-

行业资讯
INDUSTRY INFORMATION
当前,复杂排班正在从“班表怎么排”升级为“产能如何用人来兑现”的系统工程,而本文也将面向制造型企业CHRO、厂长/运营负责人、IT与数字化负责人,围绕智能排班系统的能力边界与选型逻辑,给出“四大支柱”评估框架(战略、技术、组织、生态与合规)及一条可执行的实施路径,帮助企业在订单波动、技能复用、合规约束与员工体验之间建立可持续的排班机制。
制造业的排班问题之所以在2026年被频繁讨论,并不只是“人难招、成本高”这一类常见叙事,而是生产组织方式本身在变化:多品种小批量、插单常态化、跨工序协同更紧密,使得排班从车间主任的经验活,变成需要数据、规则与协同链路共同支撑的管理动作。与此同时,国内对工时、休息休假、加班管控、用工留痕等要求持续细化,跨地区经营或出口业务还会叠加海外合规压力——一旦排班与考勤、计薪口径不一致,风险会以投诉、仲裁、审计、客户验厂等形式集中暴露。
问题也因此变得更具体:到底要选一套什么样的系统,才能真正解决复杂排班,而不是把Excel搬到线上?
一、困局再审视:2026年制造业复杂排班的新内涵
1. 需求侧的波动性:从“计划排班”走向“滚动修正”
很多制造企业过去的排班逻辑建立在月度/周度计划上:订单相对稳定、产线节拍可预测,班次调整更多是“临时加人”或“加班顶上”。但从实践看,插单与急单越来越像常态,排班需要具备“滚动修正”的能力:今天的排班不仅要覆盖明天的人,还要对未来1-4周的需求变化做预留与再平衡。
这里的关键机制是:需求波动会放大“人力冗余/短缺”的两类成本。短缺导致交付风险与加班上升;冗余带来待工、低人效与用工结构扭曲。真正的复杂点在于,生产计划变更往往不是一次性的,而是连续发生——没有系统支撑时,基层管理者只能用“经验+电话+微信群”做补丁式调度,结果常见为:班表更新不及时、考勤口径对不上、员工对公平性产生质疑。
应对上,企业在需求侧需要明确三个输入给排班系统:
- 订单/产量的滚动预测频率(按日、按班次还是按周)
- 关键工序的产能约束(瓶颈工序、人机比、换线损失)
- 允许的弹性边界(可接受的加班上限、临时借调比例、外包触发条件)
提醒一句:如果企业的生产计划本身没有形成相对稳定的数据来源(例如MES数据断点多、工时定额缺失),再强的排班算法也会“巧妇难为无米之炊”。
2. 供给侧的多样性:技能矩阵与跨产线协同让“人岗匹配”变成计算题
制造业的用工供给正在出现结构性变化:一方面,一人多岗、复合工越来越普遍;另一方面,跨产线、跨车间的支援调度增加。复杂排班因此不再是“哪个人上哪个班”,而是“哪个技能组合在什么时点覆盖哪些工序”。
这背后需要两个基础能力:
- 技能标签体系:员工会什么、熟练度如何、能否独立上岗、是否需要带教;
- 岗位能力模型:每个工位对技能等级、证照、健康限制(如高温、夜班)等要求。
当企业没有技能矩阵时,排班只能依赖“老班长记忆”;当技能矩阵有了但没有进入系统,排班依然会在“记录—沟通—核对”中消耗大量时间。系统化的价值在于把“人岗匹配”从口头确认变成可校验的约束条件:不满足资格就不能排、跨岗需要触发培训或授权流程、关键岗位缺人会预警。
