-

行业资讯
INDUSTRY INFORMATION
【导读】 人才库系统的分水岭不在于功能多不多,而在于能否把候选人数据变成可触达、可协同、可审计的业务资产。本文面向猎头公司管理者与交付负责人,围绕2026年常见的四个系统建设误区,给出从数据治理到合规证据链、从API协同到能力图谱的修正路径,同时回答高频问题:猎头公司人才库系统怎么选才不踩坑。读完你能得到一套可直接落地的检查清单与流程框架,用更低的返工成本换取更稳定的交付质量。
人才库系统在猎头行业并不是新事物,但真正的矛盾来自两个“同时发生”:一方面,系统采购和AI功能升级越来越快;另一方面,顾问端的实际体验却常常停留在“导入了一堆简历、搜索更快了一点”,交付端仍被低效的重复沟通、状态不同步、合规不确定性拖住。我们在大量项目复盘中看到,问题并不主要出在某个按钮不好用,而是出在“把系统当软件项目做完”——而不是当成可持续运营的数据资产工程。
2026年之后,客户对交付的要求会更细:推荐链路要能追溯、候选人数据要能说明授权范围、过程记录要能经得起审计;同时,岗位需求更复合,单纯靠JD关键词检索会越来越难命中。也因此,避坑的关键不是再换一套系统,而是用正确的建设逻辑纠正四类典型误区。
一、误区一:重采购、轻治理——从简历仓库滑向数据负债
只把人才库系统当作采购清单上的一项,短期看是上线速度,长期看是数据快速贬值与检索失真。治理缺位时,系统越“满”,交付越慢,因为有效线索会被无效噪声淹没。
1. 误区现象:追求快速上线,批量导入即视为完成
不少猎头公司的人才库系统项目,交付验收的指标往往是账号开通、历史简历导入量、字段是否齐全。上线后顾问很快遇到三类具体场景:
- 导入量大但不可用:同一候选人多版本简历并存,姓名拼写不一致(中英文、别名、简写混用),搜索结果充斥重复条目;顾问为了“先推进”,继续在微信或本地表格记录新信息,导致系统成为“后补录的档案库”。
- 标签靠手工堆叠:入库时被要求勾选过多字段(期望薪资、可到岗时间、关注行业等),顾问在高压交付下只填关键项甚至随意填,后续检索的准确率自然下降。
- 缺少生命周期规则:候选人三个月未联系、半年未更新、一年未验证的状态没有任何自动动作,系统里“活跃资产”和“历史痕迹”混在一起,检索命中率越来越像抽奖。
这里的关键判断标准是:如果一个库里候选人数量在增长,但“可触达率、意愿活跃率、可推荐率”持续走低,这就不是增长,而是数据在衰减。提醒一句:先不要急着加功能,先把治理动作补齐,后续讨论合规与协同才有地基。
2. 核心后果:数据衰减让交付成本上升,且会反向伤害顾问习惯
“数据衰减”对猎头公司的伤害常被低估,因为它不是一次性事故,而是持续发生的隐性成本。最常见的链条是:
- 现象:顾问搜到10个“看起来合适”的人,逐个触达后发现电话失效、已离职转行、薪资涨幅超预算、地域不可谈。
