-

行业资讯
INDUSTRY INFORMATION
对科技企业而言,绩效数据分散并不只是HR多做几张表的问题,而是绩效管理能否支撑人才决策、薪酬激励和组织调整的基础问题。本文面向HRD、CHRO、组织发展负责人和数字化管理者,围绕“为何先治数据”展开,分析科技企业绩效数据孤岛的结构性成因,并提出以eHR系统为中枢的数据治理路径。
一家快速扩张的科技企业进入年终人才盘点季。HRD打开会议材料时发现,员工目标完成情况在OKR工具里,项目贡献记录在项目管理系统里,代码提交与研发协同数据在工程平台里,360评估结果来自另一个问卷系统,主管补充意见则散落在Excel表单和邮件附件中。看似所有数据都存在,但当管理层要求回答一个简单问题——哪些人持续高绩效、哪些人适合晋升、哪些团队目标达成质量更高——HR团队却很难给出一张口径一致、逻辑完整、能经得起业务负责人追问的人才画像。
这不是个别企业的低效操作,而是许多科技企业绩效管理走向数据驱动时遇到的共同矛盾。公开研究与行业实践普遍提示,HR数据质量已经成为AI在人力资源场景落地的重要约束;德勤关于人力资本趋势的研究也持续强调,数据驱动型HR组织并不是多部署几个系统,而是要让数据能够被理解、被信任、被用于决策。
问题在于,很多企业的推进顺序恰好相反:先上OKR,后想数据标准;先做360评估,后处理评价口径;先引入AI分析,后发现训练和判断所依赖的底层数据并不可靠。绩效数据分散不是“不方便”的小问题,而是科技企业绩效管理从流程合规走向真实驱动的根本障碍。本文要回答的正是:绩效数据分散的科技企业,为何应先完善eHR系统的数据治理能力?
一、绩效数据分散:科技企业的隐性慢性病
科技企业绩效数据碎片化,往往不是因为HR不重视数据,而是组织运行方式天然制造了多源、多口径、多频率的数据环境。真正的风险不在于数据分散本身,而在于企业误以为只要流程跑完,绩效管理就已经完成。
1. 矩阵组织、项目制与多事业部并行,使绩效数据天然分布
科技企业常见的组织形态,是职能线、产品线、项目线同时运转。一名研发人员可能隶属于基础平台部门,却长期支持某条产品线;一名算法工程师可能在季度内参与多个项目,直接主管、项目负责人、产品负责人都掌握一部分评价信息。绩效贡献并不总是沿着行政组织边界发生,数据也就不可能天然集中在单一流程中。
在这种结构下,OKR工具记录目标与关键结果,项目管理系统记录交付节点与任务完成,代码仓库记录研发活动,360评估平台记录协作反馈,考勤或工时系统记录投入情况,Excel表单承载临时评价与主管补充说明。每个系统都在解决局部问题,但从企业整体看,它们共同形成了一个绩效数据拼图。
如果企业处在业务稳定、组织简单、绩效指标单一的阶段,这种分散可能只是增加一些整理成本;但在研发、产品、销售、交付多线协同的科技企业中,绩效数据一旦缺少统一治理,就会影响跨团队比较、人才盘点和资源配置。管理层看到的不是完整事实,而是被系统边界切碎后的片段。
2. 绩效数据分散的三类表现:口径、时效与归属
绩效数据分散最容易被低估,是因为它并不总以错误形式出现。很多时候,单个系统里的数据都是“正确”的,但放在一起就无法形成一致结论。科技企业常见的三类表现,分别是口径不一致、时效不同步和归属不清晰。
