-

行业资讯
INDUSTRY INFORMATION
【导读】 月末算薪系统崩溃,本质不是“系统算不出”,而是企业在法定发薪时点前,无法稳定交付“可核对、可解释、可追溯”的工资结果。对制造业HR而言,最危险的不是多算几分钟,而是错发、漏发、延发叠加引发合规与群体信任风险。本文面向制造业HRD、薪酬HR、共享中心与工厂人事,给出一套可在72小时内落地的3步应急处理法(止损—兜底—闭环),并补齐“从救火到防火”的韧性治理清单,帮助你在月末算薪系统崩溃怎么办这一问题上,把损失控制在组织可承受范围内。
制造业算薪的复杂,往往是被“平时跑得挺顺”掩盖的:多班次、综合工时、计件、夜班津贴、临时调岗、缺勤与请假扣款、21.75计薪天数口径差异……这些要素在系统稳定时都能被规则引擎吞下去;但一旦在发薪窗口期宕机或数据断连,HR面对的就不再是“算工资”,而是“在证据不完整、时间极紧、情绪上升”的条件下完成交付。更现实的矛盾是:工资必须按约定周期发放,技术故障通常不被视为对员工的免责理由——这决定了HR必须准备一套脱离系统仍能运转的应急路径。
一、危机定性——为什么系统崩溃是HR的“至暗时刻”?
系统崩溃在制造业不是单纯IT故障,而是同时触发法律刚性、数据一致性、员工信任三类风险的复合事件。越是计件与排班复杂的工厂,越不能把它当成“等系统恢复再说”。
1. 法律刚性约束不可转移:按时足额发薪是硬义务
从合规视角看,发薪的“时点与义务”优先级高于“系统是否可用”。依据《工资支付暂行规定》等规则体系,用人单位应至少每月支付一次工资,并不得无故拖欠。现实执法与争议处理里,系统宕机、供应商故障、内部审批未走完,通常都很难自动构成对员工的免责理由——因为这属于企业内部管理能力范畴。
这会带来三个直接后果:
- 延发的合规成本可被放大:劳动监察介入、责令限期支付、在部分地区还可能涉及对“拖欠工资”行为的公开通报与信用影响。对制造业来说,一旦被贴上“发薪不稳”,招工与留工成本会显著上升。
- 责任主体难外推:即便企业使用第三方HR SaaS或外包薪酬服务,对员工仍是企业承担第一责任。与供应商的违约追偿属于“第二战场”,不能替代对员工的按期交付。
- “先发后算”并非天然安全:很多工厂会选择先垫付一个金额稳定情绪,但如果没有把“临时发放”与“最终结算”的规则讲清、证据留全,后续追补与扣回反而更容易引发争议。
边界条件也要说清:若确遇到区域性灾害、银行系统大面积故障等,企业仍应保留证据(政府公告、银行回执、故障证明)并采取替代支付路径(分批转账、现金/支票在合法合规前提下的方案)。但“我们系统坏了”本身,很难成为唯一理由。
2. 制造业算薪的“复杂性脆弱”:一宕机就从自动化退回手工战场
制造业算薪的脆弱点,不在“公式多”,而在“数据链长、口径多、联动强”。常见的联动关系包括:
- 考勤—工时—加班费:综合工时、排班制下,加班判定依赖班次与周期口径;系统断连时,HR很难仅靠导出的静态表还原“加班性质与倍率”。
- 计件—质量—补贴:计件数据来源可能在MES/产线报工/班组长提交表,质量扣款或返工扣减又在另一套系统;任一环断了,算薪就会出现“看似有数、实则不可核对”的黑洞。
- 21.75计薪天数与缺勤扣款口径差异:部分企业用21.75折算日薪,部分用当月实际应出勤天数;口径混用是争议高发源。系统崩溃时若临时改口径,属于主动制造风险。