边界条件也要说清:若企业的岗位标准高度非标准化(例如同一岗位在不同产线差异极大、SOP不稳定),技能标签再精细也很难用于自动排班;此时更现实的路径是先把岗位族/工序族梳理出来,让“可通用的部分”先进入系统。
3. 合规性的收紧性:工时规则、留痕与审计把排班推向“强约束优化”
过去不少企业对排班合规的理解停留在“不超法定工时”。但现实是,合规风险往往来自“细则口径不一致”:班次定义、休息时长、加班触发条件、调休规则、特殊工时审批、夜班津贴、跨天班计入哪一天等,只要任一环节口径在班表、考勤、计薪之间不一致,就会形成争议点。
2026年的趋势之一,是企业越来越需要“可审计的排班过程”:谁改了班、为什么改、审批链路是否完整、是否触发超时预警、是否有员工确认或公告留痕。尤其在劳动争议、客户验厂、集团内审的场景下,系统不仅要算得对,还要留得住证据。
这里有一个常被忽略的反例:如果企业管理文化是“口头指令优先”,即便系统具备合规引擎,也可能被频繁绕开(线下临时换班、代打卡、事后补录)。因此选系统之外,还必须把“排班—考勤—计薪”的闭环责任明确到人。
4. 体验感的优先性:公平与可预期性决定排班执行度
复杂排班的难点还在“执行”而不止“生成”。新生代员工对班次的接受度,往往取决于两点:公平与可预期。公平包括夜班/周末班分配是否均衡、加班机会是否透明;可预期包括班表提前多久发布、临时变更是否有补偿或协商机制。
从实践看,很多企业不是没排出班,而是排出的班“落不下去”:员工频繁换班、临时请假导致链式调整、主管被迫回到手工协调。系统在体验侧的关键能力通常包括:
- 员工自助查看班表、请假/换班申请与审批
- 班次偏好采集(可设置优先级与可用范围)
- 公平性指标(夜班次数、周末班次数、加班时长分布)可视化
- 变更通知与确认机制(减少“我不知道”带来的冲突)
这里可以把复杂排班理解为一张“约束网络”(这是本部分唯一的类比):需求、技能、合规、体验四类约束同时存在,系统的作用是让约束可计算、可追溯、可协同。
| 维度 | 传统排班(Excel/人工) | 智能排班系统(规则+优化) |
|---|---|---|
| 响应速度 | 临时变更靠沟通,速度不稳定 | 支持滚动排班与快速重算,变更留痕 |
| 人岗匹配 | 依赖经验记忆,难校验 | 基于技能矩阵与资质约束自动校验 |
| 合规风险 | 事后发现问题,补救成本高 | 规则引擎前置校验,超限预警 |
| 员工体验 | 公平性难量化,信息不透明 | 偏好采集、自助换班、透明指标 |
| 管理成本 | 反复核对、跨部门扯皮 | 排班—考勤—计薪闭环,减少对账 |
(表格1 传统排班 vs 智能排班关键差异对比)
二、破局双引擎:驱动智能排班的技术与管理内核
智能排班系统的价值不在“自动排班”四个字,而在于把复杂约束转化为可执行的规则体系,并用算法在约束下寻优。技术决定上限,管理决定落地质量;缺一不可。
1. 技术引擎:从“自动化”到“智能化”的跃迁
制造企业在选系统时,经常被“AI排班”吸引,但需要追问:AI解决的到底是哪一段问题?从系统结构看,技术引擎至少包含三层能力。
