最近 AI 编程圈里有个说法传得很快:不要再只给 coding agent 写提示词了,要开始设计那些替你提示 Agent 的循环。
这句话听起来有点玄,甚至像又一个被包装出来的新概念。但如果把外面的噪声拿掉,它背后其实是一个很朴素的工程变化:过去我们把模型当成一次性助手,现在开始把模型放进一个持续运行的系统里,让它执行、检查、修正、再执行。
这件事真正值得关注的地方,不在于提示词工程是否过时,也不在于哪个 Agent 又多强了几个百分点。更关键的是,AI 编程正在从“人与模型的对话”变成“系统调度模型工作”。这会改变开发流程,也会改变我们判断成本、风险和工程责任的方式。
一、Loop 解决的是人工轮询问题
很多人第一次用 coding agent,流程大概都差不多。
给它一个任务,让它改代码。 它生成一批 diff。 你跑测试,发现挂了。 把错误贴回去。 它再改一轮。 你继续跑测试。
这个过程本身没有问题,甚至很符合今天大多数 Agent 的能力边界。麻烦在于,人被夹在循环中间,承担了大量机械动作:复制错误、判断是否继续、提醒它不要跑偏、在合适的时候停下来。
Agent Loop 做的事情,就是把这部分机械循环写成程序。
一个最小的 loop 通常包含四件事:
- 给 coding agent 下发任务;
- 读取 Agent 的输出;
- 判断任务是否完成;
- 如果没完成,把错误、约束或下一步反馈回去。
换成工程语言,它更像一个控制器,而模型只是控制器调用的一个执行单元。
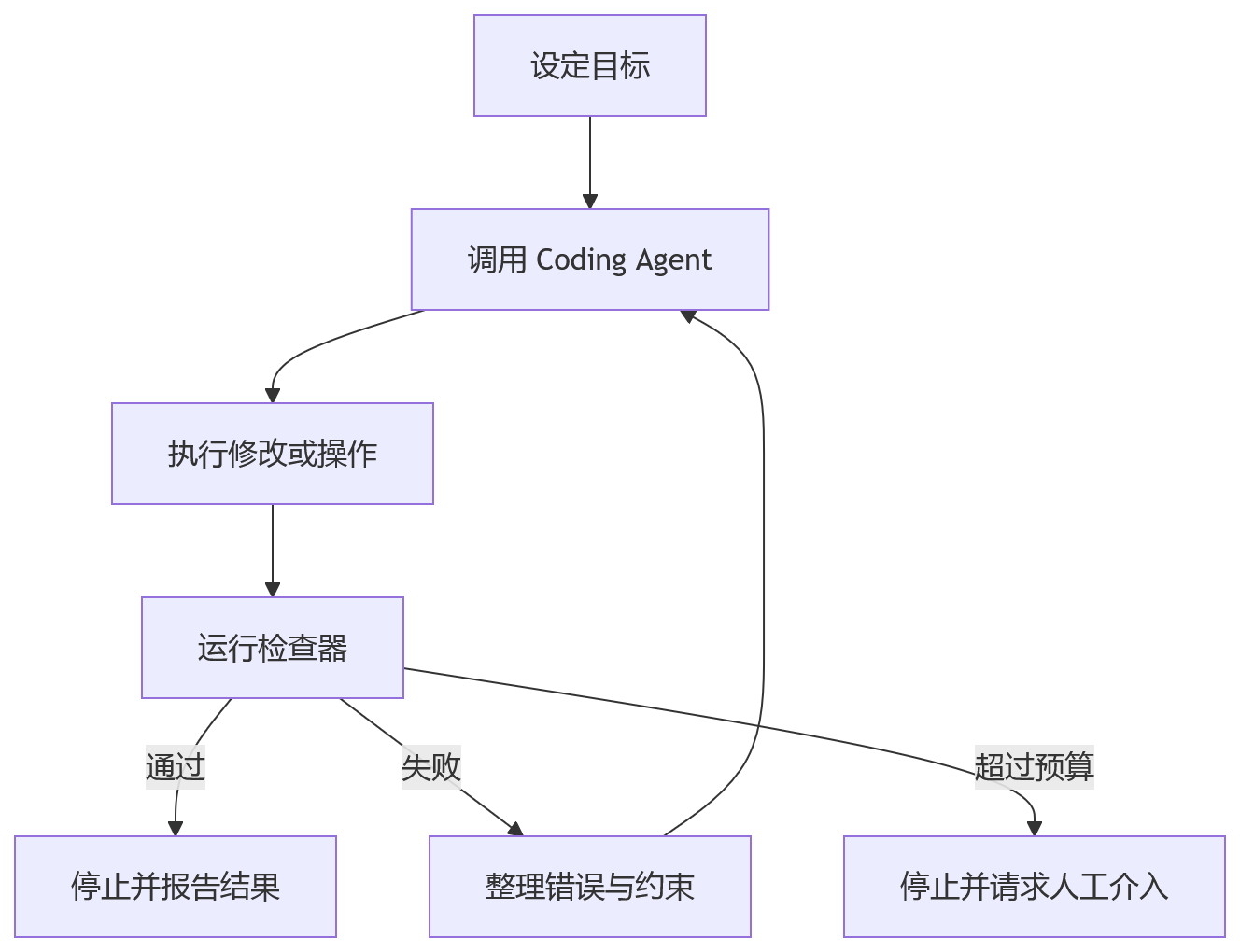
这里有个很重要的层级变化。