从实践看,制造业在月末集中算薪的窗口期(如25号到次月3号),任何一处断点都会导致:数据导出不全、历史版本被覆盖、审批流无法追溯、自动校验规则失效。HR往往被迫在短时间内建立“临时事实源”,这也是为什么我们强调“先锁定数据再谈计算”。
表格1:常规算薪模式 vs 系统崩溃应急模式对比
| 维度 | 常规算薪模式(系统在线) | 系统崩溃应急模式(系统离线/不可信) | 主要风险点 |
|---|---|---|---|
| 数据源 | HRIS/考勤/绩效/社保联动汇总 | 多源导出+纸质/邮件审批+产线台账 | 数据缺口、口径冲突 |
| 计算逻辑 | 规则引擎自动判定倍率、扣款口径 | Excel/离线模板+人工判定规则 | 人为差错、解释困难 |
| 审批流程 | 系统流转可追溯 | 临时审批链(邮件/签字) | 留痕不足、追责困难 |
| 发放方式 | 批量代发、系统与银行接口 | 分批转账/临时代发清单 | 错发、重复发 |
| 风险控制 | 自动校验、报表审计 | 抽样/双人复核、差异比对 | 二次事故(恢复后重算不一致) |
3. 隐性信任成本:工资问题最容易被“放大解释”
薪资是员工对企业“是否讲规则”的最直接体验。系统崩溃如果处理得不透明,员工会把它解释为三种更坏的可能:企业资金紧张、企业管理混乱、企业在薪资上做手脚。即便事实是“纯技术事故”,员工也会用结果来判断。
制造业还有一个特殊点:产线群体高度集中,信息传播密度高。若没有清晰的时间表与解释口径,消息会在班组里快速变形,演化为停线、集体投诉、工会/媒体介入等次生事件。这里可以用一句类比来提醒:算薪故障像“连锁反应”,第一张多米诺并不可怕,可怕的是你没有在第二张前把它按住。(本模块仅此一处类比)
二、核心对策——制造业HR的3步应急处理法(月末算薪系统崩溃怎么办的标准解)
应急处理的目标不是把所有复杂项一次算到“完美”,而是在明确边界与证据链的前提下,确保发薪连续性与可解释性。我们把它拆成三步:快速诊断与止损(T+0至T+4h)—影子算薪兜底(T+4至T+24h)—透明沟通与系统闭环(T+24至T+72h)。
1. 第一步——快速诊断与止损(T+0至T+4小时):先把“错误扩散”停下来
这一步解决两件事:你到底遇到了什么类型的崩溃,以及你要不要立刻切换到应急模式。越早止损,越能避免错发与版本混乱。
(1) 故障定级:判断是“算不出”还是“算错了”
建议用“可交付性”而非“技术术语”定级:
- P0(不可交付):系统无法登录/薪资引擎无法运行/关键数据源无法导入,短期无法生成工资单。
- P1(结果不可信):能运行但出现异常波动(如大面积负数、加班费倍率异常、扣款项翻倍),或规则版本疑似被改写。
- P2(局部异常):仅某工厂/某类员工/某薪资项异常,有临时绕开空间。
定级的关键是拿到两个信息:预计恢复时间(ETR)与受影响范围。没有ETR,就按“最坏情境”准备兜底。
(2) 法律熔断:预计影响发薪日,就立刻启动预案
当判断“系统恢复可能超过发薪截止窗口”,HR要做的不是继续等待,而是完成三项熔断动作:
- 冻结自动发放指令:立即与财务对齐,暂停任何“系统生成清单”的批量代发,避免错发后再追缴引发更大争议。
- 启用应急授权链:明确临时审批人(HRD/工厂总/财务负责人),否则兜底算出来也发不出去。
- 把“发薪策略”从一次性转为分层:先保底发放再结算复杂项,而不是死磕一次算全。