(1)AI预测:把需求从“拍脑袋”变成可迭代的假设
预测并不等于算得准,而是让预测过程可迭代:输入订单、历史产量、节假日、设备稼动、良率波动等,输出未来若干周期的用工需求区间,并给出置信度。对制造业而言,更现实的目标往往是“把误差控制在可管理范围内”,而不是追求单点极准。
(2)运筹优化:在硬约束下生成近优解,而非漂亮的理论最优
排班是典型的约束优化问题:技能、工时、休息、班次覆盖、加班上限、连班限制、关键岗位必须覆盖等,都会变成硬约束;员工偏好、公平性、人效目标通常是软约束或目标函数。成熟系统应支持:
- 约束可配置(不同车间/班组可用不同规则集)
- 目标可切换(以成本优先、人效优先或合规优先等)
- 结果可解释(为什么某人被排到某班、哪个约束导致无法满足偏好)
(3)实时数据集成:没有数据联动,排班就会与生产脱节
排班系统至少要与ERP/MES/考勤/薪酬形成数据闭环:
- MES侧给出工序节拍、开线计划、设备状态(停机/保养)
- ERP侧给出订单与交付节奏
- 考勤侧反馈到岗与异常(迟到、缺勤、临时调岗)
- 薪酬侧承接工时与津贴口径
如果系统只能“导入导出”,而不能稳定对接,那么滚动排班会被数据延迟拖垮,最终仍会回到人工修补。
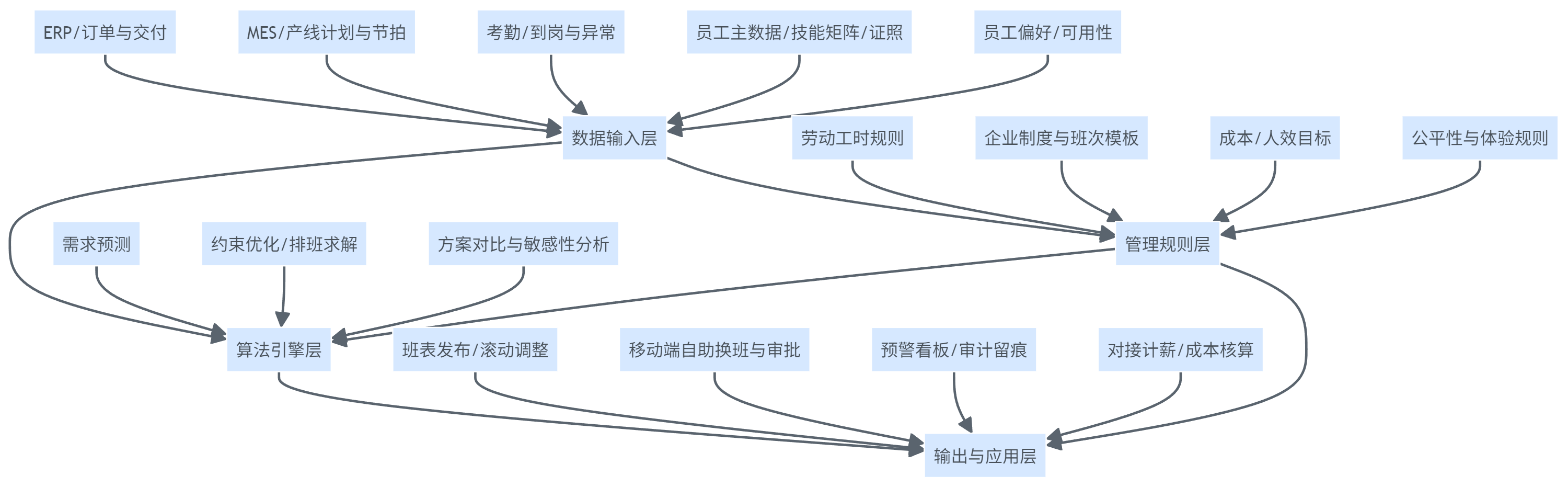
(图表1 智能排班系统核心架构图)
2. 管理内核:从“效率至上”到“多维平衡”的升华
排班系统最终服务的是经营目标,而经营目标往往互相牵制:既要交付,也要成本;既要合规,也要弹性;既要公平,也要效率。管理内核的任务,是把这些目标转化为可度量、可对齐的指标体系与决策规则。
(1)成本与人效模型:把“感觉加人/减人”变成算得清的账
制造企业常用的排班指标包括:工时利用率、加班占比、缺勤率、单位产出工时、关键岗位空缺时长、外包触发次数等。系统应支持将这些指标与排班方案关联,形成“方案A vs 方案B”的可比较结果。
但也要注意副作用:若企业只盯“加班降下来”,可能会通过增加人头或降低覆盖率实现,反而影响交付或带来隐性成本;因此指标必须成组使用,而不是单点考核。
(2)合规性风控:让规则成为不可逾越的硬边界
合规的本质不是“多审批”,而是把关键风险点前置:
- 超时与连班预警(生成阶段即阻断/提示)
- 休息休假规则校验(尤其是跨天班、倒班、综合工时等场景)
- 审批链与留痕(调班、加班、补卡等关键动作可追溯)
在多地区经营时,还要支持分地域规则集:同一集团、不同工厂的地方性政策口径不同,系统必须允许差异化配置,而不是“一刀切模板”。
(3)员工体验(ESE)管理:执行度来自透明,而不是口号
体验管理的关键不在“给员工更多选择”,而在“给出可解释的约束与交换条件”:哪些班次可以偏好、哪些必须由资格覆盖、临时变更如何补偿、夜班如何轮换。系统能提供公平性看板、偏好满足率、变更频次等指标时,管理者更容易与员工建立可沟通的规则体系。
三、决策罗盘:制造企业智能排班系统选型的四大支柱
支柱一:战略契合度
首先要回答一个问题:企业希望排班系统优先解决什么?