表格1:绩效数据分散的三大典型表现
| 典型表现 | 场景示例 | 管理后果 |
|---|---|---|
| 口径不一致 | OKR系统中的“目标完成率”按关键结果加权计算,项目系统中的“交付完成率”按里程碑关闭计算,主管评分又采用等级制 | 同一员工在不同系统中呈现出不同绩效结果,绩效校准难以形成共同讨论基础 |
| 时效不同步 | 季度OKR已更新,但年度绩效表仍沿用旧目标;项目评价按月更新,360反馈只在年末收集 | 绩效评估滞后于业务变化,人才盘点结论容易反映过去状态而非当前贡献 |
| 归属不清晰 | 跨部门项目中,员工贡献由项目负责人掌握,行政主管只看到部门目标;项目绩效与部门绩效之间缺少映射 | 关键贡献可能被低估,协作成本可能被忽视,最终影响晋升、奖金和岗位调整公平性 |
这三类问题背后的共同机制,是企业没有对绩效数据建立统一语义。所谓统一语义,不只是字段名称一致,而是要明确数据的来源、定义、计算方式、更新频率、责任人和适用场景。例如,同样是“绩效等级”,它究竟来自主管评分、校准后等级,还是最终应用于薪酬发放的确认等级?如果没有治理,系统越多,数据越难被解释。
3. 数据分散会把绩效管理拖回对账逻辑
绩效数据分散带来的直接后果,是绩效校准会议从管理讨论变成数据对账会。原本应该讨论人才贡献、岗位匹配、组织能力短板的会议,被迫花大量时间确认表格版本、指标口径和评分差异。业务负责人质疑数据来源,HR解释规则差异,管理层等待重新拉数。会议看似严谨,实则管理能量被消耗在基础数据一致性上。
人才盘点也会受到影响。九宫格、继任计划、高潜识别等工具都依赖较稳定的绩效与潜力数据。如果绩效数据本身无法被信任,盘点结论就容易回到主观印象。业务强势部门可能更善于表达贡献,后台支撑团队的价值则可能被低估;短期项目结果容易被看见,长期技术沉淀和组织协作贡献却难以呈现。
更深层的副作用,是HR团队角色被重新定义为数据搬运工。每到绩效周期,HR花大量时间从不同系统导出、清洗、合并、核对数据,却很难把精力投入到绩效机制优化、管理者赋能和组织诊断上。绩效数据分散表面上是IT便利性不足,实质上削弱了HR作为业务伙伴的专业价值。
二、为什么先治数据,而不是先上绩效工具
绩效管理升级不是工具竞赛。对绩效数据分散的科技企业而言,先完善eHR系统的数据治理能力,是先修路、再跑车的逻辑;如果道路规则、路况和信号系统都没有建立,车越快,风险越大。
1. 不先治数据,新工具可能输出更复杂的错误结论
许多企业在发现绩效管理低效后,第一反应是采购或升级工具:上线OKR系统、引入360评估平台、部署AI绩效分析模块。这些工具确实能提升局部流程效率,但前提是它们处理的数据具有基本一致性。如果底层数据标准混乱、历史数据缺失、评价口径不统一,新工具只是把原有问题包装成更精致的界面。
AI绩效分析尤其依赖这一前提。Garbage In, Garbage Out并不是技术圈口号,而是所有数据分析场景的基本约束。输入数据存在偏差,输出结论就会放大偏差;输入数据缺少上下文,模型就可能把短期活跃度误判为高绩效,把跨部门协作中的隐性贡献排除在外。对于员工绩效这类影响薪酬、晋升与发展机会的敏感场景,这种偏差不仅会降低决策质量,还可能损害组织信任。