反例提醒:有些团队在系统异常时仍坚持“先跑一版发掉”,想着后面再修正。这个动作在制造业最容易踩雷——计件、缺勤扣款、夜班津贴任何一项错了,都可能触发班组集中投诉。
(3) 数据锁定:导出并封存“崩溃时刻快照”,建立唯一事实源
应急状态下最怕“边算边变”。因此必须锁定三类原始数据:
- 人员主数据:当月入离职、调岗、薪资标准变更、银行账号变更清单(以审批通过版本为准)。
- 考勤原始与汇总:原始打卡/门禁记录(可追溯)、班次表、加班审批、请假单据;以及当月考勤汇总(作为计算输入)。
- 计件/补贴依据:产线报工、计件单、质量扣罚单、夜班/高温/岗位津贴依据。
封存的要求是:同一时间戳、同一版本号、可验真。可以采用“导出文件+只读权限+哈希校验(可选)+负责人签字确认”组合方式。做不到哈希也没关系,但要做到“谁导出的、何时导出的、从哪导出的、导出后是否被修改”的基本留痕。
图表1:薪酬应急响应全流程图(T+0至T+72h)
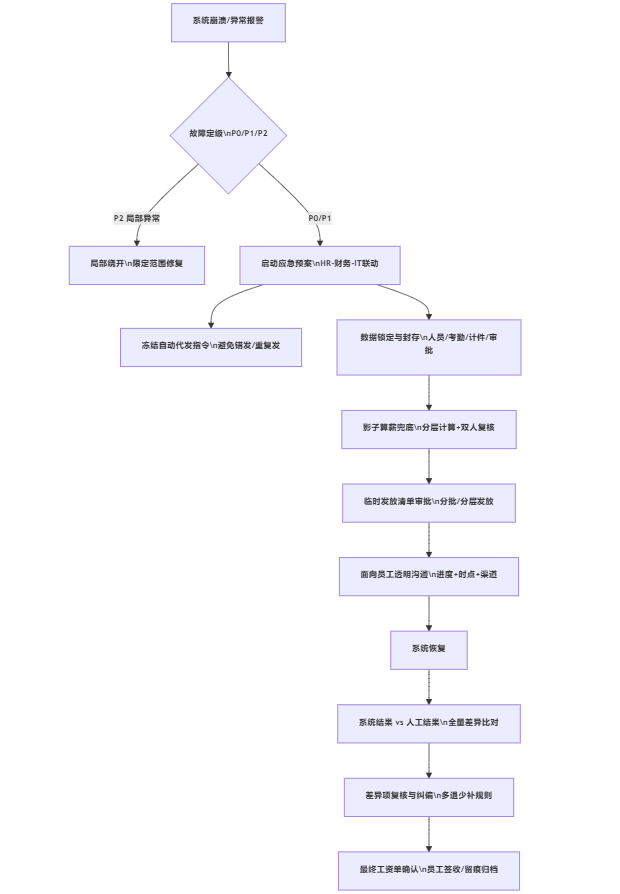
2. 第二步——“影子算薪”兜底执行(T+4至T+24小时):先把可发的发出去
“影子算薪”不是临时拍脑袋,而是一套预先设计的离线算薪包(Excel/本地工具/脚本)与分级策略。其核心原则是:先保障基础工资与核心计件,复杂项延后结算但提前说明。
(1) 分级核算策略:把工资拆成“必须发、可后发、需核对”三类
建议按制造业常见结构分层:
- 必须发(保底层):基本工资/岗位工资、已确认的固定津贴、法定扣款(社保公积金如当月需代扣)、已确认的计件工资(依据齐全)。
- 可后发(结算层):绩效奖金、质量奖惩(需复核)、临时补贴(需确认口径)、加班费(若班次/倍率存在争议)。
- 需核对(争议层):缺勤扣款口径不清、调休/加班互抵规则不一致、计件数据来源冲突的员工。
这样拆分的好处是:你能在24小时内完成“可交付部分”,把风险集中在可控范围。代价是管理复杂度上升,因此必须配合第三步的沟通与签收留痕。
边界条件:若企业工资结构里“浮动项占比极高”(例如纯计件、计件>70%),保底层会更薄,这时更需要在第一步就把计件数据源锁定,并把班组长/工段长纳入复核链路。
(2) 工具降维:启用标准人工算薪包,关键岗位双人复核
应急状态下,工具策略要“能跑、能查、能留痕”,不追求华丽。
- 模板要求:固定列名、固定口径、固定公式区域,避免手工改公式造成不可追溯。
- 复核要求:对产线员工、新入职/离职、调岗、异常考勤(旷工/长病假)人员实行双人复核;对固定月薪且当月无异动者可抽样复核。
- 校验要求:至少做三类快速校验
- 与上月实发对比的环比校验(大幅波动名单)
- 与应出勤/加班审批的逻辑校验(是否出现“无审批却计加班”等)
- 负数/超上限校验(扣款超过应发、加班费异常过高)
这里的关键不是“复核更多”,而是“复核更聚焦”。否则24小时内做全员逐项复核,往往导致全盘延误。
(3) 风险隔离:把“临时发放金额”与“最终结算金额”概念分离
很多工厂应急失败,不是失败在计算,而是失败在“口径不分”。建议在制度与沟通层面明确:
- 临时发放:在系统故障下,为保障员工基本权益而先行支付的金额,依据当下可验证数据计算。
- 最终结算:系统恢复并完成差异比对后形成的最终工资结果,差额按规则补发或在后续周期调整。
注意副作用:若企业后续选择“少发下月扣回”,必须评估员工接受度与当地监管口径;有些地区对“下月扣回”敏感,建议优先采用“次次补发、分次扣回且书面同意”的保守方案,并确保不触碰最低工资与生活保障底线。
