












































最近智能体(Agent)的概念很火,但真正在企业里跑通的案例并不多。很多团队把精力花在了调优 Prompt 或更换大模型上,却忽略了更底层的问题:智能体怎么理解企业的业务逻辑?当它需要调用财务系统审批预算,或者从 CRM 里拉取客户历史时,面对的是成千上万张表结构和接口文档。没有统一的理解框架,智能体要么产生幻觉,要么在复杂的业务链条中断链。
这其实是老问题的新变种。过去我们做系统集成,靠的是中间件和 ESB;现在做智能体,需要的是一种能让机器“读懂”业务意图的结构化描述。Agentic Ontology(智能体本体)就是这个方向的一种尝试。它不只是知识图谱的简单延伸,而是专门为智能体的规划、推理和执行设计的语义层。
这种架构设计意味着要在灵活性和规范性之间做取舍。企业希望智能体能快速适应变化,但本体又要求相对稳定的定义。如何在动态的业务环境中维护这套骨架,决定了它是成为转型的加速器,还是新的技术债源头。
一、智能体时代的集成困局
传统的企业数字化建设,往往陷入一个循环:业务部门提需求,开发团队建系统,数据沉淀在孤岛里,最后通过点对点接口打通。随着系统数量增加,集成复杂度呈指数级上升。对于人类开发者来说,这可以通过文档和沟通解决,但对于自主运行的智能体,模糊的接口定义是致命的。
智能体的工作流通常包含感知、规划、行动三个环节。感知依赖上下文,规划依赖对任务分解的理解,行动依赖工具调用。如果底层的“世界模型”不一致,智能体就无法可靠地执行多步任务。比如一个简单的“发起报销”流程,可能涉及 OA 系统、ERP 系统和银行支付接口。每个系统的字段命名不同,状态流转逻辑不同,甚至同一个概念在不同系统里有不同的枚举值。
如果没有统一的语义映射,智能体每次都要重新学习这些规则。这不仅增加了 Token 消耗,更重要的是降低了执行的确定性。在生产环境里,确定性比灵活性更重要。很多 POC 项目之所以无法推广,就是因为它们在演示环境里假设了完美的数据结构,而真实环境充满了历史遗留数据和边缘情况。
此外,现有的向量检索(RAG)方案主要解决非结构化数据的检索问题,但在处理结构化业务流程时显得力不从心。RAG 擅长回答“是什么”,而智能体需要知道“怎么做”。这就需要一个能够表达实体关系、操作约束和业务规则的中间层,这就是本体存在的意义。
二、Agentic Ontology 的核心构成
Agentic Ontology 本质上是一套可执行的语义规范。它定义了企业数字世界里的核心对象、它们之间的关系以及允许的操作。与传统数据库 Schema 不同,它更关注业务含义而非存储效率;与知识图谱相比,它更强调动作的可编排性。
一个完整的智能体本体通常包含三个要素:
| 要素 | 说明 | 示例 |
|---|---|---|
| 实体(Entities) | 业务中的核心对象 | 订单、客户、发票、员工 |
| 关系(Relations) | 实体间的连接与约束 | 订单属于客户、发票关联订单 |
| 能力(Capabilities) | 可被触发的业务动作 | 创建订单、核销发票、查询余额 |
这种结构让智能体能够将用户的自然语言指令转化为具体的 API 调用序列。例如,用户说“帮我把上个月未结清的订单都发个提醒”,智能体不需要去猜测“未结清”对应哪个数据库字段,而是直接在本体中找到 Order 实体,筛选 Status != PAID,并调用 SendReminder 能力。