不适合直接引入复杂工具的企业,通常有几个特征:绩效指标尚未统一定义;历史数据无法追溯;评估流程频繁变化;业务部门对数据责任没有共识。在这些条件下,先上工具容易形成新的数据孤岛。企业以为自己完成了数字化,实际只是把手工混乱迁移到系统混乱。
2. 数据治理先行的价值:标准、质量与资产
eHR系统的数据治理能力,首先体现在统一数据标准。绩效管理中的关键字段,如目标类型、指标权重、完成率、评分等级、校准状态、结果应用,都需要明确业务含义与技术口径。只有标准一致,不同系统中的数据才可以比较、聚合和追溯。否则,跨部门绩效校准就会陷入各说各话。
其次是数据质量监控。绩效数据不是录入一次就能长期使用的静态资料,它会随着目标调整、项目延期、组织变动和人员异动不断变化。数据治理要求企业建立完整性、准确性、一致性、及时性等质量规则。例如,关键岗位员工是否缺少目标记录,项目评价是否晚于绩效截止日,评分等级是否超出规则范围,主管与项目负责人评价是否存在明显逻辑冲突。通过eHR系统自动巡检,HR才能从事后补救转向过程管理。
第三是形成数据资产目录。绩效数据一旦被治理,就不再只是绩效周期的临时材料,而可以服务人才发展、薪酬激励、组织分析、继任管理和AI辅助决策。资产化的关键不是把数据存起来,而是让数据可检索、可理解、可复用、可授权使用。对于科技企业,这一点尤其重要,因为组织变化快、项目更迭快,历史绩效信息如果无法沉淀,就很难支持长期人才判断。
3. 有数据治理与无数据治理的绩效管理效果对比
数据治理的价值,最容易通过对比看清。没有治理时,企业越努力推进绩效流程,越可能制造更多数据版本;有治理时,绩效管理的复杂度仍然存在,但复杂性被纳入可控框架。
表格2:有数据治理与无数据治理的绩效管理效果对比
| 对比维度 | 无数据治理 | 有数据治理 |
|---|---|---|
| 绩效校准效率 | 会议前反复拉数、核对版本,会议中频繁争论口径 | 数据来源、版本和口径清晰,校准讨论聚焦贡献与差异 |
| 人才盘点可信度 | 结论依赖主管印象,跨部门比较难以成立 | 绩效、潜力、项目贡献等数据可追溯,盘点依据更稳定 |
| AI分析可用性 | 输入数据噪声高,模型输出难解释、难采信 | 数据标准化程度较高,可支持趋势识别与风险提示 |
| HR角色定位 | HR大量承担导数、拼表、对账工作 | HR更多参与规则设计、组织诊断和管理者赋能 |
| 管理决策质量 | 绩效结果与薪酬、晋升、发展应用容易脱节 | 绩效结果可与人才、薪酬、组织数据形成闭环联动 |
需要注意的是,数据治理并不会自动解决所有绩效管理难题。企业仍然要面对目标设定质量、管理者评价能力、组织政治和激励公平等问题。但没有可信数据,这些问题很难被识别;有了可信数据,企业至少可以把争议从“数据准不准”推进到“规则是否合理、管理动作是否有效”。
三、eHR数据治理能力建设的四维框架:从散到治的落地路径
科技企业建设绩效数据治理能力,不应把eHR系统理解为单纯的数据仓库,而要把它作为连接业务系统、HR流程和管理决策的数据治理中枢。落地路径可以从数据收集、数据保鲜、数据质量监控、数据安全与资产化四个维度展开。
1. 数据收集:统一入口,消除孤岛