- 机制:系统里缺少“更新时间权重”,也缺少“状态变更触发器”。于是旧数据与新数据同权展示,顾问的每一次检索都会被迫支付更多验证成本。
- 结果:顾问形成逆向激励——越觉得系统不可靠,越倾向于把关键信息放在个人微信与笔记里,系统进一步失真。
为了把问题讲透,我们建议把人才库系统的运营指标从“存量规模”切换成“有效资产密度”。一个可执行的口径是:近30天成功触达且愿意沟通的候选人占比、近90天完成一次信息校验的候选人占比、近180天产生过推荐动作的候选人占比。注意,这些指标不一定要对外披露,但必须在内部仪表盘里可被持续跟踪,否则治理会退化成口号。
表格1:传统简历仓库 vs 现代人才资产库对比
| 维度 | 传统简历仓库(高风险形态) | 现代人才资产库(可运营形态) |
|---|---|---|
| 数据目标 | 多多益善 | 可触达、可验证、可复用 |
| 更新机制 | 依赖顾问自觉 | 有SOP与系统触发(提醒/降权/冻结) |
| 检索逻辑 | 关键词命中 | 分层筛选 + 权重排序 + 否决原因复用 |
| 关键指标 | 简历总量、导入量 | 活跃率、可推荐率、复用率、负筛选准确率 |
| 失败信号 | 顾问回到Excel/微信 | 顾问愿意把关键过程留在系统 |
过渡提醒:当治理不足时,任何AI匹配都会被旧数据“喂坏”,第二个误区往往紧随其后。
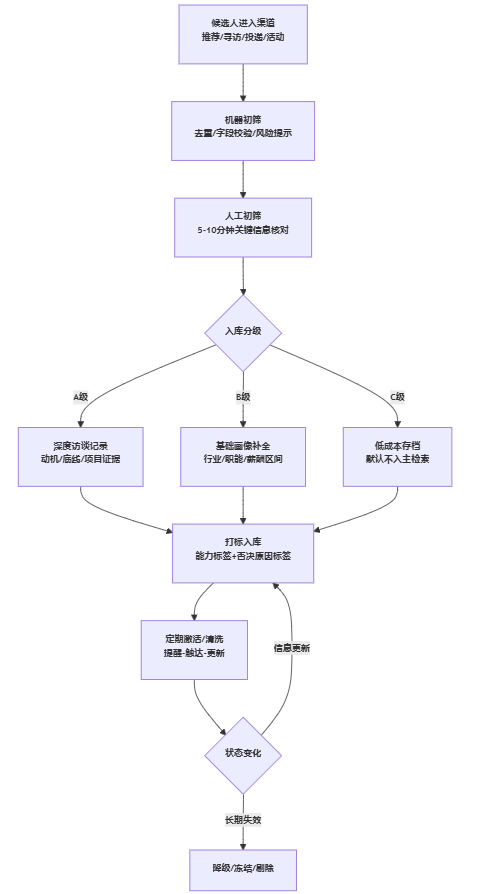
3. 正确路径:入库即分级、动态调权重,把治理写进日常动作
治理不是大项目,而是一套低摩擦的日常动作组合。我们建议采用“分级 + 调权 + 触发器”的三件套:
- 入库即分级:用A/B/C三级就够用,避免过度精细导致执行崩坏。
- A级:完成深度访谈记录(关键动机、底线条件、薪资结构)、至少一次信息核验(在职状态、关键项目真实性)、可在特定赛道反复推荐。
- B级:完成初筛与基础画像,能用于同类岗位备选。
- C级:仅有公开信息或历史简历,默认不进入主检索列表,需要二次验证后才能升级。
- 动态调权重:把“更新时间、触达结果、意愿强度、关键字段完整度”作为排序权重。越新、越可触达、越有明确意愿的候选人越靠前。
- 触发器固化到系统:例如30天未更新自动提醒、90天无有效触达自动降权、180天信息不可验证自动冻结,冻结并不等于删除,而是把噪声隔离出主流程。
为了便于落地,我们把治理动作抽成一条可执行的SOP,方便你对照系统能力去配置。
治理做起来之后,你会发现系统的价值不再是“能不能搜到人”,而是“能不能更快排除无效选项”,这会直接降低单岗交付的验证成本。
二、误区二:重功能、轻合规——AI炫技跨过法律红线的代价更高