过去你优化的是单次提示词:怎么描述需求、怎么提供上下文、怎么让模型少犯错。 现在你优化的是循环系统:什么时候触发、怎么隔离、怎么验证、什么时候停止、失败以后怎么处理。
这不是提示词工程消失了,而是提示词变成了 loop 里的一个组件。
二、Loop 这个词被用得太宽了
现在很多争论都来自一个问题:大家都在说 loop,但说的并不是同一件事。
从过去几年的演进看,至少有几类含义混在一起。
| 类型 | 核心机制 | 典型问题 |
|---|---|---|
| ReAct | 推理、行动、观察、重复 | 适合工具调用,但需要明确观察结果 |
| AutoGPT 式循环 | 模型自我提示并持续推进目标 | 容易失控,不知道何时停止 |
| 上下文重置循环 | 每轮之间主动整理或压缩上下文 | 降低上下文污染,但会丢细节 |
/goal |
围绕可验证目标持续执行 | 依赖目标是否足够可检查 |
/loop |
按节奏重复执行某类任务 | 适合长期巡检,但需要预算控制 |
| orchestration | 一个调度器扇出多个 Agent | 能力强,风险和治理复杂度也高 |
ReAct 更像 Agent 行为模式。
AutoGPT 代表早期“让模型自己干到底”的尝试。
/goal 和 /loop 则更接近今天工程里可落地的形态。
orchestration 往前走一步,开始把多个 Agent、队列、沙箱、人工审核门组合起来。
如果不区分这些层次,很容易把所有东西都叫 Agent Loop,然后得出一些过于粗糙的结论:要么觉得它无所不能,要么觉得它只是旧瓶装新酒。两种判断都太省事了。
真正有价值的 loop,一定不是“让模型一直跑”。它至少要回答三个问题:
- 它为什么会被触发?
- 它怎么知道自己做完了?
- 它什么时候必须停下来?
