统的 RBAC(基于角色的访问控制)关注的是 Who(谁)+ What(什么资源)。而在 Agent 场景下,必须引入 How(怎么操作)和 Context(当前上下文)。
具体实施时,有几个关键变化值得注意:
1. 意图与执行的分离
在动作级授权中,Agent 发起请求时,不能仅携带身份凭证,还需要声明当前的操作意图(Intent)。这个意图需要被策略引擎实时评估。例如,Agent 想要“删除文件”,策略引擎不仅要检查“该用户是否有删除权限”,还要判断“该删除操作是否符合当前对话上下文的预期”。
这要求我们在 API 网关或侧车(Sidecar)层面部署更精细的策略执行点(PEP)。每一次关键动作,都需要经过策略决策点(PDP)的实时计算。
2. 动态上下文感知
静态策略无法应对 Agent 的动态行为。新的架构强调上下文注入。比如,当 Agent 访问某个数据时,系统需要记录它的来源、之前的操作序列、以及当前的置信度分数。如果 Agent 在短时间内频繁切换操作对象,或者访问路径偏离常规模式,策略引擎应自动收紧权限,甚至触发二次验证。
这就好比银行柜员办理业务,不仅是看工牌,还要看监控录像里的操作是否符合规范。
3. 最小权限的动态收敛
传统权限模型往往是“授予即拥有”。动作级授权则倾向于“按需申请,即时生效,用完即焚”。对于 Agent 调用的临时性高权限接口,可以生成短生命周期的凭证(Short-lived Credentials),仅在特定操作窗口内有效。
这种设计增加了架构复杂度,但对于防止 Agent 被劫持后的横向移动至关重要。即使攻击者控制了 Agent,它也无法利用长时效令牌进行持久化破坏。
三、工程落地的现实约束
理想很丰满,但落实到代码和运维层面,动作级授权面临不少挑战。作为架构师,在做技术选型时必须清楚这些 Trade-off。
性能损耗
这是最直接的代价。如果每个 SQL 查询、每个 HTTP 调用都要经过一次远程策略引擎的评估,延迟会显著增加。在高并发场景下,策略服务很容易成为瓶颈。
优化方案通常包括:
- 本地缓存策略:在边缘节点或 Sidecar 中缓存短期有效的策略判定结果。
- 异步审计:非关键路径的动作可以先放行,后审计,通过事后分析发现异常并阻断后续行为。
- 分级鉴权:区分高风险动作(写、删、转账)和低风险动作(读、查),只对高风险动作强制实时校验。
策略定义的复杂性
用自然语言描述“允许 Agent 在下午 2 点到 4 点读取财务数据”很简单,但写成机器可执行的策略语言(如 OPA Rego, Cedar)则非常繁琐。随着业务规则增多,策略库会变得难以维护。
建议采用分层策略管理。基础安全策略(如 DLP 规则)由安全团队统一管控,业务逻辑策略由业务团队定义,但必须经过合规审查。同时,要提供可视化的策略模拟工具,让开发者能在上线前预演 Agent 的行为路径。
可观测性与归因
当 Agent 出错或被攻击时,排查难度比人类操作大得多。日志里不再是简单的“用户 A 点击了按钮”,而是"Agent 实例 ID-XYZ 在上下文 C 下触发了动作 M"。
这就要求全链路追踪系统(Tracing)必须能够关联 Agent 的任务流。在分布式系统中,保持 TraceID 贯穿 Agent 的多个子调用是关键。否则,一旦发生数据泄露,你很难定位是哪个具体的 Prompt 导致了越权访问。
// 示意代码:动作级鉴权的拦截器结构
class ActionAuthInterceptor {
async intercept(context) {
const { userId, action, resource, metadata } = context;
// 1. 基础身份校验
if (!await verifyIdentity(userId)) throw new AuthError();
// 2. 动作意图校验 (核心差异点)
const policyResult = await pdp.evaluate({
subject: userId,
action: action,
resource: resource,
context: metadata // 包含 Agent 状态、置信度等
});
if (!policyResult.allow) {
auditLog.record('denied', context);
throw new PermissionDeniedError(policyResult.reason);
}
return true;
}
}
这段代码展示了与传统鉴权最大的不同:context 字段的存在。它允许我们将 Agent 的运行状态纳入决策变量,从而实现动态风控。
四、架构演进的思考
Google 推动这一变化的背后,是对云原生和安全边界的持续探索。Beyond Zero 并非一夜之间的颠覆,而是对现有零信任体系的必要修补。
对于企业技术负责人来说,不必等到全面重构才行动。可以从以下几个切入点开始:
- 梳理特权账号:清理所有赋予 Agent 的长期高权限账号,改为临时的凭据交换机制。
- 强化审计日志:确保所有 API 调用都有完整的上下文记录,特别是涉及 Agent 自动生成的请求。
- 试点动作级策略:在非核心业务线上,先尝试对部分敏感接口实施细粒度授权,观察性能影响。
安全架构的本质是在可用性与安全性之间寻找平衡点。AI Agent 带来了效率的飞跃,也放大了失控的风险。将信任边界下沉到动作粒度,是目前看来最务实的防御纵深构建方式。它不会完全消除风险,但能将风险控制在可接受、可追溯的范围内。
未来的竞争不仅是算法的竞争,更是架构韧性的竞争。谁能更安全地驾驭 Agent,谁才能在智能化浪潮中走得更远。