不同战略下,系统能力的权重不同:
- 成本领先型:关注加班占比、用工结构(正式/派遣/外包)、多技能覆盖带来的冗余减少;需要强成本测算与预算控制能力。
- 交付敏捷型:关注排班与生产计划联动、临时插单的重排效率、关键岗位覆盖率;需要强集成与快速重算能力。
- 质量与安全优先型:关注资质校验、带教排班、疲劳管理(夜班连续次数、休息时长);需要强约束校验与风险预警能力。
因此,企业需要在选型前形成一页纸的“排班目标声明”,且至少包含:
- 业务优先级排序(成本/交付/质量/合规/体验);
- 试点范围(哪条产线/哪个车间/哪些班组);
- 关键指标(3-5个,且明确口径与数据来源)。
支柱二:技术先进性
技术先进性不等于“有AI”,而是看它能否在制造业约束下稳定产出可用结果,并支持持续迭代,因此重点评估问题包括:
- 算法透明度与可解释性:能否说明约束、目标、冲突处理逻辑?能否输出“不可行原因”(例如某天因资质不足无法满足覆盖)?
- 持续学习能力:预测模型是否能基于实际偏差进行校准?是否支持按产线/工序差异化训练或参数配置?
- 规模与性能:多车间、多班组并行求解是否稳定?重排耗时能否满足管理节奏(例如15分钟内给出可执行方案)?
- 数据治理能力:主数据(员工、岗位、班次、技能)是否有校验机制?能否避免“垃圾进垃圾出”?
支柱三:组织适应性
排班系统落地最大的摩擦来自组织端,即“车间主管嫌麻烦、HR担心背锅、员工不愿配合”,而这也意味,组织适应性评估要落到“谁用、怎么用、用到什么深度”,关键点包括:
- 规则配置灵活性:是否支持班次模板、轮班规则、综合工时/特殊工时、跨天班、休息规则等配置?能否按车间差异化?
- 角色与权限:班组长、车间主任、HR、薪酬、工会/员工代表各自能看什么、能改什么?是否支持审批流自定义?
- 移动端体验:员工能否自助查班、申请换班/请假、收到变更通知并确认?基层是否能在现场快速处理异常?
- 可训练性:上线后是否需要大量“系统管理员”手工维护?供应商是否提供规则顾问与运维机制?
支柱四:生态与合规性
制造业的系统不是从零开始,排班系统必须嵌入既有生态,否则就会出现“班表一套、考勤一套、计薪一套”的三套账。
建议重点核查:
- 集成方式:是否提供开放API、消息机制、标准接口?是否支持与ERP/MES/门禁考勤/薪酬系统的双向同步?
- 数据一致性:班次、工时、津贴、加班口径能否贯通到计薪与成本核算?是否支持对账与异常追踪?
- 合规引擎更新机制:当法规或集团制度调整时,规则更新由谁负责、多久能上线、如何回溯历史?
- 安全与权限审计:员工个人信息、考勤数据、排班变更记录属于敏感数据,访问控制、日志审计、加密与等保要求需明确。
| 支柱 | 关键评估问题 | 证据/验证方式 | 常见风险信号 |
|---|---|---|---|
| 战略契合度 | 系统能否支撑交付/成本/质量的优先级? | 指标口径对齐+试点目标书 | 只讲功能不谈指标,或无法给出业务场景方案 |
| 技术先进性 | 约束与目标是否可解释?重排速度如何? | POC三类冲突测试+性能压测 | 黑盒算法、无法说明不可行原因、重排耗时长 |
| 组织适应性 | 车间主管与员工是否愿意用? | 角色走查+移动端演练+培训成本测算 | 依赖少数“超级用户”,基层认为额外负担 |
| 生态与合规性 | 能否与MES/考勤/薪酬闭环? | 接口清单+数据对账+合规规则演示 | 只能导入导出、口径对不上、规则更新无机制 |
(表格2 四大支柱选型评估矩阵)
(图表2 智能排班系统选型全流程图)
结语
回到开篇问题:制造型企业如何选择系统解决复杂排班难题?答案并不是“买一套更贵的工具”,而是用四大支柱把系统能力与企业战略、数据基础、组织执行力、合规边界对齐,再用试点把不确定性变成可验证的改进清单。对多数制造企业而言,真正的分水岭在于能否建立“排班—考勤—计薪—成本/人效”的闭环,而不是班表排得多漂亮。