第三个问题尤其关键。很多自动化系统的事故,不是因为它不够聪明,而是因为它太勤快。
三、一个可用 Loop 的六个部件
真正构建一个生产可用的 Agent Loop,靠一句提示词肯定不够。它更像一套小型流水线,里面至少有六个组件。
触发器
触发器决定 loop 什么时候开始运行。
它可以是:
- 定时任务;
- webhook;
- 文件变更;
- GitHub PR 标签;
- CI 失败事件;
- 工单状态变化。
这也是 loop 和“手动多跑几次 Agent”的分界线。只要还需要你坐在那里点开始,它就只是半自动。
隔离环境
只要你开始同时运行多个 Agent,隔离就不是可选项。
最常见的做法是给每个 Agent 一个独立 checkout,比如 git worktree。否则多个 Agent 同时修改同一个工作目录,很快就会互相覆盖、互相污染,最后你也分不清哪一轮改动造成了问题。
这个问题在 demo 里不明显,在生产环境里很快会冒出来。
写下来的上下文
项目约定、构建命令、目录边界、代码风格、测试方式,都应该放在 Agent 每次运行都能读取的位置。
比如:
AGENTS.mdCLAUDE.md.cursor/rules- repo 内部的工程说明文档
- 针对某个目录的局部规则
如果这些东西只存在于一次对话上下文里,loop 下次运行时就会重新猜。模型最擅长补空白,但工程系统最怕它乱补空白。
工具接入
一个 loop 如果只能输出一段修复建议,价值会大打折扣。
它至少应该能接入这些系统中的一部分:
- GitHub / GitLab;
- CI;
- issue tracker;
- 部署系统;
- 日志或监控系统;
- Slack / 飞书 / 企业微信;
- 数据库或只读分析接口。
这背后的原因很简单:真实工作不是“写完代码”就结束,而是要关联工单、跑测试、开 PR、等待检查、通知相关人。
独立验证器
生成代码的 Agent 和检查代码的 Agent,最好分开。
让模型审查自己的工作,问题不在于它一定会撒谎,而在于它很容易沿着自己刚才的推理路径继续自洽。很多时候它并没有发现错误,只是把错误解释得更像正确。
更稳妥的做法是把角色拆开:

Planner 负责拆任务,Executor 负责改代码,Evaluator 负责判断结果。 这几个角色不一定要用同一个模型。规划可以用强模型,执行可以用成本更低的模型,视觉检查可以用更擅长截图理解的模型。
这已经是架构决策了,不再是“押注哪个 coding agent 最强”。
磁盘上的状态
状态不能只放在对话里。
一个长期运行的 loop,需要知道:
- 哪些任务已经处理;
- 哪些任务失败过;
- 每个任务尝试了几次;
- 当前卡在哪一步;
- 下一轮应该从哪里继续。
这些状态可以放在 Markdown 文件、数据库、队列、看板卡片里。形式不重要,关键是它必须存在于模型上下文之外。
模型会忘,文件不会。
四、PR Babysitter 是个好起点
如果要找一个足够具体、又不会太危险的 loop,PR babysitter 很合适。
它的目标不是替你设计系统,也不是自动完成复杂需求,而是照看那些已经进入流程的 PR。
一个可落地的版本可以这样设计:
| 项目 | 设计 |
|---|---|
| 触发器 | 每 15 分钟运行一次 |
| 处理范围 | 只处理带 agent-watch 标签的开放 PR |
| 动作 | CI 确定性失败时尝试修复;主分支移动时尝试 rebase |
| 预算 | 每个 PR 最多修复一次,最多运行 5 分钟,最多修改 10 个文件 |
| 停止条件 | CI 变绿,或者预算耗尽 |
| 人工介入 | 失败后评论说明原因,并移交给维护者 |
