在很多技术讨论甚至项目立项会上,本体(Ontology)和知识图谱(Knowledge Graph)这两个词经常被交替使用。有时候团队说要做“知识图谱”,实际交付的只是一堆杂乱的关系数据;有时候花大量时间构建“本体模型”,最后却因为没有数据支撑而束之高阁。这种概念的模糊,往往源于对两者在系统架构中定位的理解偏差。
本质上,它们处于知识处理链条的不同环节。如果把构建一个智能系统比作盖楼,本体更像是建筑图纸和规范标准,定义了房间的类型、墙壁的连接方式以及承重限制;而知识图谱则是已经建成的楼房,里面住了人、摆了家具,有了具体的状态。
很多时候,问题不出在技术选错,而出在层级搞混。试图用本体的严格性去约束业务快速变化的数据,或者试图在没有本体指导的情况下直接堆砌海量三元组,都会导致系统后期难以维护。我们需要从工程视角重新审视这两者的边界,明确在什么场景下需要引入哪一层级。
一、抽象层级的错位
区分两者的核心,不在于存储格式,而在于抽象程度。
本体关注的是“类”与“关系”的定义。它规定了一个领域内有哪些概念(Class),这些概念之间有什么样的层次结构(SubclassOf),以及属性之间的约束(Domain/Range)。比如在一个医疗系统中,本体层会定义“药物”是一个类,“治疗”是一种关系,并且规定“治疗”这个关系的起点必须是“疾病”,终点必须是“药物”。
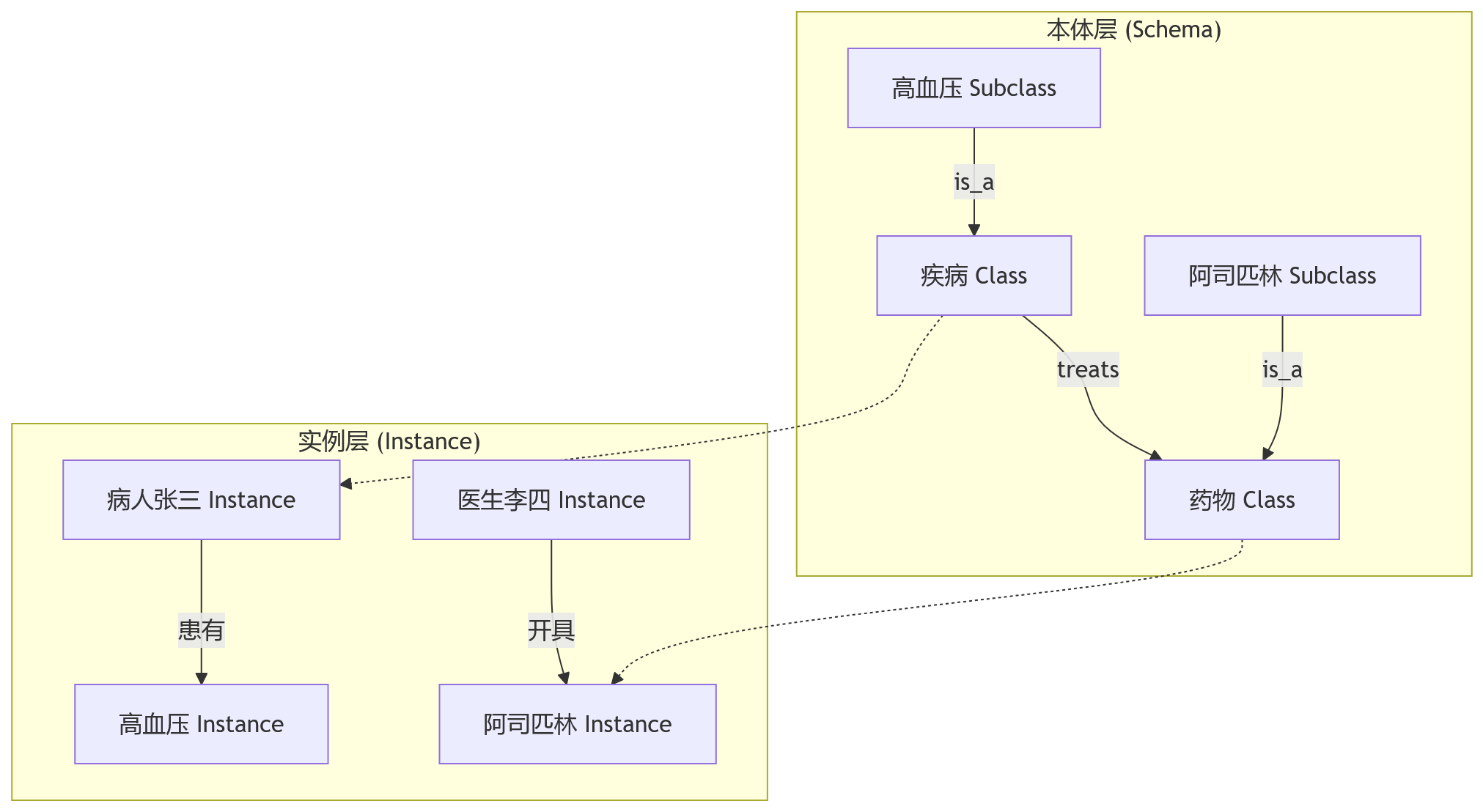
上图展示了典型的分层结构。本体层是静态的元数据,一旦定义完成,修改成本较高,因为它牵涉到推理规则的变更。知识图谱通常指代的是基于某种模式存储的具体数据实例。但在工业界,当我们提到“建设知识图谱”时,往往指的是包含本体建模、数据存储、查询接口在内的整体解决方案。
这种错位带来的第一个工程问题是:一致性。如果本体定义过死,业务方新增一种新药类型时,可能需要修改整个 schema,流程繁琐;如果本体缺失,图谱里可能会出现“治疗”关系连接了“病人”和“药厂”这种逻辑错误的数据。
二、驱动力的演变
为什么学术界推崇本体,而工业界更爱提知识图谱?这背后是技术驱动力的变化。
早期的语义网(Semantic Web)愿景希望机器能理解数据含义,因此强调严格的逻辑推理和形式化描述,OWL 等本体语言应运而生。它的目标是通用性和互操作性,要求极高的严谨度。但这种严谨度带来了高昂的计算开销和维护成本,导致大规模落地困难。
Google 在 2012 年提出 Knowledge Graph 时,目标截然不同。它不是为了让机器进行复杂推理,而是为了增强搜索结果的相关性和展示实体信息。这里的重点是“连接”和“检索”,而非“推理”。因此,工业界的知识图谱往往放宽了对本体的依赖,更多采用图数据库(如 Neo4j, NebulaGraph)存储灵活的关系,Schema 往往随业务发展动态演进。
这就形成了一个有趣的矛盾:理论上,没有本体的知识图谱是一盘散沙;实际上,过于严格的本体又拖慢了业务迭代。很多团队的做法是折中——保留核心的本体框架(Core Ontology),允许外围数据以弱结构化的方式接入。这种混合模式虽然牺牲了一部分推理能力,但换来了系统的生存空间。
