很多人用 AI 用到最后,会遇到一个很尴尬的问题:模型越来越强,但自己的工作流并没有变得更稳定。
每天打开一个新对话,重新贴背景、重新讲偏好、重新强调格式、重新纠正同样的问题。短期看,这是在使用 AI;长期看,这更像是在手工维护一个随时失忆的临时工。
提示词当然有价值,但如果一个任务已经重复出现多次,还停留在“复制一段提示词再祈祷它听懂”的阶段,工程上就不太划算了。AI Skills 的意义,恰恰在于把这些重复解释、重复校验、重复纠错的部分,沉淀成可复用的工作流。
一、提示词、Skill、Agent 是三层系统
很多 AI 工作流做不起来,根因往往不是提示词写得不够漂亮,而是把三层东西混在了一起:
| 层级 | 解决的问题 | 典型形态 | 风险 |
|---|---|---|---|
| 提示词 | 单次任务怎么做 | 一段指令、一段上下文 | 依赖人工记忆,难复用 |
| Skill | 某类任务如何稳定执行 | 可触发的流程说明、模板、校验规则 | 需要持续维护 |
| Agent | 如何自主选择流程并调用工具 | 能读文件、调工具、执行任务的系统 | 路由、权限、边界更复杂 |
提示词更像一次性命令。
比如:
帮我总结这篇文章。
Skill 关注的是这类任务背后的稳定方法。
比如:
把一篇 AI 产品文章改写成技术读者能看懂的分析稿:保留原始论点,核对来源,解释机制,去掉营销味,最后输出一份可发布草稿。
Agent 则更进一步。它不只是执行一段文本,而是能判断当前任务适合哪个 Skill,是否需要搜索资料,是否要读取本地文件,是否要调用接口,最终把结果整理出来。
这三层的边界很重要。
如果你试图用一堆提示词文件解决 Agent 层的问题,最后大概率会变成“提示词仓库越来越大,真正能稳定跑的流程越来越少”。这类系统我见过不少,开始时很兴奋,过一段时间就没人维护,因为每个提示词都依赖人来判断什么时候用、怎么组合、怎么验收。
Skill 的价值在于,它把一部分判断前置到了系统里。
二、Skill 本质上是可执行的操作手册
一个 AI Skill 通常并不神秘。很多时候,它就是一份纯文本文件,加上一些辅助材料、脚本和模板。
它的威力不在于格式复杂,而在于两点:
- Agent 能找到它;
- Agent 知道什么时候该用它,以及用完后结果应该长什么样。
这听起来很普通,但对工作流影响很大。
过去你可能会在每次对话里重复说:
注意不要编造来源。 注意输出要分成建议、事实、风险、下一步行动。 注意不要直接写成对外发布文案。 注意社媒信息只能作为线索。
Skill 把这些规则从“人每次提醒”变成“系统默认加载”。
这就是工程化和手工操作的差别。不是模型突然聪明了,而是上下文、边界、校验标准被固定下来了。
一个能用的 Skill,至少要包含这七类信息:
| 要素 | 作用 |
|---|---|
| 名称 | 让系统和人都能快速识别用途 |
| 描述 | 帮助 Agent 判断是否触发 |
| 使用场景 | 明确它适合解决哪类问题 |
| 输入要求 | 告诉用户或 Agent 需要提供什么 |
| 执行步骤 | 固定核心流程,减少临场发挥 |
| 输出格式 | 让结果稳定可消费 |
| 验收标准 | 判断任务是否真的完成 |
这里最容易被低估的是 description,也就是描述字段。
很多 Agent 在真正加载 Skill 全文之前,往往只会先看名字和 description。如果这一行写得太泛,Agent 很可能根本不会选中它。
不及格的```
这句话几乎没有路由价值。什么叫研究?调研竞品算不算?写论文算不算?做市场分析算不算?写公众号文章算不算?