3. 第三步——透明沟通与系统闭环(T+24至T+72小时):把工资事件从“猜测”拉回“事实”
第三步的目标是:用可核对的沟通、可复原的差异比对、可留存的签收归档,消除二次事故。很多团队能把钱发出去,却在系统恢复后因为“静默重算”引发更大争议。
(1) 沟通模板:三件事必须说清——事实、计划、渠道
沟通不是公关话术,而是合规证据。建议在24小时内至少发布一次正式通知(公告栏/企业微信/钉钉/短信多渠道),包含:
- 事实说明:发生了什么(系统故障/数据断连)、影响范围(是否影响当月工资核算)、当前处置动作(已启动应急预案)。
- 发放计划:临时发放时点、分批策略(例如先发保底层)、预计完成最终结算时间。
- 员工渠道:咨询入口(热线/工会/HRBP)、异议提交方式与截止时间。
反例提醒:只说“系统维护中,请耐心等待”,不提供时间表与替代方案,最容易诱发“资金紧张”的猜测。
表格2:员工通知公告/邮件中性模板(可直接复用)
| 模块 | 建议表述要点 | 注意事项 |
|---|---|---|
| 事实说明 | 说明故障类型(系统/接口/数据源)、已启动应急预案、已锁定数据版本 | 不推责给员工;避免“保证不影响”这类不可控承诺 |
| 影响评估 | 哪些人员/哪些薪资项可能延后结算(如绩效、部分津贴) | 用“可能/预计”,同时说明依据与边界 |
| 解决方案 | 临时发放金额范围、发放时间、最终结算时间与差额处理规则 | 明确“临时发放≠最终结算”,避免口径混淆 |
| 承诺与致歉 | 对按时发放的努力、对员工影响的致歉、咨询与申诉渠道 | 留存发送记录与时间戳,作为后续证据 |
(2) 差异比对:系统恢复后必须“全量比对”,禁止静默覆盖
系统恢复后常见的坑是:系统自动重算覆盖人工结果,或人工结果被当成“错误数据”回写系统,导致版本混乱。正确做法是:
- 锁定两套结果:人工发放版本、系统恢复版本均只读保留。
- 生成差异清单:按员工维度、项目维度列出差异金额、差异原因初判(缺勤口径、计件数据源、税前税后等)。
- 差异项复核优先级:先处理差异绝对值大的、涉及扣款追缴的、涉及离职员工的、涉及最低工资边界的。
边界条件:若企业人群规模极大(如万人以上工厂),全量逐项人工解释不现实。此时至少要做到“全量差异识别 + 高风险差异逐项复核 + 低风险差异抽样复核”,并把规则写入应急SOP。
(3) 多退少补处理:做到“有规则、有同意、有留痕”
差额处理建议按风险从低到高排序:
- 少发补发:优先安排补发(最少争议),形成补发清单与员工可查询记录。
- 多发不追或分次追:是否追缴取决于金额大小、员工过错与地方口径。若要追缴,建议采用分次扣回,并取得书面确认(或在规章制度/劳动合同中已有明确约定且已公示)。
- 离职人员差额:必须优先闭环,避免后续联系困难;可通过邮件/短信确认与转账留痕。
这里可以用一句提醒作为过渡:应急发薪的终点不是“钱到账”,而是“每个差异都能说清楚”。(本模块不再使用其他类比)
三、长效治理——从“救火”到“防火”的数字化韧性构建
一次应急能否成功,取决于平时是否把“离线可交付”当成制度能力而非临时技巧。制造业要降低月末算薪系统崩溃的冲击,需要把治理拆到影子系统常态化、SLA与选型、薪酬工程能力三个层面。
1. 建立“影子系统”常态化机制:让离线算薪从一次性变成可训练能力