这里有一个关键的工程细节:本体的粒度控制。如果把所有细节都放进本体,维护成本会极高;如果太粗,智能体又缺乏足够的上下文。实践中建议采用分层策略,核心业务域(如订单、库存)建立精细的本体,辅助域保持较粗的粒度。
// 示意代码:简化的本体能力定义
{
"entity": "Order",
"attributes": {
"order_id": {"type": "string"},
"status": {"type": "enum", "values": ["PENDING", "PAID"]},
"amount": {"type": "decimal"}
},
"actions": [
{
"name": "check_status",
"input": ["order_id"],
"output": ["current_status"]
}
],
"constraints": [
"Only admin can modify status"
]
}
这种定义方式类似于 GraphQL Schema,但加入了业务约束和权限逻辑。它使得智能体在生成工具调用参数时,能提前进行合法性校验,减少无效请求。同时,本体也充当了版本控制的载体,当业务逻辑变更时,先更新本体定义,再调整下游实现,保证了对接面的稳定性。
三、构建实践与工程权衡
落地 Agentic Ontology 最大的挑战不在于技术选型,而在于治理。企业内部的术语混乱是常态,销售说的“线索”和市场部说的“商机”可能指代同一件事,也可能完全不同。构建本体过程,实际上是一次业务梳理和标准化的过程。
建议从核心痛点切入,而不是试图一开始就覆盖全公司。选择 1-2 个高频且逻辑闭环的场景,比如“采购到付款”或“客户服务工单”,先跑通小范围的闭环。在这个过程中,验证本体定义的准确性,收集智能体在实际调用中的错误日志,迭代优化语义模型。
以下是典型的演进架构图,展示了本体层如何解耦上层智能体与下层异构系统:
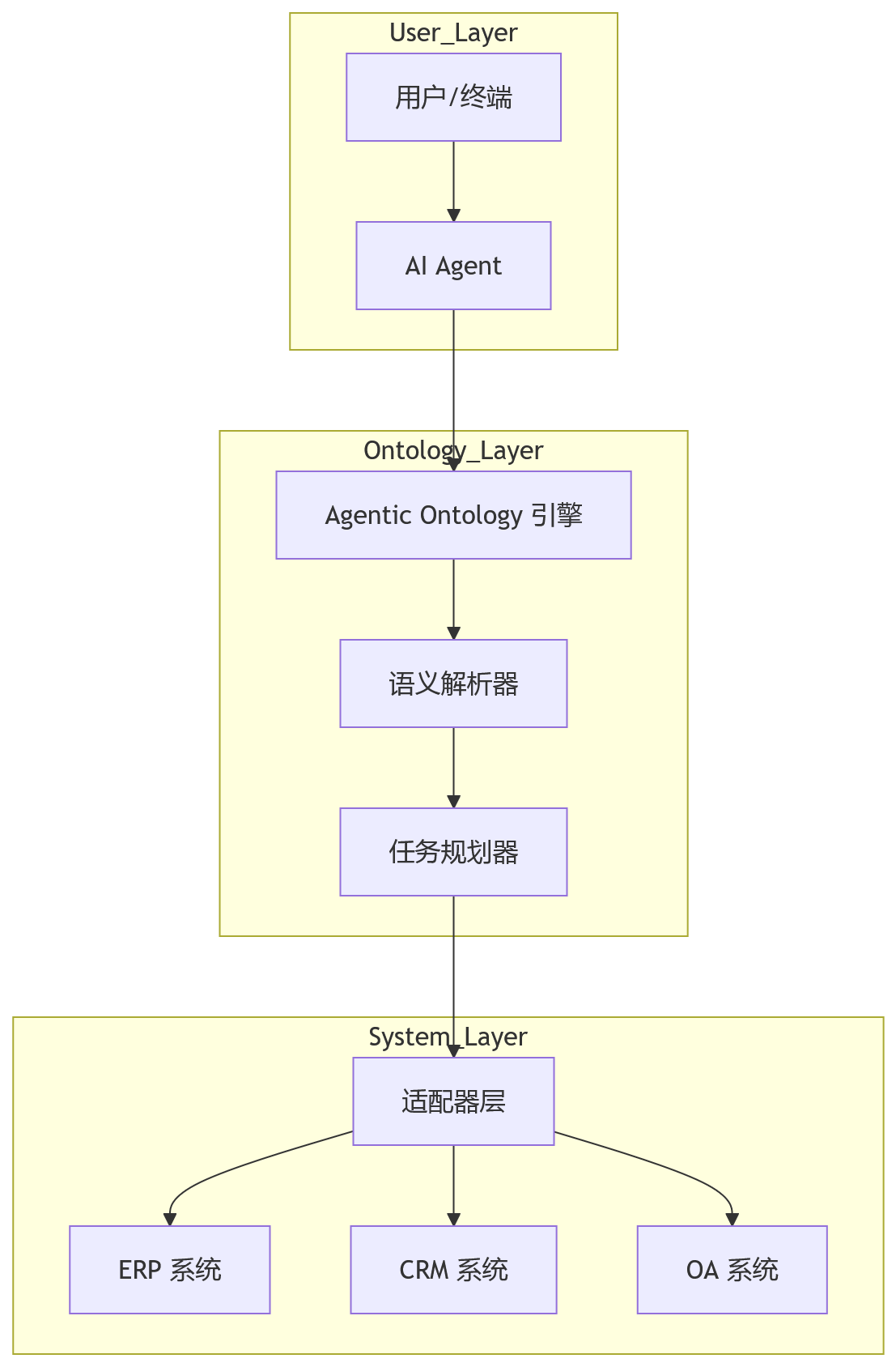
在这个架构中,Adapter 层负责将本体标准动作转换为具体系统的 API 调用。这意味着即使底层系统替换,只要本体定义不变,智能体的行为逻辑就不受影响。这是实现系统演进的关键隔离层。
当然,这也带来了额外的维护成本。每新增一个业务系统,都需要编写对应的适配器和映射规则。如果企业系统极其碎片化,这个工作量可能会超过收益。因此,适用边界很明确:适合业务流程相对稳定、系统集成度高、且对自动化准确率有要求的场景。对于初创公司或快速变化的业务线,过度设计本体反而会拖慢迭代速度。
另外要注意本体的版本管理。业务规则变了,本体也要变。智能体基于旧版本训练的策略可能需要重新评估。建议在部署时引入灰度机制,新旧本体并行运行一段时间,对比智能体的执行成功率,确认无误后再完全切换。
四、长期视角下的价值
Agentic Ontology 不是一劳永逸的解决方案,它是一个持续演进的过程。它的价值在于为企业的数字世界提供了一个可解释、可编排的骨架。随着智能体能力的增强,这个骨架会越来越重要。
短期看,它能降低智能体的开发门槛,提高任务完成的成功率。长期看,它积累了企业的业务逻辑资产。这些数据不仅能服务于当前的智能体,未来也可以用于数字孪生仿真、合规审计分析等场景。
最终,技术的选择还是要回归到业务目标。如果企业只是想要一个客服聊天机器人,简单的知识库就够了。但如果目标是让智能体深入参与业务流程,处理跨系统的复杂任务,那么投入资源构建一套合理的本体层,就是值得的工程投资。这需要技术团队与业务团队的深度配合,共同定义那个“唯一真理来源”。








