Python 项目打包这件事,很多时候只有项目维护者自己觉得“还能用”。CI 能跑、PyPI 能发、用户能安装,看起来问题不大。但一旦下游用户需要自己构建 whl 包,或者项目结构稍微复杂一点,原来那些藏在脚本、CI、目录约定里的隐性逻辑,就会一起冒出来。
RapidOCR 之前一直使用 setup.py setuptools 打包。这个方案并不罕见,也不是不能用。真正的问题在于:它逐渐把版本号生成、目录适配、资源准备、包构建这些本该分层处理的事情揉在了一起。维护者熟悉流程时感觉还好,外部用户接手时就变成了“照着 CI 猜构建步骤”。
这次迁移到 pyproject.toml,表面看是一次打包工具链调整,实际解决的是 Python 项目发布流程的工程可维护性问题。
一、setup.py 能跑,但复杂度被藏起来了
RapidOCR 自从提供 whl 包以来,一直使用 setuptools 打包。早期最关注的一个硬性需求是:版本号必须自动化。
对于开源库来说,版本号自动化很重要。手动改版本号看起来简单,但时间一长很容易出问题:
- tag 是
v3.1.0,包里却还是3.0.9 - 本地构建和 CI 构建版本不一致
- 发布流程依赖维护者记忆
- 下游自行构建时不知道版本从哪里来
为了解决这个问题,RapidOCR 曾经使用过自定义工具 GetPyPiLatestVersion,用于获取指定库在 PyPI 上的最新版本。后来发现 GitHub Actions 在打 tag 时可以直接拿到 tag 名称,于是版本号可以在 CI 中传给 setup.py。
典型流程大致是这样:
name: Push rapidocr to pypi
on:
push:
tags:
- v*
jobs:
TestAndPublish:
runs-on: ubuntu-latest
steps:
- name: Build wheel package
run: |
cd python
python setup.py bdist_wheel ${{ github.ref_name }}
mv dist ../
这个方案在维护者视角下是顺的:打 tag,触发 CI,CI 取 tag,传给 setup.py,然后构建 whl。
问题也在这里。它把关键构建逻辑放到了 CI 里,而不是项目本身。
CI 当然可以承载发布流程,但包如何构建,最好应该由项目元数据和标准构建入口描述清楚。否则下游用户想自己构建时,就需要去翻 GitHub Actions,然后从里面拼出一套可执行步骤。
很多团队做到这里会卡住:内部流程越跑越熟,外部可复现性却越来越差。工具链本身没坏,是边界划错了。
二、下游构建暴露了真实问题
这次迁移的直接触发点,是社区伙伴 @vshawrh 提的两个问题:#667 和 #685。
它们暴露出一个长期被掩盖的缺陷:当前模式主要服务于 RapidOCR 官方发布流程,并没有充分考虑下游用户自行构建 whl 包。
对于下游用户来说,他们关心的不是“官方 CI 是怎么发布的”,而是:
git clone ...
cd ...
