-

行业资讯
INDUSTRY INFORMATION
【导读】 简历解析工具能显著降低招聘密集型企业的简历处理成本,但它的风险并不来自“用不用”,而来自“怎么用、用到哪一步”。本文以可审计、可复核、可校准为主线,拆解三类高频误区:格式兼容被高估、关键词匹配被滥用、系统输出被当作终局决策,并给出一套从选型到运营的闭环方案,回答招聘密集型企业如何选择简历解析工具?适合HRD、招聘负责人、用工合规负责人及业务面试官共同对齐口径。
招聘密集型企业的矛盾很直接:一边是单岗收件量持续走高,HR团队需要工具把“体力活”压缩到可控范围;另一边是候选人来源越来越多样(外包、校招、转岗、内推、平台投递),简历格式与表述差异放大了算法的不确定性。
2026年的变化在于:不少厂商把大模型能力接入简历解析与匹配,但“模型更聪明”并不自动等于“流程更安全”。从实践看,真正决定ROI的不是采购时的演示分数,而是上线后的字段可信度阈值、人工复核触发条件、以及关键词库与岗位胜任力的持续校准机制。
一、招聘密集型企业使用简历解析工具:效率收益成立,但边界条件更重要
简历解析工具在高并发招聘里确实能提升处理效率,但它适合解决的是“信息结构化与分流”,不适合替代“能力判断与录用风险控制”。
1. 简历解析工具到底做了什么:从非结构化文本到可检索字段
从技术与流程角度看,简历解析工具通常完成三件事:其一,把PDF/Word/图片等材料转为结构化字段(教育、履历、技能、证书等);其二,把字段写入ATS/人才库,便于检索、去重、统计;其三,基于JD或规则进行初筛分流。这里的关键点是——解析的目标是可用字段,不是“对候选人能力做结论”。
对招聘密集型企业而言,解析工具的价值往往体现在两类岗位:
- 标准化岗位(客服、普工、门店、基础运维):字段清晰、门槛可量化,解析结果更容易稳定。
- 批量招聘场景(区域扩张、旺季补员、项目制交付):能把HR从重复录入与初步分拣中解放出来。
不适用的场景也要明确:中高端管理岗、强作品集岗位、以及合规审查要求极高的岗位(涉密、持牌金融关键岗等),解析工具最多作为资料归档与检索工具,不能以“匹配分”替代人工判断,否则成本会以更隐蔽的方式回流(误淘汰、复招、诉讼与雇主品牌损失)。
2. 解析工具在招聘流程中的合理位置:用来分流,不用来定案
招聘密集型企业常见的错误,是把ATS/解析工具放在“决策链条最末端”,让系统输出直接决定进面、发Offer甚至淘汰。更稳妥的做法,是把它放在“流程前半段”,承担分流与提示,而把“拒绝权”保留在人工复核或业务面评之后。