更合格的描述应该像这样:
yaml
这一行其实做了很多事:
- 说明输入类型:话题、链接、模糊问题;
- 说明任务目标:研究简报;
- 说明输出结构:建议、事实、注意点、下一步行动;
- 说明排除边界:不负责最终发布文案。
一个好的 description,本质上就是 Skill 的路由层。
三、不及格 Skill 常常像许愿
很多团队第一次写 Skill,会写得很像“愿望清单”。
比如:
写一条更好的推文。
让它更容易传播。
听起来像真人。
不要有 AI 味。
这些要求不是完全没用,但它们没法稳定执行。原因很简单:这里没有触发条件,没有输入约束,没有流程,也没有验收标准。
模型只能凭感觉猜。
更可用的写法应该是任务型的:
使用场景:
当用户提供一条 AI 产品发布信息,需要改写成适合 X / Twitter 发布的技术向短帖时使用。
输入:
- 原始产品发布链接或文本
- 目标读者
- 是否需要保留品牌名
- 是否允许加入个人判断
步骤:
1. 阅读原始信息,提取产品真正新增的能力。
2. 区分官方宣称、可验证事实、个人推断。
3. 忽略没有来源支撑的夸张营销表达。
4. 从三个角度中选择一个:
- 功能前后对比
- 使用场景变化
- 底层机制解释
5. 输出一版短帖草稿。
6. 检查是否存在空泛形容词、无来源判断、过度营销表达。
输出:
- 推荐角度
- 短帖正文
- 需要核对的事实
- 不建议使用的表达
这才像一个工作流。
Agent 看到这样的 Skill,知道该做什么,也知道什么不能做。更关键的是,它有了失败时可以修正的结构。
如果输出总是太营销,就强化第 6 步。
如果经常漏掉事实核查,就把“事实 / 推断 / 宣称”拆成固定表格。
如果它总是误用这个 Skill 去写长文章,就在 description 里加排除条件。
Skill 不是一次写完的配置文件,更像一个可以持续打磨的操作手册。
四、Memory 和 Skill 要分开存
很多人会把所有偏好都塞进长期记忆里,结果越用越乱。
比如:
用户喜欢简洁风格。 用户喜欢技术分析。 用户写文章时需要保留来源。 用户发布 X 帖时要先生成 Typefully 草稿。 用户做研究时要优先找一手来源。 用户不喜欢 AI 味。
这些信息混在一起,短期看没问题,长期就会互相污染。模型不知道哪些是稳定偏好,哪些是特定任务流程,哪些只是某次任务里的临时要求。
一个比较实用的区分方式是:
| 类型 | 存什么 | 示例 |
|---|---|---|
| Memory | 稳定偏好 | 用户偏好简洁、克制、有技术判断的表达 |
| Skill | 稳定流程 | 写技术分析稿时,需要核对来源、拆解机制、说明边界、输出发布草稿 |
偏好属于 Memory。
流程属于 Skill。
举个更具体的例子:
Memory:
用户偏好技术文章采用平实、克制、有工程判断的表达方式。
Skill:
当用户提供技术热点或产品案例时,按以下流程生成技术分析文章:
1. 提取核心技术问题
2. 判断文章类型
3. 拆解底层机制
4. 说明工程权衡
5. 给出适用场景和边界
