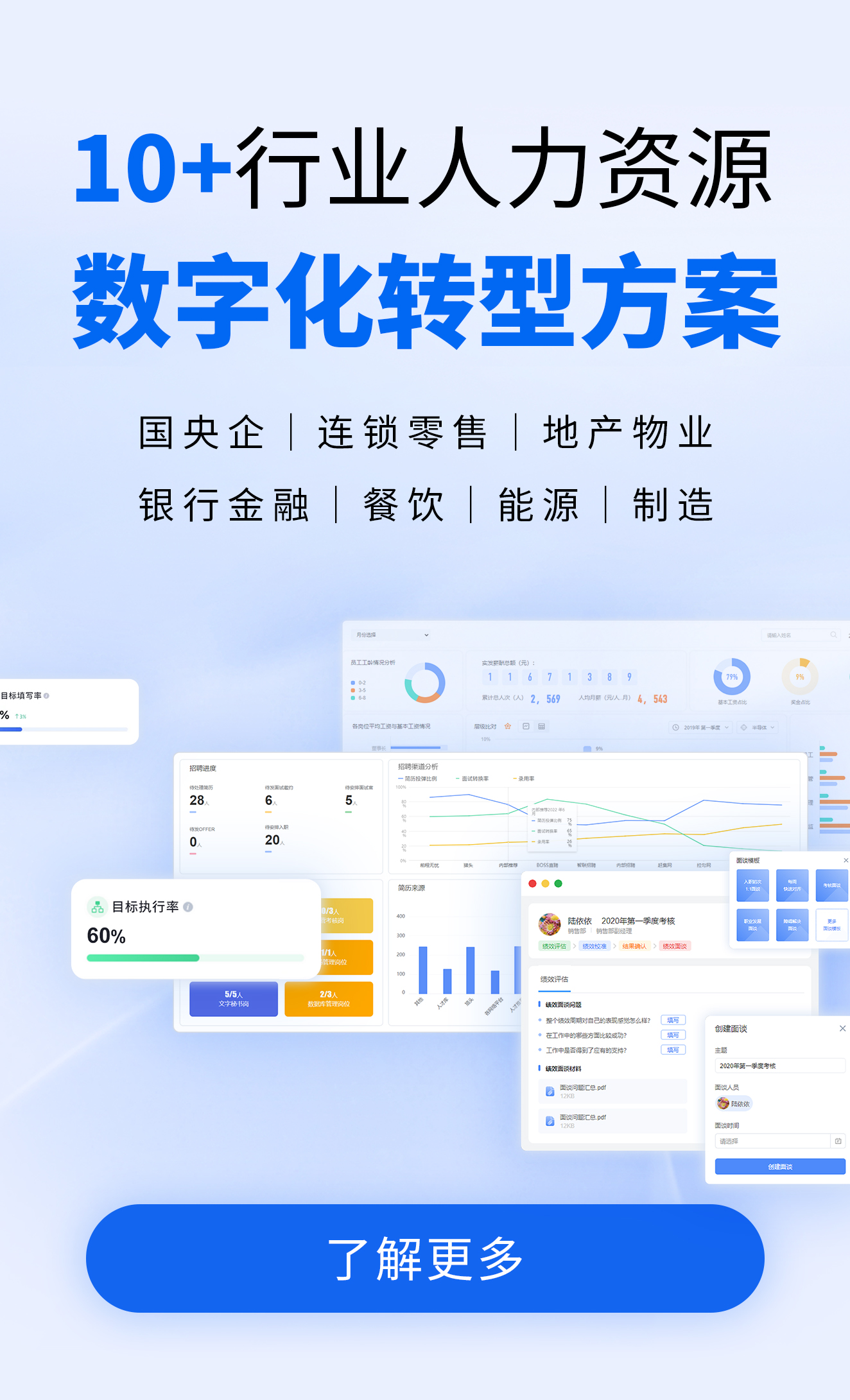
-

行业资讯
INDUSTRY INFORMATION
面对AI浪潮,不少企业急于将智能化工具引入人力资源管理,却往往在部署后遭遇效果打折的困境。根本原因在于忽视了数据底座的建设。AI的智能程度取决于喂养它的数据质量。对HR而言,若内部人事数据处于割裂、脏乱状态,再先进的算法也无法发挥作用。理清数据,才是AI转型真正迈出的第一步。

一、工具狂欢下的冷思考:AI落地为何频频受阻
当前市场上各类AI人力资源产品层出不穷,从智能简历解析到对话式员工服务,再到离职倾向预测,功能令人眼花缭乱。许多企业HR部门在业务焦虑与技术浪潮的双重推动下,急于采购这些工具,期望立刻实现管理跃升。现实却常常给人泼冷水。系统上线后,简历解析错误率居高不下,智能客服答非所问,预测模型给出的结论与实际大相径庭。
问题往往不在于算法本身,而在于算法运转所需的燃料——数据。AI的本质是通过对海量历史数据的深度学习来发现规律,进而对新情况做出判断或生成内容。如果输入给AI的是残缺、矛盾、标准混乱的数据,输出的结果必然是不可用甚至有误导性的。许多HR在未清理自家数据“烂摊子”的情况下,就把AI工具当成了救命稻草,结果自然是投入大量预算,却只买来了一个昂贵的摆设。
人力资源数据不同于财务或销售数据,它具有高度的复杂性和主观性。一个员工的绩效评级,背后可能掺杂了主管的主观偏好;一份岗位说明书,可能多年未更新,与实际工作严重脱节。让AI去学习这些充满噪音的数据,它只会把过去的偏见和错误放大。盲目迷信工具,跳过数据基础的夯实,是HR在AI转型中最大的陷阱。
二、算法的燃料:数据质量决定AI效能的上限
AI的效能存在一个无法逾越的定律:垃圾进,垃圾出。数据质量决定了AI能力的上限,而算法只是在逼近这个上限。在人力资源领域,高质量的数据意味着准确、完整、一致、及时且具备合理的结构。
准确性是最基本的要求。员工的基本信息、薪酬记录、考勤数据如果存在录入错误,AI在进行人力成本分析或合规审查时就会给出错误信号。完整性同样关键。如果历史培训记录大量缺失,AI就无法准确识别员工的能力短板并推荐合适的课程;如果离职面谈记录没有结构化存储,AI也难以挖掘出真实的离职动因。