如果说误区一让你变慢,误区二会让你“停下来”:一旦触发个人信息保护与授权留痕问题,整改成本和业务中断风险往往远高于节省的那点时间。很多团队在问:猎头公司人才库系统怎么选才不踩坑,第一条其实是合规能力,而不是算法能力。
1. 误区现象:默认可抓取、默认可分析,把候选人当成可任意拼装的数据对象
在系统升级到“自动补全画像、AI生成摘要、自动打标签”后,常见的违规风险点集中在三类动作上:
- 未经明示授权的自动补全:系统从公开平台抓取教育、职历、项目描述后回填到人才库,并用于匹配推荐。公开可见不等于可被再加工并用于商业推荐,尤其当你进行了结构化整理、交叉分析与画像推断时,合规要求更严格。
- 把敏感信息当普通字段存:身份证号、家庭住址、婚育、健康状况、宗教信仰等信息,哪怕候选人在沟通中提到,也不意味着可以作为常规字段入库,更不能被用于自动筛选。
- 共享边界模糊:猎头把候选人信息同步给客户ATS、或在客户群里传播简历时,没有做到“用途限定、最小必要、可追溯”,一旦发生投诉,系统日志无法证明授权链条。
这里的反例提示也需要讲清楚:并非所有“系统自动化”都高风险。比如基于候选人已提供的简历做格式化解析、去重、联系方式校验,只要用途清晰且有授权依据,通常风险更可控;真正的红线是未经授权的扩展性使用与超范围共享。
2. 政策红线:授权留痕、用途限定、脱敏与审计日志缺一不可
合规不应停留在“法务提醒”,而要落到可执行的系统要求上。对猎头公司而言,四条底线最关键:
- 授权要可追溯:每一次入库、每一次向客户分享、每一次用于新的岗位推荐,最好都能关联到授权记录(时间、渠道、授权文本版本、操作者、授权范围)。
- 用途要限定:系统层面要能区分“用于某岗位推荐”“用于人才市场研究”“用于活动邀请”等用途,不同用途的授权应当可分离,不要用一次性大而全的授权覆盖所有场景。
- 敏感信息要最小化与脱敏:能不收集就不收集;确需收集时,权限、加密、脱敏展示、下载控制必须同步落实。
- 审计日志要能说清发生了什么:当出现争议时,你需要证明谁在什么时间、基于什么授权、对哪些字段做了什么动作,并且能追溯到客户侧是否也遵守了对应用途。
合规的实务难点在于:顾问会觉得这些动作“拖慢推进”。解决办法不是让顾问多点几次确认,而是把合规“前置并自动化”——例如系统在分享前自动判断是否缺授权,缺就弹出一键补授权流程;在导出时自动脱敏并生成水印与访问记录。
3. 正确路径:合规优先的系统规范,把风险拦截在流程里而不是事后补洞
要让合规变成业务能力,而不是负担,需要三个层面的设计:
- 制度层:明确边界
用内部制度把“可收集字段、可共享字段、不可收集字段、需单独授权字段”写成可操作的清单,并明确违规后的处理。制度不要写得像法律条文,写成顾问能用的行为准则即可。 - 系统层:用控件替代口头提醒
例如:- 无授权状态下,系统禁止向客户推送联系方式字段,只允许推送简历摘要与能力标签;