python -m build --wheel
这类标准动作能不能工作。
如果不行,就会产生几个现实问题。
第一,构建步骤不可发现。
用户需要知道 CI 里传了什么参数、进入了哪个目录、构建前是否需要准备模型资源、是否要移动产物。这些都不是 Python 打包系统天然能表达的信息,而是散落在脚本和 CI 配置中的约定。
第二,setup.py 逻辑越来越厚。
setup.py 最早只是构建入口,但在很多老项目里,它会慢慢承担越来越多职责,比如:
- 动态计算版本号
- 修改导入路径
- 读取依赖文件
- 注入额外资源
- 处理不同构建场景
- 兼容本地构建和 CI 构建
写到最后,setup.py 就变成了一个“构建控制器”。它能用,但调试成本高,也不利于标准化。
第三,项目结构为了打包反过来妥协。
RapidOCR 之前还遇到过需要将 rapidocr 目录包裹一层,才能正确导入的问题。这类问题很典型:代码组织本应服务于工程结构和开发体验,但如果打包逻辑处理不好,就会反过来要求目录结构让步。
这种让步短期能解决问题,长期会让项目越来越别扭。
三、pyproject.toml 的价值在于边界清晰
迁移到 pyproject.toml,并不只是换一个配置文件。它的核心价值是把构建系统、项目元数据、包发现规则、动态版本策略这些内容,用标准方式写清楚。
RapidOCR 迁移后的核心配置如下:
[build-system]
requires = [
"setuptools>=77",
"wheel",
"setuptools-scm>=8",
]
build-backend = "setuptools.build_meta"
[project]
name = "rapidocr"
dynamic = ["version", "dependencies"]
description = "Awesome OCR Library"
readme = { file = "README.md", content-type = "text/markdown" }
requires-python = ">=3.8"
license = "Apache-2.0"
authors = [
{ name = "SWHL", email = "liekkaskono@163.com" },
]
keywords = [
"ocr",
"text_detection",
"text_recognition",
"db",
"onnxruntime",
"paddleocr",
"openvino",
"rapidocr",
]
classifiers = [
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
]
[project.urls]
Documentation = "https://rapidai.github.io/RapidOCRDocs"
Changelog = "https://github.com/RapidAI/RapidOCR/releases"
[project.scripts]
rapidocr = "rapidocr.main:main"
[tool.setuptools]
include-package-data = true
platforms = ["Any"]
[tool.setuptools.dynamic]
dependencies = { file = ["requirements.txt"] }
[tool.setuptools.packages.find]
where = ["."]
include = ["rapidocr*"]
exclude = ["tests*"]
namespaces = false
[tool.setuptools.package-data]
rapidocr = [
"**/*.yaml",
]
[tool.setuptools_scm]
root = ".."
tag_regex = "^v?(?P.*)$"
version_file = "rapidocr/_version.py"
local_scheme = "no-local-version"
这段配置里,有几个关键点值得看。
四、版本号交给 setuptools-scm
RapidOCR 之前最核心的需求是自动化版本号。迁移后,这个问题由 setuptools-scm 解决。
它的思路很直接:从 Git 元数据中推导版本号。常见情况下,tag 就是版本来源。
[tool.setuptools_scm]