下面用流程图把“合理位置”画清楚:解析工具输出应成为下一步动作的输入,而不是最终判决。
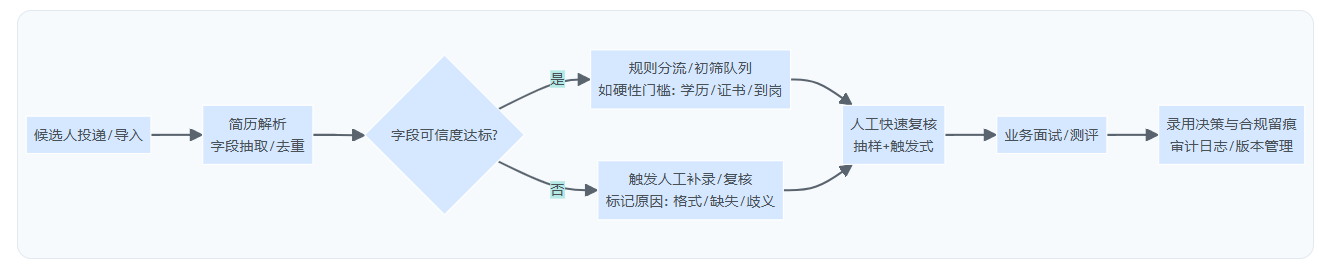
这个流程的要害在两个阈值:
- 字段可信度阈值:决定“能不能进入自动分流”。
- 人工复核触发阈值:决定“哪些必须由人再看一眼”。
只要阈值不存在或不可执行,解析工具就会从“效率工具”滑向“风险放大器”。(本模块到此为后文三大误区铺垫。)
二、误区一:只看演示准确率,忽视真实格式与字段可信度——把“能用”误当“可用”
在招聘密集型企业里,解析工具的最大成本黑洞通常不在采购价,而在上线后不断出现的“异常简历处理工单”与“字段纠错返工”。
1. 真实简历的格式复杂度,决定了解析准确率的上限
供应商演示多基于标准Word或结构化模板,字段齐全、排版单栏、信息位置稳定;但企业真实收到的简历常包含:扫描版PDF、手机截图、双栏排版、页眉页脚、作品集式简历、甚至中英混排证书。
这些格式会带来三类可检查的问题:
- OCR误读:手机号、邮箱、证书编号出现字符替换,导致联系失败或重复候选无法去重。
- 段落错位:多栏排版把公司名与岗位名串行,履历时间线被打乱,年限计算失真。
- 字段缺失:项目经验被解析成“空”,技能栈被塞进“自我评价”,后续检索无法命中。
对招聘密集型企业来说,这些问题的后果不是“少筛到几个候选人”那么简单,而是形成系统性偏差:越是非标经历的人(跨行业转型、非名校但项目强、从一线成长的班组长),越容易被格式与字段问题压到分流链条外。提醒一句:当企业的组织策略需要“多样化供给”时,格式兼容不足会把策略直接抵消。
2. 建立“字段可信度”而非“整体准确率”:让风险可控、可运营
“整体准确率90%”对运营没有指导意义,因为企业真正依赖的是少数关键字段:联系方式、最近两段工作经历、关键证书、到岗城市/期望薪资等。更可操作的方法是把准确率拆成字段可信度矩阵,并对不同岗位设置权重。
表格1给出一个招聘密集型企业可直接复用的字段治理样例(不是越多越好,而是围绕“会影响决策的字段”)。
表格1:字段可信度治理样例(按岗位类型设置阈值)
| 字段类别 | 示例字段 | 高并发基础岗阈值 | 专业/合规岗阈值 | 典型触发动作 |
|---|---|---|---|---|
| 联系字段 | 手机/邮箱 | ≥98% | ≥99% | 低于阈值必须人工复核,否则进入“无法联系”队列 |
| 履历字段 | 最近公司/岗位/起止时间 | ≥90% | ≥95% | 年限不一致或时间断裂>6个月,触发“时间线复核” |