这里的重点不是“让 Agent 无限努力把 PR 修好”。恰恰相反,关键是限制它的努力范围。
一个比较合理的执行流程大概是这样:
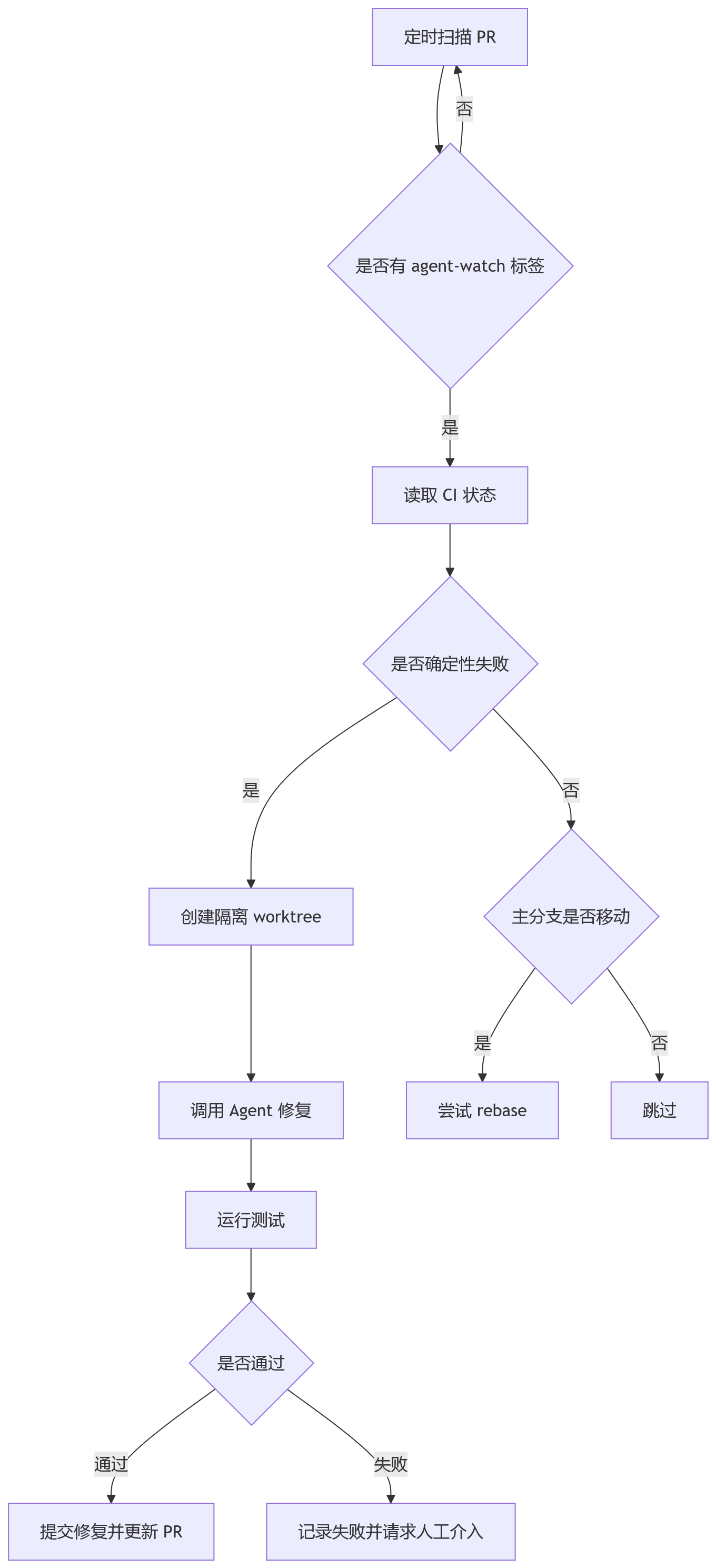
这里有一个非常现实的 trade-off。
如果范围放得太窄,它只能处理一些低价值的小故障,比如格式化、锁文件冲突、测试快照更新。 如果范围放得太宽,它可能会修改业务逻辑,甚至把一个 CI 失败修成另一个更隐蔽的问题。
所以我更倾向于让这类 loop 从“低风险维护任务”开始,而不是一上来就让它改核心业务代码。比如:
- flaky test 初步归类;
- 依赖锁文件更新;
- rebase 冲突中的机械部分;
- lint 或格式化失败;
- 测试快照更新,但必须有人工审核门。
这类任务的共同点是:验证信号比较明确,失败代价可控,人工 review 成本也不高。
五、/goal 更像合同,不像提示词
在一些 Agent 工具里,loop 已经不需要完全自己写。比如 Claude Code 的 /goal,本质上就是一个内置的目标循环。
一个简单例子:
claude
/goal tests in test/auth pass
这个目标看起来很短,但它背后隐含了一套 act-check-repeat 机制:
- Agent 修改代码;
- 运行相关测试;
- 评估目标是否达成;
- 没达成就继续下一轮;
- 达成或触发停止条件后结束。
一个好的 /goal,更像一份工程合同。它应该写清楚四件事:
- 最终状态是什么;
- 用什么证据证明完成;
- 过程中不能破坏哪些约束;
- 允许消耗多少预算。
比如下面这个目标就比“fix auth tests”更可控:
/goal test/auth passes, npm test exits 0 for auth-related tests,
only modify files under src/auth and test/auth,
stop after 8 turns or if more than 6 files need changes
这里的差别很大。
“fix auth tests”会给模型留下太多自由空间。它可能跳过测试、改掉断言、扩大修改范围,甚至把问题绕过去。 而后者明确了通过条件、修改边界和停止预算,loop 更容易收敛,也更容易被人 review。
可度量的目标通常长这样:
npm test exits 0all tests in test/auth passbuild succeedsqueue length is 0no file exceeds 500 linesendpoint /health returns 200
不适合作为目标的表达也很常见:
- 让代码更优雅;
- 改善用户体验;
- 找出增长问题;
- 优化架构;
- 让这个模块更合理。
这些目标不是不能做,而是不适合直接交给 loop。它们缺少便宜、明确、可自动执行的验证器。
六、多个 Agent 运行时,风险会放大
一个 Agent 朝着一个目标工作,风险还算可控。多个 Agent 无人值守运行,问题会快很多。
常见的无人值守配置大概包含几步:
claude --permission-mode auto
# 自动批准工具调用,避免每一步都停下来
# 通过 orchestrator 扇出多个 sub-agent
# 让不同 Agent 处理不同子任务
/goal all tests pass and demo loads clean
# 设置可验证完成条件
# 在云端或远程环境运行
# 笔记本合上后任务仍然继续
# 接入浏览器、模拟器或 live server
# 做端到端验证
自动批准权限这一步尤其敏感。