- 导出简历默认脱敏(电话后四位隐藏、身份证号全隐藏);
- 重要操作必须生成日志并可按候选人维度回溯。
- 运营层:把合规变成效率的一部分
通过模板化授权文本、标准化触达话术、自动归档授权记录,降低顾问的额外动作成本。合规做得好的团队,往往不是更慢,而是更稳——返工和争议更少。
表格2:2026年人才库系统合规自查清单(猎头公司版)
| 检查项 | 可验证标准 | 常见失败信号 |
|---|---|---|
| 入库授权 | 入库记录可关联授权文本与时间戳 | 只能口头说“候选人同意过” |
| 用途限定 | 系统支持用途类型选择并可查询 | 所有数据默认“可用于一切” |
| 最小必要 | 字段分级,默认不采集敏感信息 | 为了“完善画像”收集过多隐私 |
| 脱敏与权限 | 导出/共享默认脱敏,权限可配置 | 任意人都能下载全量简历 |
| 审计日志 | 可按候选人/客户/顾问追溯 | 只记录“导出过”,无细节 |
| 第三方共享 | API推送有白名单与记录 | Excel转发无法追踪去向 |
| 数据留存 | 有冻结/清理机制与保留策略 | 离职顾问带走数据或长期不清理 |
过渡提醒:当合规链条清晰后,才谈得上把人才库“接入客户流程”,否则协同越深,风险扩散越快。
三、误区三:重私有、轻协同——封闭系统造成价值孤岛,客户体验会先崩
2026年的客户并不缺系统,缺的是端到端的交付闭环:状态实时、信息一致、责任清晰。猎头人才库系统如果仍停留在“我这边有一套,你那边也有一套,中间靠Excel搬运”,本质上是用人工去对抗协同复杂度,交付规模越大越吃亏。
1. 误区现象:拒绝开放API、坚持本地封闭,协同靠人工传递
封闭策略通常有两类理由:一是担心数据安全,二是担心客户把猎头变成“供应商工单”。但在实际项目里,我们看到的更常见结果是:
- 状态不同步:猎头侧标记“已面试/待反馈”,客户ATS里还是“待安排”,双方对同一候选人的推进节奏产生误解,导致重复催促与候选人体验受损。
- 重复推荐与重复沟通:因为没有统一的候选人ID映射,顾问可能把同一个人以不同版本简历重复推荐;客户也可能安排重复面试,候选人对专业度的评价会直线下降。
- 反馈滞后:客户面试意见无法自动回流到猎头库,顾问只能靠微信或邮件收集碎片信息,难以沉淀为可复用的“否决原因标签”。
需要强调边界条件:对极少数高度保密岗位(例如涉密机构、特定安全领域),客户可能明确禁止任何API对接,这类场景下封闭并非错误;但大多数商业猎头业务,封闭带来的效率损失会长期抵消所谓“安全感”。
2. 效率损失:手工搬运不仅慢,还会让责任边界变得不可控
协同问题的本质不是“多花几分钟复制粘贴”,而是信息一致性被破坏后,责任边界会变模糊。举两个典型链条:
- 链条A:候选人体验受损
顾问在系统里更新了候选人的可面试时间,但未同步给客户→客户HR仍按旧时间安排→候选人临时改期→客户认为猎头沟通不到位→后续合作变得更“控价控时”,交付压力进一步增大。 - 链条B:合规风险被放大
猎头用Excel传递含联系方式的简历→客户侧二次转发扩散→候选人投诉数据被滥用→猎头无法证明共享边界与用途授权→争议成本回到猎头身上。
因此,协同能力不仅关乎效率,更关乎“可辩护性”:出了问题你能不能把链条讲清楚。提醒一句:如果你的系统对接能力弱,至少要用“共享链接+权限+水印+到期”替代Excel附件,把扩散风险降下来。
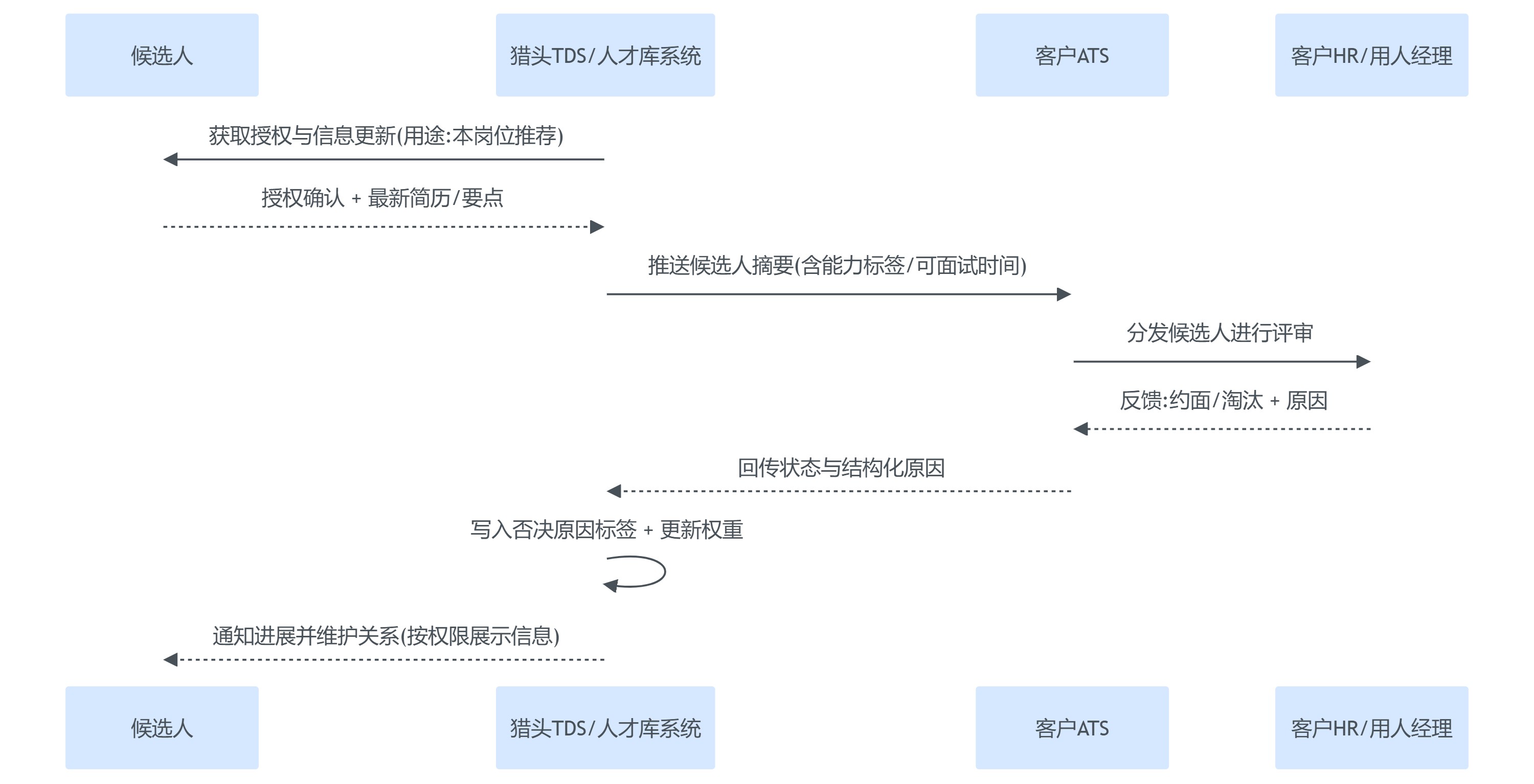
3. 正确路径:API优先与双向同步,让交付闭环自动沉淀
协同的落地建议从“最小闭环”开始,不必追求一次性全量打通。一个可执行的最小闭环是:
- 候选人推荐推送:猎头TDS向客户ATS推送候选人摘要(先不含敏感字段,或按授权规则推送)。
- 状态回传:客户ATS把“已查看/约面/通过/淘汰”的关键节点回传给猎头TDS。
- 原因结构化:淘汰原因至少沉淀为可复用标签(薪酬超预算、能力欠缺点、文化适配问题、到岗时间冲突等)。
- 触发下一步动作:回传后自动触发顾问待办(补充备选、安排复盘、候选人安抚与再推荐等)。
下面用一个时序图把双向协同讲清楚,便于你与IT或供应商对齐需求边界。
当这个闭环成立后,人才库系统会出现一个很重要的变化:它不再只记录“发生过什么”,而开始积累“为什么会这样”。这类因果标签(尤其是淘汰原因)会显著提升后续岗位的命中率。
四、误区四:重当下、轻演进——静态标签无法匹配复合型人才需求
岗位越来越复合,候选人的能力表达也越来越“项目化、跨界化”。如果人才库系统仍以静态岗位词为中心(Java、HRBP、销售总监),你会发现越到高端岗位越难搜到“真正合适的人”,因为合适的人往往不按你的分类方式描述自己。
1. 误区现象:只支持显性标签,难以描述复合能力与迁移路径
现实场景里,企业提出的需求常是能力组合而非单一职位,例如:
- 供应链产品经理,但要求具备AI提示工程实践、能推动跨部门数据治理;
- 医疗器械市场负责人,但要求有注册申报理解与渠道数字化经验;
- 制造业HRD,但要求组织诊断与一线用工合规经验,并能推动共享服务中心落地。
如果系统只能存“岗位名+年限+城市+薪资”,顾问最终仍要靠脑内记忆去做复杂匹配,系统只剩下“通讯录+简历附件”。这并不是系统不够先进,而是标签体系的最小粒度选错了:你用岗位词当原子单位,但市场已经用能力组合当原子单位。
2. 市场变化:复合型需求增加时,关键词检索会出现结构性失配
复合型岗位增长会带来一个结构性后果:同一岗位的JD里包含多个领域关键词,传统检索会把“同时命中多个关键词”误认为更匹配,但它无法识别候选人是否在真实项目里做过关键动作。