一致性是另一个容易被忽视的痛点。在不同业务线或不同地域的分公司,同样的岗位可能有着截然不同的职级命名体系。一家公司的“高级工程师”,在另一家可能叫“资深技术专家”。如果缺乏统一的数据标准,AI在进行内部人才盘点时,就无法将这些岗位进行对等匹配,跨部门调配人才也就无从谈起。
时效性更是直接影响决策的有效性。员工的项目经历、技能标签是动态变化的,如果数据库不能实时更新,AI基于过时的员工画像推荐项目成员,必然导致人岗错配。只有当这些数据维度都达到较高水准,AI才能发挥真正的威力,实现从“描述过去”到“预测未来”的跨越。
三、深陷泥潭:HR数据治理的典型病灶
想要整理好数据,必须先看清当前HR数据管理中存在的顽疾。许多企业的HR数据现状,可以用四个字概括:散、乱、缺、错。
散,即数据孤岛林立。招聘系统用的是A厂商,考勤系统用的是B厂商,绩效管理又依赖内部开发的平台,各个系统之间数据互不相通。一个员工的完整生命周期数据被割裂在不同的系统中,想要拼凑出全貌,需要HR手工导出多份表格进行VLOOKUP,不仅耗时耗力,还极易出错。
乱,即标准缺失。以最基础的岗位名称为例,“产品经理”与“产品企划”是否代表同一类岗位?不同部门的定义大相径庭。在技能标签上,有人写“精通Python”,有人写“熟悉后端语言”,缺乏统一的技能词典。这种标准的不统一,让AI在处理数据时无所适从,无法建立有效的关联关系。
缺,即关键数据留白。很多企业的人事系统里只有员工入职时填写的静态信息,如学历、年龄、身份证号,而缺乏动态的业务交互数据。员工在项目中的具体角色、解决关键问题的表现、360度评估的细项反馈,这些真正能反映人才质量的数据往往没有被记录或结构化存储。
错,即历史数据脏污。长期缺乏维护的数据库里,充斥着大量无效信息。已经离职三年的员工状态仍显示为“在职”,组织架构树中存在早已撤销的部门,重复录入的员工档案导致人数统计虚高。这些“脏数据”如果不清洗,就会成为毒害AI模型的源头。
四、破局之道:构建支撑AI运转的数据底座
理清数据是一项枯燥且艰难的工作,但这是通往AI转型的必经之路。HR部门需要从盘点、统标、清洗、机制四个层面,踏踏实实地构建数据底座。
全面盘点是起点。HR需要搞清楚企业内部到底有哪些数据资产,它们分布在哪里,由谁负责录入和维护。这不仅仅是列一个系统清单,而是要深入到每一个数据字段,了解其业务含义和流转过程。通过盘点,识别出核心数据与边缘数据,明确数据孤岛的具体位置。