数据收集的目标,不是把所有系统简单替换为eHR系统,而是建立绩效数据的统一权威源。科技企业已有OKR工具、项目管理系统、研发协作平台和评估工具,完全推倒重来既不现实,也可能破坏业务效率。更可行的方式,是明确哪些数据在业务系统中产生,哪些数据进入eHR系统沉淀,哪些数据以eHR系统中的最终口径作为绩效管理依据。
这要求企业设计接口规范与流程规则。OKR数据可以按目标周期同步,项目绩效数据可以按项目节点或月度同步,360评估数据可以在评价周期结束后归档,考勤和工时数据则根据业务需要提供辅助判断。关键不在于同步频率越高越好,而在于每类数据都有明确责任人、更新规则和异常处理机制。
在管理上,HR需要与IT、业务负责人共同定义数据责任。项目负责人负责项目评价的真实性,行政主管负责绩效应用的完整性,HR负责规则口径和流程合规,IT负责接口稳定与权限控制。只有责任链条清楚,统一入口才不会变成另一个数据堆场。
2. 数据保鲜:动态更新,确保时效
绩效数据的价值具有时间属性。一个员工半年前的目标完成情况,对当前人才判断有参考意义,但不能直接替代最新项目贡献;一个项目阶段性延期,可能是执行问题,也可能是外部依赖变化。如果数据更新机制滞后,绩效管理就会用过期信息评价当前表现。
数据保鲜要求企业建立绩效数据生命周期。目标数据从创建、调整、确认到归档,应有状态标识;项目评价从阶段反馈、节点验收到最终复盘,应能记录时间和版本;年度绩效结果从初评、复评、校准到应用,也需要保留流转轨迹。eHR系统在这里承担的不只是存储职责,更是通过状态、时间戳和预警规则,提示哪些数据已经过期、缺失或需要确认。
不同企业的数据保鲜频率不应一刀切。研发节奏快、项目制明显的团队,可能需要更高频的目标与项目同步;业务稳定、岗位职责清晰的支持部门,则可以采用较低频率。过度追求实时化会增加管理成本,也可能制造无意义波动。较好的判据是:更新频率能否支撑管理动作。如果数据更新速度慢于绩效校准、人才盘点或薪酬决策的节奏,就需要调整。
3. 数据质量监控:标准先行,巡检兜底
数据质量不是靠年终集中清洗出来的,而是靠规则在过程中持续发挥作用。科技企业应先制定绩效数据标准,再通过eHR系统建立巡检机制。标准包括指标定义、计算口径、评分规则、等级映射、数据来源优先级、异常处理办法等。没有这些标准,所谓质量检查就缺少判断依据。
巡检可以从三个层面展开。第一是完整性检查,例如关键岗位是否缺少目标、是否存在未提交评价、是否有跨部门项目未归属到员工绩效记录。第二是一致性校验,例如同一员工在不同系统中的组织归属是否一致,评分等级与校准结果是否匹配,目标权重合计是否符合规则。第三是逻辑合理性审核,例如目标完成率异常高但项目延期严重,主管评分与多方反馈差异过大,绩效等级分布明显偏离既定校准规则。
将数据质量纳入HR团队可量化管理指标,也有必要。比如,绩效周期前的数据完整率、异常数据处理及时率、跨系统字段匹配准确率,都可以作为过程管理指标。但这类指标要服务于质量改进,而不能异化为新的形式主义。若业务部门为追求数据完整而机械填报,质量反而可能下降。
图表1:eHR数据治理四维框架闭环

4. 数据安全与资产化:安全合规,资产可用
绩效数据涉及员工评价、薪酬应用、晋升机会和潜力判断,天然具有敏感性。科技企业推进数据治理时,不能只强调数据可用,还要同步建立分级授权与脱敏机制。业务主管可以查看其管理范围内的绩效信息,HRBP可以基于授权开展组织分析,高管可以查看汇总视图,涉及个人隐私和薪酬敏感的信息则应受到更严格控制。