举例:JD写了“数据治理、供应链、AI”,候选人简历也写了这些词,但可能只是参与过一个数据看板项目;而真正合适的人可能从未写过“AI”,却在项目中做过自动化决策、提示词优化或模型应用推动。静态检索只能识别字面相似,无法识别能力迁移与项目深度。
边界条件也要说清:并非所有岗位都需要能力图谱。大量标准化基层岗位(例如批量蓝领招聘、标准客服岗位)用规则与关键词足够;真正需要升级的是中高端、跨职能、强项目制岗位,以及客户对“可复用人才管道”要求更高的行业。
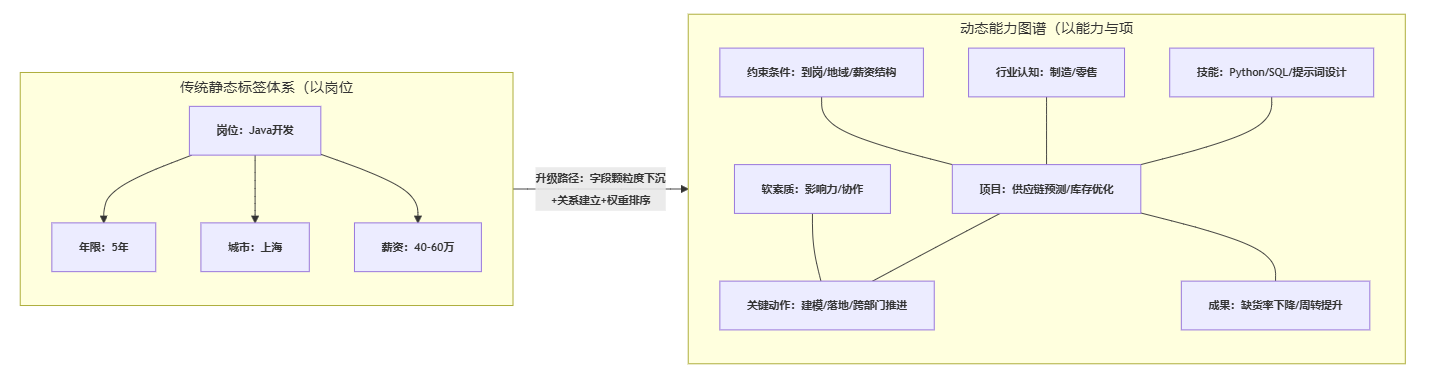
3. 正确路径:从岗位标签走向能力颗粒度的动态图谱
“动态图谱”听起来像技术名词,但落地时可以非常务实:把候选人信息拆成更细的可检索单元,并建立关系。
- 能力颗粒度:技能(会什么)、场景(在哪类业务中用过)、成果(做到什么程度)、角色(主导/参与/协作)、约束条件(预算、人力、周期)。
- 结构化沉淀:每次访谈不追求写长文,而是把关键信息结构化录入:项目类型、关键动作、结果指标、客户类型、团队规模、决策影响力。
- 多维交叉检索:允许顾问用“行业+项目类型+关键动作+约束条件”来组合检索,而不仅是岗位名。
用一张结构图说明从静态标签到动态图谱的演进路径,便于团队统一认知。
当你把“能力与项目”沉淀下来,系统的智能并不是匹配到更多人,而是更快定位到少数可验证的候选人,并把淘汰原因反哺到下一次检索中。
结语
回到开篇那个问题:猎头公司人才库系统怎么选才不踩坑。从实践看,选型只是起点,真正决定成败的是你是否把系统当成一套“可运营、可协同、可审计、可演进”的机制,而不是一次性采购。
给猎头公司管理者与交付负责人的可执行建议如下(按优先级排序):
- 先做数据体检再谈升级:抽样检查去重率、近90天更新率、近30天可触达率、以及“主检索结果中A级/B级占比”,用数据定义治理缺口,而不是凭感觉推翻重来。
- 把合规做成系统能力:要求供应商提供授权留痕、用途限定、脱敏导出、审计日志等能力;对外共享一律走可追溯链路,尽量用链接与权限替代Excel附件。
- 从最小闭环开始打通协同:先实现候选人摘要推送与状态回传,再逐步扩展到原因结构化与触发待办,避免“一口吃成平台”导致项目烂尾。
- 标签体系下沉到能力颗粒度:对中高端与复合岗位,建立项目-动作-成果的结构化字段与关系,允许顾问用组合条件检索,并把淘汰原因变成可复用资产。
- 用运营机制保障落地:每周固定清洗、每月复盘字段质量、每季度调整权重规则;把“系统使用质量”纳入交付管理,而不是只看顾问产出数量。
这四步做扎实,你的人才库系统才会从“简历堆放处”变成稳定的交付底座:既能提升效率,也能降低合规与协同带来的不确定性。