6. 输出适合技术博客发布的正文
这两个信息如果都塞进记忆,Agent 很容易在不该写文章的时候也套写作流程。
分开之后,系统会更干净。Memory 负责“你是谁、你偏好什么”,Skill 负责“这类活怎么干”。
这个边界在复杂 Agent 系统里尤其重要。因为一旦你开始引入工具、定时任务、子 Agent,混乱的记忆会让整个系统越来越不可预测。
五、第一个 Skill 应该从重复任务开始
不要一上来就写十个抽象 Skill。
抽象 Skill 看起来高级,比如:
- 内容创作大师
- 商业分析助手
- 高级研究员
- 全能运营 Agent
这些名字很诱人,但通常不好用。因为边界太宽,触发条件太模糊,验收标准也不稳定。
第一个 Skill 最好从一个你已经重复做过很多次、并且输入输出都比较清楚的任务开始。
比如:
- 把链接整理成研究简报;
- 把会议纪要整理成行动项;
- 把产品更新改写成技术分析;
- 把 Bug 描述整理成排查清单;
- 把接口文档转换成前端调用说明;
- 把客户反馈归类成需求池。
判断标准很简单:
如果同一段提示词你已经复制过两次,它基本就有资格变成 Skill。
下面是一份可以直接改的 Skill 模板。
name: research-brief
# Research Brief(研究简报)
## 什么时候用
当用户需要围绕一个话题、链接、产品、技术问题做资料收集和初步判断时使用。
适用场景:
- 技术选型前的信息收集
- 产品或公司动态研究
- 行业话题初步判断
- 为后续文章、报告、决策做资料准备
不适用场景:
- 直接生成最终对外发布的文案
- 写没有来源支撑的观点稿
- 替代正式法律、财务、医疗等专业判断
## 输入
用户应尽量提供:
- 话题、链接或问题
- 目标读者
- 研究目的
- 必须包含或排除的来源
- 期望输出格式
- 时间范围或地域范围,如有
## 步骤
1. 先复述研究目标,说明这份简报要支持什么决策。
2. 优先查找一手来源,例如官方文档、公告、论文、代码仓库、财报、监管文件。
3. 社媒帖子、媒体报道、二手解读只能作为线索,不能直接当作核心证据。
4. 将信息拆成三类:
- 已有来源支持的事实
- 基于事实做出的推断
- 仍需确认的不确定信息
5. 对关键事实附上来源链接。
6. 如果来源之间存在冲突,要明确指出冲突点。
7. 输出简报,并给出下一步建议。
## 输出格式
请按以下结构输出:
### 建议
用 3-5 条说明当前最值得采取的行动或判断。
### 有来源支持的事实
用列表展示,每条事实后附来源。
### 推断
说明哪些判断是基于现有事实推导出来的,不要伪装成确定事实。
### 注意点
列出信息不足、来源冲突、时间敏感、口径不一致等风险。
### 下一步行动
给出可执行的后续动作,例如继续查证、联系相关方、读取某份文档、做技术验证。
## 容易翻车的地方
- 不要编造来源。
- 不要把社媒热帖当成事实依据。
- 不要把答案埋在一堆链接里。
- 不要为了完整性堆无关背景。
- 除非用户明确要求,否则不要写最终对外发布文案。
## 验收标准
输出完成前检查:
- 关键事实是否都有来源。
- 是否区分了事实、推断和不确定信息。
- 是否说明了来源质量。
- 下一步行动是否具体。
- 是否避免了无来源的确定性判断。
这份模板不复杂,但已经能覆盖很多真实工作流。
真正有价值的地方不在第一版,而在后续迭代。每次 Agent 翻车,都不要只在当前对话里纠正一句“你刚才写错了”。更好的做法是回到 Skill,把失败模式沉淀进去。
比如:
- 它总是编来源,就加更严格的来源校验;
- 它总是写得太长,就限制输出长度;
- 它总是把推断当事实,就强制输出“事实 / 推断 / 未确认”三栏;
- 它经常被误触发,就收紧 description;
- 它该触发时没触发,就补充典型场景。
这就是 Skill 越用越值钱的原因。
六、文件结构不要一开始就搞复杂
一个 Skill 通常可以放在一个小文件夹里。
比如:
research-brief/
SKILL.md
references/
source-quality.md
output-format.md
scripts/
fetch_sources.py
assets/
brief-template.md
各部分职责可以这样拆:
| 文件或目录 | 职责 |
|---|---|
SKILL.md |
主流程,包含触发条件、步骤、输出、验收 |
references/ |
判断标准、风格规范、来源质量说明 |
scripts/ |
确定性的机械任务,例如抓取、格式转换、校验 |
assets/ |
模板、示例、固定素材 |
这里有一个很实际的工程权衡:不要把所有事情都交给模型。
模型擅长处理模糊判断,比如总结、归纳、改写、推理、生成候选方案。
脚本擅长处理确定任务,比如:
- 拉取 URL 内容;
- 检查链接是否可访问;
- 转换 Markdown 格式;
- 统计字数;
- 校验 JSON Schema;
- 批量重命名文件;
- 调用固定 API。
如果让模型做太多机械工作,翻车概率会明显上升。它可能漏掉字段,可能格式不稳定,可能把一个确定性任务变成“看心情执行”。
比较稳的做法是:
需要判断的交给模型,需要确定性的交给脚本。
这句话听起来朴素,但很多 Agent 系统的稳定性差,问题就出在这里。
一个简单结构可以长这样:
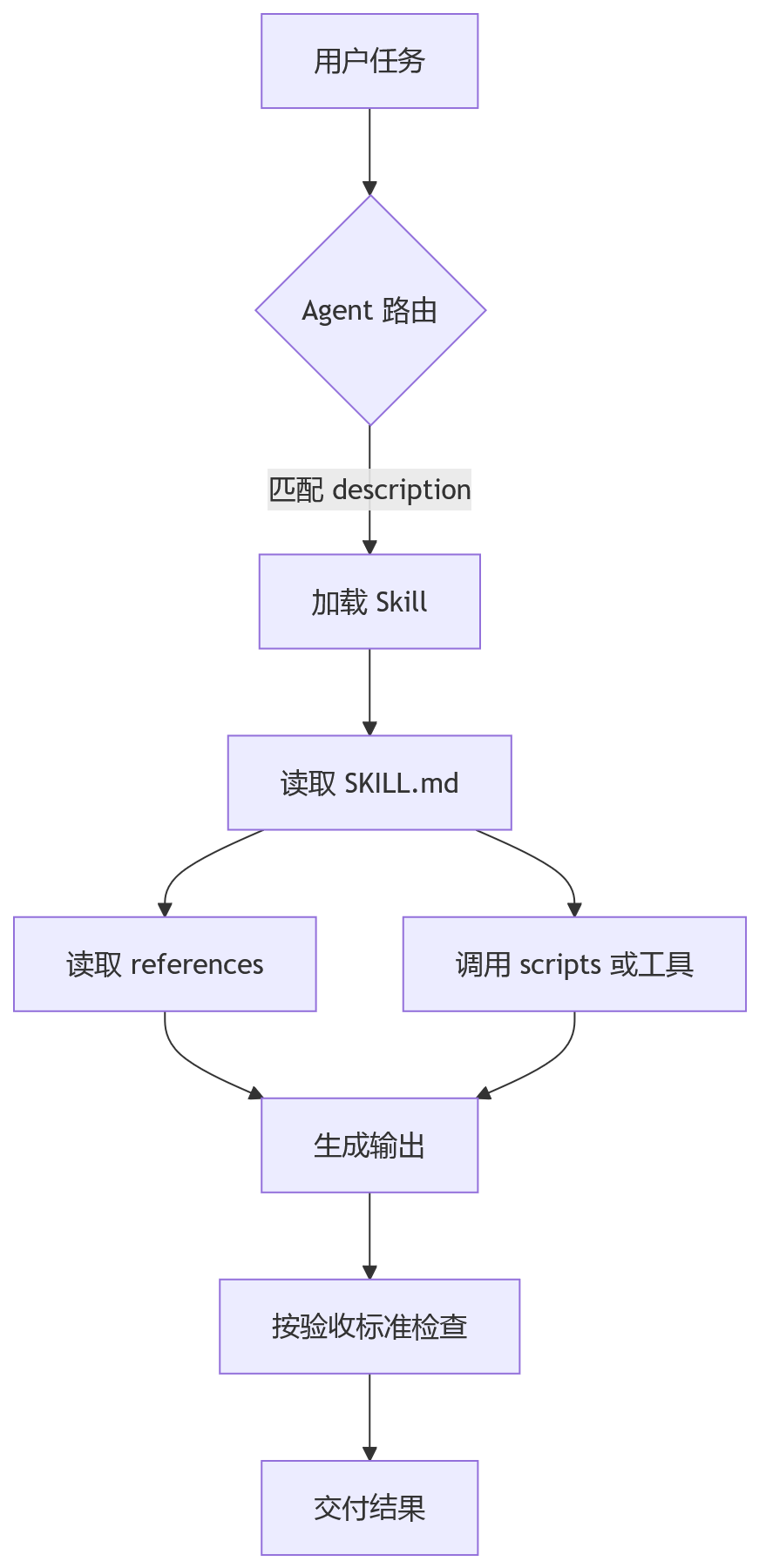
这张图里最关键的是两层:
- 路由层:Agent 是否能选对 Skill;
- 验收层:输出是否符合 Skill 的完成标准。
很多人只写中间的执行步骤,忽略这两层,结果就是“偶尔很好用,偶尔很离谱”。
七、测试 Skill 要测触发边界
Skill 写完不算完。Agent 真能正确调用,才算进入可用状态。
测试至少跑四组。
显式触发
直接点名 Skill:
对下面这个主题使用 research-brief 这个 Skill:
看它是否按步骤执行,输出结构是否稳定。
这个测试主要确认 Skill 内容本身能跑通。
自然触发
不用提 Skill 名,只描述任务:
你能把这个模糊问题整理成一份有源可查的决策简报吗?