安全治理还包括操作留痕和数据使用边界。谁查看了绩效数据,谁导出了员工评价,哪些数据被用于AI分析,都应有记录。特别是在AI应用场景中,企业需要明确哪些数据可以进入模型,哪些数据只能用于人工决策辅助,哪些敏感字段必须脱敏或排除。技术能力越强,越需要边界清晰。
资产化则是数据治理的另一面。治理后的绩效数据可以进入企业数据资产目录,与人才发展、学习培训、岗位任职、薪酬激励、组织效能等模块形成关联。这样一来,企业不只是知道某个员工某年得了什么等级,还能观察其目标类型、项目贡献、能力成长、岗位变化和激励结果之间的关系。对科技企业而言,这种长期数据沉淀,是识别关键人才、优化组织配置和提升管理质量的重要基础。
四、从数据治理到绩效闭环:科技企业的进阶路径与关键里程碑
数据治理的目的不是让绩效数据看起来更整齐,而是让绩效管理全闭环能够被可信数据驱动。目标设定、过程跟踪、评估校准、结果应用和AI赋能,每一步都依赖数据口径、质量和安全边界。
1. 绩效目标阶段:让目标数据结构化、可追踪
绩效闭环从目标开始。科技企业常采用OKR、KPI或混合机制,但无论使用哪种方法,目标数据都需要结构化。所谓结构化,不只是把目标填进系统,而是明确目标类型、权重、责任人、协同关系、衡量方式和调整记录。否则,企业会出现“目标写得很完整,但无法衡量”的困境。
在eHR系统的数据治理框架下,目标应能追踪上下级对齐关系、跨团队依赖关系和目标变更过程。例如,某产品线的关键结果依赖基础平台能力交付,那么目标关联关系就不应只停留在文字描述,而应在系统中形成可追溯链接。这样,当绩效评估讨论目标达成情况时,管理者才能区分个人执行问题、跨团队协作问题和外部条件变化。
这里的边界也很重要。并非所有目标都适合过度量化。研发创新、技术预研、组织建设等目标,可能需要定性评价与阶段性证据共同支撑。数据治理的作用不是把一切压缩成数字,而是让定量数据、定性证据和评价过程有统一存放与解释规则。
2. 绩效评估与校准阶段:让比较建立在同一把尺上
绩效评估最容易产生争议的地方,是不同部门、不同岗位、不同主管之间的评价尺度不一致。销售团队强调业绩达成,研发团队强调交付质量与技术贡献,职能团队强调支持效率与风险控制。如果没有统一口径,绩效校准就会变成主观博弈。
数据治理可以为校准提供同一把尺。它通过统一评分规则、等级映射和数据来源优先级,减少系统之间的解释差异;通过保留项目贡献、目标完成、协作反馈和主管评价等多维证据,支持跨部门讨论。校准不再只是比较分数,而是比较分数背后的事实基础。

需要说明的是,数据不会替代管理判断。绩效校准仍然需要管理者讨论岗位难度、业务环境、组织贡献和未来潜力。数据治理的价值,是把讨论从印象和立场拉回到可验证依据上。若企业误以为系统评分可以自动决定绩效等级,反而会削弱管理者责任。
3. 绩效结果应用与AI赋能阶段:数据治理决定智能分析上限
绩效结果最终要应用于薪酬、晋升、人才发展、继任计划和组织调整。若数据链条清晰,绩效结果可以与岗位价值、薪酬策略、培训发展和员工流动数据联动,形成管理闭环;若数据链条混乱,绩效结果就容易停留在一次性评分,难以产生持续管理价值。