统一标准是核心。建立企业级的人力资源数据字典,对每一个字段的定义、取值范围、格式规范做出明确规定。比如,将全公司的职级体系映射为统一的代码,将技能标签收敛到标准的技能词典中。只有讲同一种语言,数据才能被AI正确理解。这往往需要HR推动跨部门、跨业务线的沟通对齐,难度极大,但价值也最大。
彻底清洗是硬仗。针对历史积累的脏数据,必须投入人力进行专项清理。去除重复记录,补全缺失字段,纠正错误格式,将非结构化的文本信息(如简历、面评)转化为结构化的标签。这个过程无法一蹴而就,需要制定清洗规则,分批次、分模块地推进。
流程固化是保障。数据治理不是一次性项目,而是一项长期运营工作。如果只清理旧数据,不约束新数据的产生,很快又会回到脏乱差的状态。HR必须将数据标准嵌入到日常业务流程中。在系统录入环节设置校验规则,拒绝不符合规范的数据写入;明确数据录入的责任人,将数据质量纳入考核。只有让数据规范成为工作习惯,才能保证底座的长效洁净。
五、从工具人到架构师:HR角色认知的蜕变
面对AI转型,HR的价值不在于熟练操作多少个智能工具,而在于能否成为连接业务需求与数据架构的桥梁。懂业务,更懂如何用数据描述业务,这是未来HR的核心竞争力。
当AI可以自动筛选简历、生成Offer、回答员工常规咨询时,HR的精力应当释放到更具战略性的工作上。其中最关键的一项,就是定义业务规则与数据逻辑。AI不知道什么样的人才是高潜人才,除非HR能清晰地描绘出高潜人才的画像,并将其转化为可量化、可追踪的数据指标。AI也不知道在人力成本紧缩时应该优先保留哪些岗位,除非HR能将业务战略拆解为人才结构的调整逻辑,并让系统理解这些逻辑。
这就要求HR具备数据思维。在审视任何人力资源流程时,不仅要关注流程的合规性和效率,还要思考这个流程产生了什么数据,这些数据能否被后续的分析和AI训练所用。在选型采购新系统时,数据开放性和接口能力应当成为核心评估指标,坚决摒弃那些制造新数据孤岛的产品。
结语
AI转型绝非采购几套软件那般简单,它是对企业数据底座的一次严苛大考。对于HR而言,与其在琳琅满目的工具市场中盲目跟风,不如沉下心来审视自家的数据资产。把散乱的数据拼接完整,把矛盾的标准梳理统一,把缺失的标签补齐。这番苦功夫看似缺乏科技感,却是决定AI能否在人力资源管理中生根发芽的关键。手握干净、有序的数据,工具的引入只是水到渠成;脱离数据谈AI,终究只是空中楼阁。[DONE]