root = ".."
tag_regex = "^v?(?P.*)$"
version_file = "rapidocr/_version.py"
local_scheme = "no-local-version"
这里有几个细节。
root = ".." 表示 Git 仓库根目录在当前 Python 包目录的上一级。这适合类似 RapidOCR 这种仓库结构:项目根目录下有 python 子目录,而 Python 包在子目录内。
tag_regex = "^v?(?P.*)$" 用来兼容 v3.1.0 和 3.1.0 这类 tag 格式。很多项目喜欢在 tag 前加 v,但 Python 包版本号通常不需要这个前缀。
version_file = "rapidocr/_version.py" 会把推导出的版本写入包内文件。这样运行时也可以稳定读取版本,不必每次都依赖 Git 环境。
local_scheme = "no-local-version" 则会避免构建出带本地版本后缀的包名。对于正式发布到 PyPI 的包来说,这通常更干净。
这个方案的工程收益很明确:版本号规则回到项目配置里,而不是散落在 CI 参数和 setup.py 逻辑中。
当然,它也有边界。setuptools-scm 依赖 Git 元数据。如果用户拿到的是不包含 .git 信息的源码快照,就需要额外指定版本号。RapidOCR 在自定义构建文档里通过环境变量处理了这个问题:
SETUPTOOLS_SCM_PRETEND_VERSION_FOR_RAPIDOCR=3.1.0 python -m build --wheel
这就是一个合理的 trade-off:正常开发和发布场景使用 Git tag 自动推导版本;脱离 Git 环境的构建场景,允许用户显式注入版本号。规则统一,入口也清楚。
五、把资源准备从打包逻辑里拆出去
RapidOCR 这类 OCR 项目和普通纯 Python 工具库不太一样,它可能涉及模型文件、配置文件等打包资源。
如果把这些资源准备逻辑塞进 setup.py,会出现一个很麻烦的问题:构建包这一步会变得不可预测。
理想的构建动作应该尽量纯粹:
python -m build --wheel
它负责把当前目录下已经准备好的内容打成包,而不是顺手下载模型、改目录、生成资源、调整环境。
RapidOCR 迁移后,把下载打包必需模型这一步分离出来:
python tools/prepare_wheel_assets.py
然后再执行构建:
python -m build --wheel
这个拆分很重要。
构建前准备资源和构建 whl 是两个不同阶段。前者可能依赖网络、缓存、模型版本、外部资源;后者应该尽量依赖本地文件系统和标准构建工具。
把它们混在一起,短期看命令少一步,长期看会增加不确定性。尤其是 CI、离线环境、内网镜像、自定义模型构建这些场景,资源准备阶段越透明,越容易定位问题。
RapidOCR 的资源声明也回到了 pyproject.toml:
[tool.setuptools.package-data]
rapidocr = [
"**/*.yaml",
]
这里明确告诉打包系统:rapidocr 包内的 YAML 文件需要被包含进去。
资源文件打包一直是 Python 项目里容易踩坑的点。代码能 import,不代表配置文件能随包分发;本地能跑,也不代表安装后的 site-packages 里文件还在。把 package data 显式写出来,比靠目录习惯和隐式包含稳得多。
六、依赖和入口也应该标准化
迁移后的配置里,依赖使用动态读取:
[project]
dynamic = ["version", "dependencies"]
[tool.setuptools.dynamic]
dependencies = { file = ["requirements.txt"] }
这说明依赖仍然维护在 requirements.txt 中,但由 setuptools 在构建时读取并注入项目元数据。
这是一种折中方案。
更彻底的做法是把依赖直接写进 pyproject.toml 的 [project.dependencies],这样元数据更集中。但如果项目历史上已经围绕 requirements.txt 建立了开发、测试、CI 流程,直接迁移可能会带来额外改动。
这里选择动态读取,属于比较现实的工程取舍:先把构建入口标准化,降低迁移风险,再视情况逐步收敛依赖管理。
命令行入口也通过标准字段声明:
[project.scripts]