它能提高效率,也会放大错误。没有权限边界、没有沙箱、没有预算限制的 auto mode,本质上是在给一个不稳定的自动化流程开绿灯。
工程上更稳的做法是分层授权:
| 权限类型 | 建议策略 |
|---|---|
| 读取代码 | 默认允许 |
| 修改工作区文件 | 在隔离 worktree 内允许 |
| 运行测试 | 允许,但限制时间 |
| 安装依赖 | 谨慎允许,记录变更 |
| 写数据库 | 默认禁止,除非是临时环境 |
| 部署生产 | 禁止自动执行 |
| 合并 PR | 需要人工审核或强验证门 |
这里的取舍很明显。
你给 Agent 的权限越大,自动化收益越高;但错误半径也越大。生产环境里不能只看它能不能完成任务,还要看它失败时会破坏什么。
很多团队做到这里会卡住,因为 demo 阶段只需要展示“它能跑”,生产阶段必须回答“它跑歪了怎么办”。后者才是真正的工程问题。
七、Orchestration 正在产品化
手写 loop 只是第一阶段。更进一步的趋势,是把 loop 变成基础设施。
比如一些工具开始提供类似“agent runs 任务控制中心”的能力:
- 任务以卡片形式存在;
- 卡片可以来自 prompt、GitHub issue 或 PR;
- 状态在 todo、running、human review、done 之间流转;
- 每次运行都有 attempt 和 heartbeat;
- Agent 可以启动子 Agent;
- 每个 Agent 运行在一次性云端沙箱;
- 人类只在 handoff 或审核门处接管。
这其实就是把前面讲的几个部件产品化了:

从工程视角看,这比单个 Agent 更值得关注。
因为一旦进入 orchestration 层,团队管理的对象就变了:
- 不再只是管理代码;
- 也不只是管理模型;
- 而是管理一批可调度、可暂停、可追踪、可审核的自动化执行单元。
这和早年 CI/CD 的演进很像。最开始大家写脚本,后来变成流水线,再后来变成平台能力。Agent Loop 大概率也会走类似路径。
八、成本不再只看 Token
过去讨论 AI 编程成本,大家很容易盯着两个数字:
- 模型单价;
- token 消耗。
在 loop 里,这个视角不够用了。
真正的成本单位变成了:一个任务完成需要 loop 转几圈。
同一个任务,如果强模型一轮完成,弱模型转六轮才完成,后者未必便宜。更糟的是,六轮中每一轮都可能产生 diff、跑测试、占用 CI、触发 review,真实成本远超 token。
可以粗略把成本拆成这样:
任务成本 ≈ 单轮模型成本 × 迭代次数
工具调用成本
CI/沙箱成本
人工审核成本
错误回滚成本
所以优化 loop 时,优先级通常不是“换个更便宜的模型”,而是:
- 收紧目标;
- 提升验证器质量;
- 减少无效重试;
- 尽早失败;
- 控制修改范围。
弱验证器是最贵的 bug。
如果验证器太松,坏结果会被放行。 如果验证器太严或信号不稳定,已经正确的结果会被反复重试。 两种情况都会浪费完整迭代成本。
一个没有连续失败上限的 loop,并不会因为足够努力就最终成功。它更可能只是把预算烧完,然后留下一个更难 review 的工作区。
九、什么时候别用 Loop
Loop 适合三类任务:
- 重复发生;
- 验证便宜;
- 完成条件清楚。
离开这三个条件,loop 很容易变成自动化空转。
一次性修改
如果一轮对话就能完成,引入 loop 反而增加复杂度。
比如改一个文案、补一个简单类型错误、更新一处配置。让 Agent 改完,你看一眼,可能比搭一个循环更便宜。
开放式探索
“分析用户为什么流失”这种任务没有明确通过条件。