三、工程落地的现实约束
在决定引入本体还是仅构建图谱时,有几个现实约束必须考虑。
首先是维护成本。本体不是写一次就完事的。随着业务扩展,概念会分裂、合并,属性会增减。如果缺乏专门的治理团队,本体很快就会变成无人维护的文档,最终导致线上数据与模型脱节。相比之下,轻量级的图谱 schema 调整起来更灵活,适合快速迭代的互联网产品。
其次是推理需求。如果你的业务需要自动发现隐性关系(例如:A 是 B 的父亲,B 是 C 的父亲,推导 A 是 C 的祖父),那么严格的本体和推理机是必须的。但如果只是做关联推荐、搜索排序,简单的图遍历算法配合索引通常足够,引入复杂的推理引擎反而会增加延迟。
最后是数据质量。本体对数据规范性要求极高,数据清洗的成本往往是最大的投入点。在冷启动阶段,数据源杂、标准不一,强行套用复杂本体会导致大量数据无法入库。这时候,先跑通图谱链路,再逐步收敛 schema,通常是更稳妥的路径。
| 维度 | 强本体模式 | 轻量图谱模式 |
|---|---|---|
| Schema 刚性 | 高,修改需审批 | 低,支持动态扩展 |
| 推理能力 | 支持复杂逻辑推理 | 仅支持路径查询 |
| 数据清洗 | 成本高,需标准化 | 容错率高,可容忍噪声 |
| 适用场景 | 金融风控、医疗诊断、合规审计 | 搜索推荐、社交网络分析 |
| 技术栈 | OWL, RDF, 推理机 | Property Graph, Gremlin/Cypher |
四、选型决策路径
面对具体项目时,不要纠结于名词,要看业务目标。
如果是企业内部的知识管理系统,旨在沉淀专家经验并辅助决策,建议优先设计本体。因为这类系统生命周期长,数据价值在于准确性,前期的建模投入能在后期通过自动化推理收回成本。这里的关键是找到业务中的“不变量”,将其固化为本体。
如果是面向用户的搜索或推荐场景,优先考虑图谱的扩展性。用户行为数据变化快,标签体系迭代频繁,此时应允许 schema 演化。可以建立一个“软本体”,即不强制校验所有数据,但在关键节点上进行类型约束,平衡灵活性与规范性。
还有一种常见的误区是认为上了知识图谱就能解决所有非结构化数据处理问题。其实图谱只是中间态,它依赖于上游的信息抽取(IE)和下游的应用层。如果 NLP 提取的准确率只有 60%,无论你的本体设计得多精妙,图谱的价值都会大打折扣。
工程上最务实的做法是分阶段演进。第一阶段,聚焦数据连通,建立基础图谱,验证查询性能;第二阶段,识别高频且稳定的模式,提炼为初步本体;第三阶段,引入推理服务,优化数据质量。不要在第一天就追求完美的本体模型,那是学术界的理想状态,不是工程界的生存法则。
技术工具本身没有优劣,关键在于是否匹配当前的业务约束。当你能清晰地说出“我们为什么要在这个阶段引入本体,而不是等到数据量更大时再说”,或者“我们暂时放弃严格推理是为了换取更快的上线速度”时,说明你对这两个概念的理解已经脱离了表面,进入了真正的架构思考层面。