| 资质字段 | 职称/证书/持牌资格 | ≥85% | ≥98% | 合规岗低于阈值直接人工核验原件/编号 |
| 匹配字段 | 技能词/工具栈 | ≥80% | ≥90% | 命中关键硬技能但缺项目锚点,标记“需上下文评估” |
边界条件也要讲清楚:如果企业的简历来源90%以上来自标准模板(例如校招统一简历、内推平台固定表单),阈值可以更激进;反之,若来源高度开放(社会招聘、多平台汇总、猎头简历混合),就必须把人工复核当作制度,而不是“忙的时候看一眼”。
三、误区二:把关键词匹配当能力评估——JD没校准,工具越强误筛越快
关键词匹配本身不是问题,问题在于:很多企业的JD与胜任力模型并未“可解析化”,导致系统只能匹配词面,而无法匹配能力。
1. 为什么“关键词筛选”会误伤:JD、能力模型与候选人表述不在一个坐标系
招聘密集型企业常见现象是:业务部门给的JD偏“口号化”,HR再把它翻译成一串技能词;而候选人的表述又受个人写作习惯影响。于是出现三种错位:
- 同义不同词:JD写“用户增长”,简历写“DAU提升30%/拉新转化”;如果只匹配词面,会把有结果的人筛掉。
- 有词无能:简历堆叠“Python/SQL/机器学习”,但没有任何项目规模、数据量级、指标贡献;系统却因关键词齐全给高分。
- 能力在行为里:管理岗的关键能力往往体现在动词与对象上(推动、协调、预算、交付),而非名词关键词;若不把胜任力拆成可识别的行为锚点,解析工具无从发挥。
这也是为什么同一份简历在不同ATS里会出现巨大分差:工具差异只是一部分,更本质的是企业自己的JD与词库是否“工程化”。
2. 用“能力锚点”改造关键词库:让匹配从词面走向可验证证据
更稳妥的路径,是把岗位胜任力拆成三层:硬门槛、能力锚点、反证信号。硬门槛用于快速分流;能力锚点用于区分“会说”和“做过”;反证信号用于降低误判(例如频繁跳槽、关键项目不可验证等需进一步核查)。
下面用一张思维导图展示“能力锚点”的拆解方式,便于HR与业务共建词库与规则。注意:这里不是追求“更多关键词”,而是追求“更可核验的描述”。
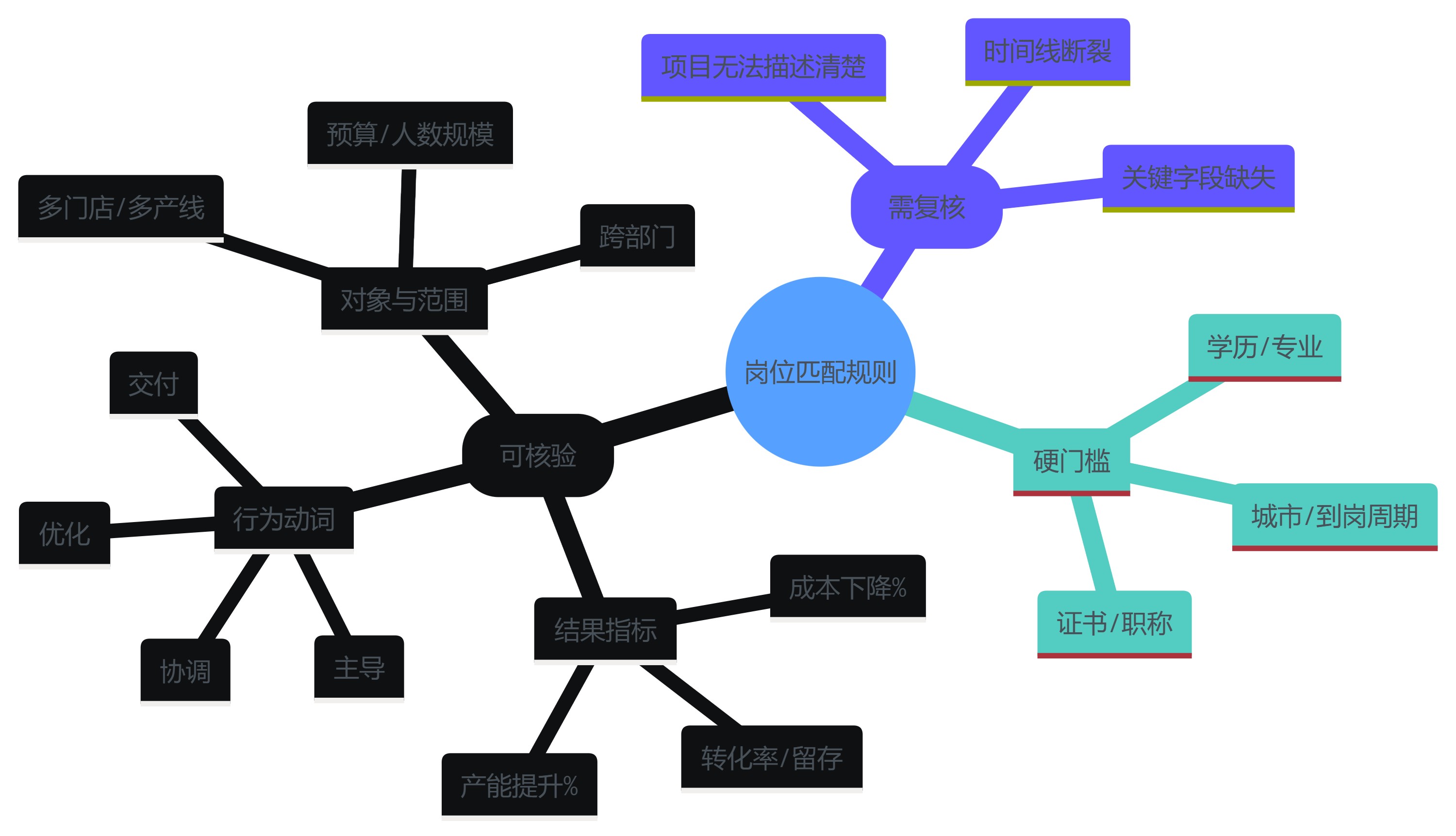
实施要点建议分两步走:
- 第一步:选3个高频岗位做样板(例如门店店长、招商主管、产线班组长),把胜任力拆成锚点,再把锚点映射到可解析字段(动词+对象+结果)。
- 第二步:设定词库更新节奏:至少季度更新一次,触发条件可以是“新业务上线”“岗位画像变化”“面试官反馈误筛率上升”。