如果 Agent 没有加载 research-brief,说明 description 不够准,或者 Skill 名称不够有辨识度。
这种问题在真实场景里很常见。用户不会每次都记得 Skill 名,系统必须能从自然语言里判断任务类型。
过度触发测试
给一个相邻但不该使用该 Skill 的任务:
基于这份研究材料,写一篇对外发布的宣传文案。
如果 research-brief 被错误触发,就说明排除条件不够明确。
可以在 description 或“不适用场景”里加一句:
不要用于生成最终对外发布的营销文案、社媒帖或文章成稿。
触发不足和过度触发都麻烦。
触发不足,会导致 Skill 沉睡在系统里;过度触发,会让 Agent 到处套错流程。后者更隐蔽,因为它看起来也在认真执行,只是执行了错误的方法。
输出检查
最后看结果是否满足验收标准:
- 有没有建议;
- 有没有来源;
- 有没有区分事实和推断;
- 有没有注意点;
- 有没有下一步行动;
- 有没有超出 Skill 边界。
如果某些问题反复出现,别只改提示词,直接改 Skill。
一个 Skill 的成熟,不靠第一次写得多长,而靠真实任务里的失败反馈。
八、Skill 库会变成操作层
单个 Skill 解决一个重复任务。
一组 Skill 才会逐渐变成操作层。
比如:
| 组合 | 价值 |
|---|---|
| Skills Memory | 记住稳定偏好,并按需加载对应流程 |
| Skills Tools | 在流程中完成搜索、读取文件、调用接口、生成草稿、跑校验 |
| Skills 定时任务 | 每天、每周或事件触发时自动运行同一套流程 |
| Skills 子 Agent | 把研究、写作、审稿、运营拆给不同角色 |
| Skills 配置文件 | 不同 Agent 使用不同 Skill 库、工具权限和边界 |
这时 AI 不再只是一个“更会聊天的输入框”。
它开始接近一个由小流程组成的操作系统。每个 Skill 都像一个可调用的命令,Agent 负责理解任务、选择命令、组合工具、交付结果。
当然,这里也有边界。
Skill 并不能解决所有问题。它更适合高频、结构稳定、验收标准相对明确的任务。
不太适合的场景包括:
- 一次性的探索性问题;
- 输入极度不稳定的复杂决策;
- 需要强责任主体的专业判断;
- 结果不可验证、只能靠主观感觉评估的任务;
- 权限、合规、安全风险很高的自动化操作。
尤其是最后一类,要非常谨慎。
当 Skill 和工具、定时任务、外部 API 结合之后,Agent 不再只是生成文本,它可能真的会改文件、发请求、写数据库、触发流程。这个时候就要考虑权限隔离、审计日志、人工确认和回滚机制。
工程上比较稳的策略是:
- 读操作可以适当自动化;
- 写操作要分级授权;
- 发布、付款、删除、批量修改这类高风险动作必须有人确认;
- 所有自动任务要有日志;
- 关键输出要能追溯到输入和来源。
AI 工作流做深了,最后一定会碰到软件工程里的老问题:权限、状态、审计、回滚、边界。只是这次入口变成了自然语言。
九、提示词库会被工作流替代
提示词库是 AI 使用早期很自然的产物。大家发现某些句子好用,就存起来,下次再贴。
它解决了“怎么把指令写得更好”的问题。
但它没有解决这些问题:
- 什么时候该用这段提示词;
- 需要搭配哪些上下文;
- 输出后怎么检查;
- 和工具如何配合;
- 失败后如何沉淀经验;
- 多个任务之间如何组合。
Skills 往前走了一步,把“好提示词”变成“可触发、可执行、可验收的流程”。
这才是它真正值得关注的地方。
如果你现在还没有 Skill,不需要从宏大的 Agent 系统开始。先选一个小任务:
- 重复出现;
- 输入清楚;
- 输出清楚;
- 经常要纠错;
- 你已经给 AI 解释过好几遍。
然后写下四件事:
- 什么时候触发;
- 按什么步骤做;
- 输出长什么样;
- 怎么判断合格。
第一版不用完美。甚至有点粗糙也没关系。
真正重要的是,把一次性的对话经验,从聊天框里拿出来,放进一个可维护的位置。后面每次翻车,都让 Skill 变得更具体一点。
这就是 AI Skills 的工程价值:它不追求一次提示词的惊艳,而是让重复工作越来越稳。[DONE]