它需要数据分析、业务判断、访谈、假设验证。Agent 可以辅助整理材料,但不适合被放进自动循环里无限推进。
没有自动检查机制
如果唯一验证方式还是人眼,那人其实仍然在 loop 里。
这时候更合理的路径是先补检查机制,比如测试、静态扫描、截图对比、接口探测、日志规则。没有检查器就直接上 loop,等于把人工判断延后,并没有消除它。
高风险生产操作
涉及生产数据修改、线上部署、权限变更、账务逻辑等任务,不能因为 Agent 看起来能做就直接自动化。
这些场景不是完全不能用 Agent,而是需要更硬的边界:
- 只读优先;
- 临时环境验证;
- 强制人工审批;
- 完整审计日志;
- 可回滚方案;
- 最小权限执行。
十、真正的问题是责任边界
一个能在你睡觉时运行的 loop,也会在你睡觉时犯错。
这句话不算好听,但很实在。
Agent Loop 常见的失败模式有三类。
第一类是验证负担回到人身上。
Loop 写代码的速度可能远超你 review 的速度。如果你停止读 diff,只看“测试通过”,那并不是消除了审核工作,只是把风险推迟到以后。
第二类是系统理解被稀释。
你没有亲手写代码,却以更快的速度合并代码。短期看产能很高,长期看团队对系统的理解可能跟不上变化。下一次线上故障时,这笔债会变得很具体。
第三类是静默漂移。
弱验证器会让“错误但能通过”的改动一点点进入系统。每次都不大,每次都能过,最后系统行为偏离设计意图。这个问题比红灯失败更麻烦,因为它不会及时提醒你。
所以 Agent Loop 并不是让工程师变得不重要。相反,它把工程师的工作往上推了一层:从亲手执行每个动作,变成设计一个可靠的执行系统,并持续为输出负责。
十一、从一个小 Loop 开始
如果你想真正尝试,不建议一开始就做多 Agent orchestration。那很容易把问题复杂度拉满。
更务实的路径是选一个低风险、可验证、重复发生的任务。
比如:
- 看护指定标签的 PR;
- 自动修复 lint 失败;
- 归类 CI 失败原因;
- 检查部署后的健康接口;
- 定期聚类用户反馈;
- 清理过期 feature branch;
- 维护文档中的 broken links。
一个初始版本可以按这个清单设计:
| 设计项 | 要回答的问题 |
|---|---|
| 任务范围 | 它只处理哪些文件、PR、issue 或目录 |
| 触发方式 | 定时、事件触发,还是手动启动 |
| 验证器 | 什么信号代表完成 |
| 预算 | 最多几轮、几分钟、几个文件、多少钱 |
| 隔离 | 在哪里运行,是否使用 worktree 或沙箱 |
| 状态 | 运行记录放在哪里 |
| 审核门 | 哪些结果必须人看 |
| 失败处理 | 失败后评论、告警,还是进入队列 |
一个比较克制的目标可能长这样:
每 30 分钟扫描带 agent-watch 标签的 PR。
如果 CI 因 lint 或格式化失败变红,创建独立 worktree 尝试修复。
只允许修改格式化相关文件。
最多运行 2 轮,最多修改 5 个文件。
修复后重新跑对应检查。
通过则提交到 PR,失败则评论原因并移除 agent-watch 标签。
这类 loop 不性感,但容易上线,也容易建立信任。很多自动化系统的成熟度,都是从这种小而硬的任务里长出来的。
最后值得记住的是:现在真正昂贵、真正容易出错的部分,正在从“模型调用”转移到“循环设计”。
提示词依然重要,但它只是局部。更大的问题是,你能不能设计一个有边界、有验证、有预算、有状态、能停下来的系统。
如果做不到,Agent Loop 只是在自动化制造不确定性。 如果做得到,它会成为 AI 编程从玩具走向工程能力的关键一步。