AI绩效分析的前提也在这里。高质量、标准化、可追溯的绩效数据,才可能支持趋势预测、高潜识别、离职风险预警和团队效能分析。反过来,如果绩效等级受主管宽严差异影响过大,项目贡献缺少结构化记录,历史数据缺失严重,AI模型就可能输出看似精确但难以解释的判断。
公开研究中关于数据治理成熟度与组织绩效关系的讨论,可以作为企业进一步验证的方向。更务实的做法,是先从内部可验证指标开始观察:绩效校准周期是否缩短,数据异常率是否下降,人才盘点争议是否减少,绩效结果与后续晋升、保留、发展结果之间是否更一致。智能化不是一个独立阶段,它建立在长期治理积累之上。
4. 关键里程碑规划:为何先治数据要分三步推进
对多数科技企业而言,数据治理不适合做成一次性大项目。组织仍在变化,系统仍在迭代,绩效规则也可能随业务周期调整。更稳妥的方式,是围绕下一个绩效周期设计三步走路线。
第一阶段,3至6个月内完成绩效数据标准制定与eHR数据收集统一。企业需要盘点绩效数据在哪里、字段是什么、口径差异有哪些、哪些系统是源头系统、哪些数据需要进入eHR系统。这个阶段的关键交付物不是一份漂亮方案,而是一套可执行的数据字典、接口清单和责任矩阵。
第二阶段,6至12个月建立数据质量监控与保鲜机制。重点是把完整性检查、一致性校验、异常预警和版本管理嵌入绩效流程。HR不应等到年终才发现数据缺失,而应在目标设定、过程反馈、评估提交和校准准备阶段持续检查。
第三阶段,12至18个月推进绩效数据资产化与AI分析赋能。企业可以在数据质量相对稳定后,尝试将绩效数据与人才、薪酬、组织数据关联,用于高潜识别、团队效能诊断和管理风险预警。此时再引入AI,才更可能获得可解释、可采信、可落地的分析结果。
图表2:科技企业绩效数据治理三步走里程碑
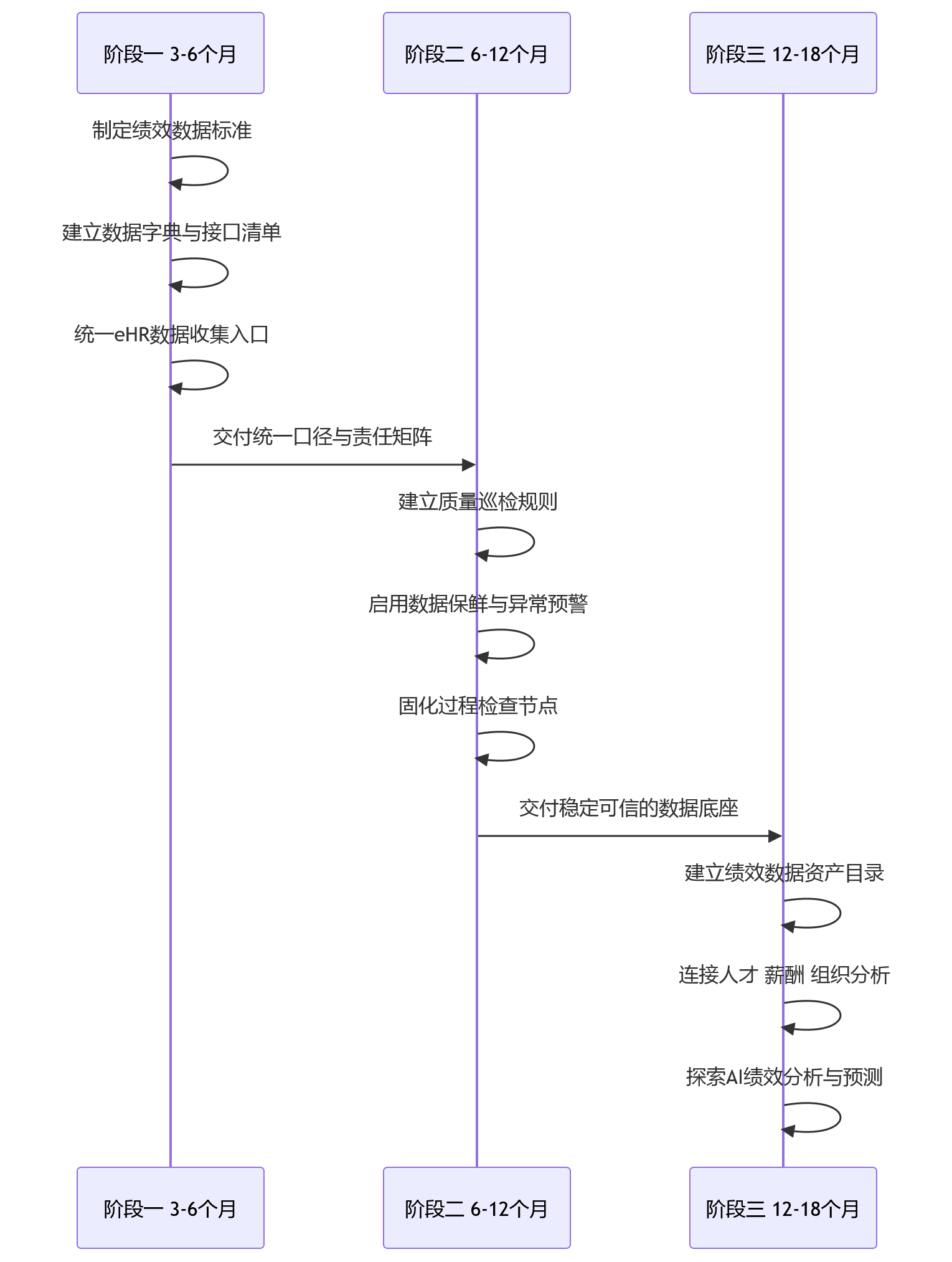
三步走的价值,在于把复杂治理拆成可管理节奏。企业不必等所有系统完美后才行动,也不能跳过标准和质量直接进入智能分析。数据治理的终点不是“数据整齐”,而是绩效闭环能够持续驱动组织决策。
红海云总结
回到开篇的场景,如果HRD在绩效校准会上不再反复解释数据为什么对不上,如果人才盘点结论能被业务负责人追溯和验证,如果绩效结果能够自然连接薪酬、晋升、发展与组织调整,绩效管理才真正从管理负担转为战略杠杆。对绩效数据分散的科技企业而言,2026年的优先事项不应只是采购更多绩效工具,而是先回答一个更基础的问题:我们的绩效数据,是否已经治理到可以被信任的程度?
结合红海云在人力资源数字化场景中的实践视角,科技企业可以从以下几项行动开始:
- 先做绩效数据健康度诊断:盘点数据在哪里、谁负责、口径是否一致、更新是否及时、哪些数据影响薪酬和晋升决策。
- 以eHR系统建立统一治理中枢:不是替代所有业务系统,而是明确绩效数据的权威口径、归集规则和应用边界。
- 把数据质量嵌入绩效周期:在目标设定、过程跟踪、评估提交、校准准备等节点设置检查规则,减少年终集中补救。
- 谨慎推进AI绩效分析:在数据标准、质量和安全机制没有成熟前,不宜把AI输出直接用于高影响决策。
- 让治理服务管理闭环:数据治理不是IT项目,而是绩效管理从经验驱动走向数据驱动的组织能力建设。