rapidocr = "rapidocr.main:main"
这比在 setup.py 里写 entry_points 更直观,也更符合现代 Python 打包规范。用户安装后可以直接使用:
rapidocr
工具入口、包元数据、资源规则都在一个配置文件里,维护成本会明显低一些。
七、下游构建流程变简单了
迁移后,下游用户自行构建指定版本 RapidOCR whl 包,大致只需要几步:
git clone https://github.com/RapidAI/RapidOCR.git
cd RapidOCR/python
python -m pip install --upgrade pip
python -m pip install build setuptools wheel setuptools-scm PyYAML
python tools/prepare_wheel_assets.py
SETUPTOOLS_SCM_PRETEND_VERSION_FOR_RAPIDOCR=3.1.0 python -m build --wheel
这个流程比之前更接近标准 Python 项目的构建体验。
可以把变化简单对比一下:
| 维度 | setup.py 模式 | pyproject.toml 模式 |
|---|---|---|
| 版本号 | 依赖 CI 传参或自定义逻辑 | setuptools-scm 从 tag/Git 元数据推导 |
| 构建入口 | python setup.py bdist_wheel |
python -m build --wheel |
| 元数据 | 分散在脚本逻辑中 | 集中在 pyproject.toml |
| 资源准备 | 容易耦合进打包过程 | 独立脚本显式执行 |
| 下游构建 | 需要参考 CI 细节 | 文档化标准步骤 |
| 可维护性 | 随项目增长变复杂 | 边界更清晰 |
这里并不是说 setup.py 一无是处。很多老项目继续使用它也没问题,尤其是内部项目或构建逻辑简单的库。
但对于 RapidOCR 这种有下游用户、有模型资源、有多平台构建需求的开源项目,继续让 setup.py 承担过多职责,后续只会越来越重。迁移到 pyproject.toml 的收益不在“新”,而在“把复杂度放到正确的位置”。
八、标准化不是为了好看
Python 打包生态这些年一直在往 PEP 517、PEP 518、PEP 621 这套方向收敛。pyproject.toml 成了越来越多工具的共同入口。
这背后的逻辑并不复杂:构建系统需要一个标准协议,项目元数据需要一个可被工具读取的声明位置,构建前端和构建后端需要解耦。
用 RapidOCR 的场景来说:
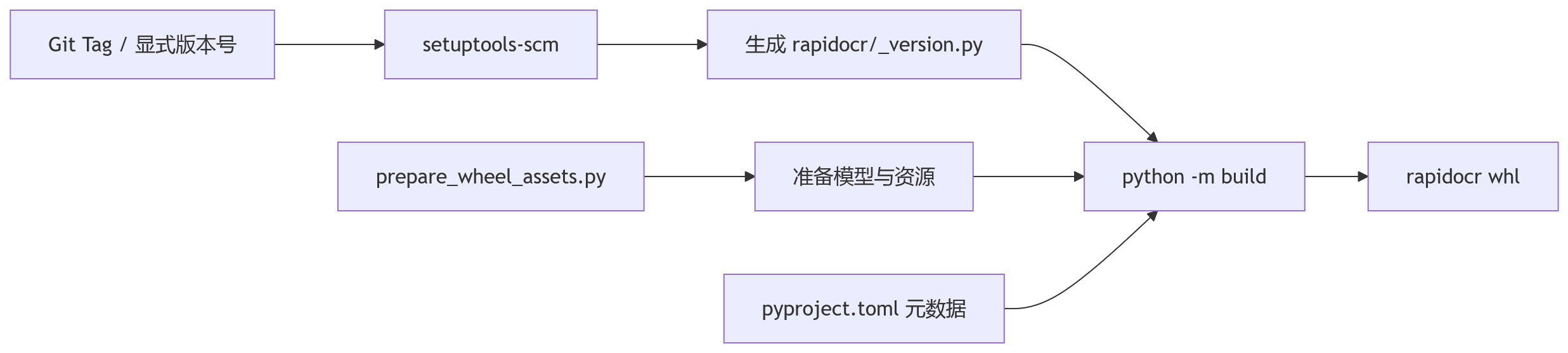
这条链路比之前清楚很多。
版本号怎么来,资源怎么准备,包怎么发现,哪些文件要带进去,命令行入口在哪里,都能找到明确位置。出了问题也更容易定位:
- 版本号不对,看
setuptools-scm - 资源缺失,看
package-data和资源准备脚本 - 包没被包含,看
packages.find - 依赖没写入,看
tool.setuptools.dynamic - 构建失败,看 PEP 517 构建入口和 build backend
真正到生产环境和下游分发场景里,麻烦往往不在“能不能打出一个包”,而在“别人能不能按文档稳定打出同样的包”。
九、这次迁移的工程启发
RapidOCR 这次从 setup.py 迁移到 pyproject.toml,解决了几个具体问题:
- 用
setuptools-scm替代自定义版本号传递逻辑 - 将构建元数据集中到标准配置文件
- 分离模型资源准备和 whl 构建
- 简化包发现与导入结构
- 降低下游用户自行构建成本
- 让构建流程更容易文档化和复现
如果抽象一点看,这次迁移的重点不是工具升级,而是构建边界重划。
setup.py 时代很容易把一切都写成 Python 逻辑。它灵活,也正因为太灵活,项目复杂后会变成维护负担。pyproject.toml 的约束更多,但这些约束会迫使项目把元数据、构建系统、资源准备、发布流程拆开。
工程上很多改进都是这样。一开始看只是换了个配置文件,真正省下来的,是未来每一次发布、每一次下游构建、每一次问题定位的时间。
问题出现并不总是坏事。它提醒维护者:原来那个“我已经习惯了”的流程,对别人来说可能并不友好。能借这个机会把隐性规则显性化,把个人经验沉淀成标准流程,项目就会往前走一小步。[DONE]