影子系统的价值不是“替代主系统”,而是提供一条可随时切换的第二通道。建议落地两项机制:
- 月度演练(抽样脱系统核算):每月随机抽取例如10%员工样本,按离线模板跑一遍关键字段(出勤、缺勤扣款、计件、固定津贴),与系统结果比对。目的不是抓系统“错”,而是持续校准口径、保留团队手感。
- 离线数据资产包(可用、可查、可追溯):把人员异动审批、班次表、考勤原始导出、计件台账的导出路径与负责人固定下来,形成“每月固定归档动作”。这样一旦系统故障,HR不是临时找数据,而是按清单取用。
不适用场景提示:如果企业的考勤、计件完全依赖单一封闭系统且无导出接口,影子系统很难建立。此时治理优先级应前置到系统选型与接口开放性谈判,否则应急只能靠“班组长口头确认”,风险极高。
2. 优化系统选型与SLA管理:把“技术风险”变成“合同约束”
很多企业吃亏在于:系统上线时只谈功能,不谈连续性指标。制造业建议把以下指标写入SLA或采购验收条件:
- RTO/RPO思路:故障后恢复时间目标(RTO)与数据丢失容忍度(RPO)。即便供应商不直接承诺,也应在内部设定并做演练。
- 关键数据导出能力:人员、考勤汇总、计件明细、薪资计算结果必须可批量导出;最好支持API或标准格式,便于离线兜底。
- 规则版本管理与回滚:算薪规则、口径、倍率变更必须可追踪、可回滚,避免“上线即改口径”导致争议。
- 并发与压力测试:在月末集中算薪前做压力测试,而不是等到发薪窗口再碰运气。
反例提醒:只要求“宕机赔偿”但不要求“数据可导出/可回滚”,对HR帮助有限。赔偿解决不了按时发薪义务,最多弥补部分管理成本。
3. 薪酬工程能力提升:HR从“系统操作”转向“口径治理”
制造业薪酬的核心竞争力,越来越体现在“口径统一与数据治理”。建议从三件事入手:
- 技能升级:至少让薪酬岗位具备数据清洗、异常识别、Excel结构化建模能力;对于共享中心,可引入简单脚本/Power Query来自动化校验,减少纯手工。
- 跨界协同常态化:建立HR—IT—财务的联合应急小组(Incident Response Team),明确故障时的联系人、决策链与升级路径;平时做复盘,避免每次都从“找人”开始。
- 规则与制度前置:把争议高发项(21.75口径、缺勤扣款、调休与加班互抵、计件确认时点)写清、公告并留存签收。系统崩溃时,你的离线计算才能“有法可依”。
图表2:薪酬韧性建设时间轴(0-12个月)

结语
回到开篇问题:月末算薪系统崩溃怎么办?制造业HR要把它当成“交付中断风险”,用止损—兜底—闭环三步法,把技术不确定性转化为流程确定性。真正可控的不是“系统永不宕机”,而是宕机时你仍能按规则交付、按证据解释、按流程留痕。
可直接执行的建议(建议HRD本周就能落地):
- 把发薪窗口前移:在发薪日前至少提前48小时完成“数据锁定点”(人员异动、考勤汇总、计件确认),并形成只读快照与负责人签字。
- 做一份离线算薪包:至少覆盖人员主数据、考勤汇总、计件明细、应发/扣除/校验层,配双人复核与异常名单机制。
- 预设分层发放策略:明确“必须发/可后发/需核对”的工资结构与审批授权,避免宕机时临时改口径。
- 准备一套沟通模板与留痕规则:公告必须包含事实、计划、渠道;发送记录与时间戳要可追溯,差异处理要有员工确认。
- 把SLA谈到关键处:不只谈赔偿,重点谈导出能力、规则版本追踪与回滚、压力测试与恢复目标,让应急不再靠运气。