反例提示:如果企业招聘的岗位高度同质、且面试官本身不依赖简历进行判断(例如纯计件岗位),过度复杂的能力锚点会增加配置成本,反而不如把精力放到联系方式准确率、到岗意愿与合规材料完整性上。
四、误区三:把ATS当决策终端,缺少人工复核与审计留痕——效率提升的同时放大合规风险
招聘密集型企业往往规模大、层级多、招聘链条长,一旦把系统输出当作“拒绝理由”,风险会以组织级别扩散:候选人申诉、内部审计、劳动监察抽查、以及雇主品牌的负反馈。
1. “自动淘汰”为什么危险:它让错误不可见、不可追溯、不可纠正
从管理角度看,系统性的危险不在于“会不会出错”,而在于错误是否能被发现并纠正。当企业让ATS直接淘汰候选人,常见会出现三种不可控:
- 不可见:被淘汰的人不进入任何人工队列,企业失去校准样本,误筛率只能靠结果倒推。
- 不可追溯:没有保存解析前原件、解析后字段、规则版本号与决策时间戳,审计时无法解释为何淘汰。
- 不可纠正:即使后来发现规则有问题,候选人已流失,补救只能靠更高的招聘成本去“再找一遍”。
如果用一句类比帮助理解:把ATS当终端决策,就像把质检环节取消后只看产量报表——短期数字好看,但风险会在客户投诉时集中爆发。(本模块仅此一处类比,避免修辞堆叠。)
2. 建立“触发式人工复核 + 偏差审计”的双保险机制
可落地的做法,是把人工复核从“抽查”升级为“规则触发”,并把审计做成例行运营,而非事故发生后的补救。
(1)触发式人工复核:哪些情况必须由人再看一眼
建议至少覆盖四类触发器:
- 关键字段缺失:手机号/城市/最近岗位任一为空。
- 解析置信度不足:系统对关键字段的置信度低于阈值(例如<0.9)。
- 岗位高风险:涉合规资质、涉财务权限、或岗位对安全生产负责。
- 异常模式:同一来源渠道在短期内出现大量“字段空/错位”,提示渠道简历格式变化或OCR异常。
(2)偏差审计:不靠感觉,靠分布与离散度
偏差审计不是为了做“价值观宣讲”,而是为了把招聘漏斗的结构性偏差可视化。例如:
- 自动淘汰人群在院校层级、年龄段、性别(若企业依法合规收集)上的分布是否突然变化;
- 某一渠道的通过率是否异常偏低(可能是格式问题,也可能是渠道人群与岗位画像不一致);
- 面试通过但系统评分低的候选人是否持续出现(提示匹配规则落后于业务实际)。
下面用流程图把“复核+审计”机制串起来,便于企业直接写进制度或SOP。
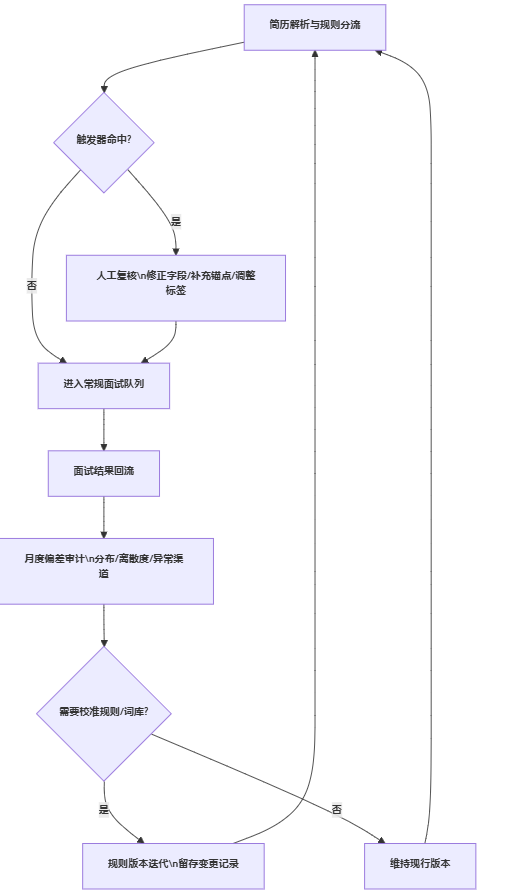
边界条件:若企业招聘节奏极端紧急(例如大型项目临时补员),可以缩短审计周期但不建议取消复核触发器;因为越是紧急,越容易出现“错误规模化”。
五、招聘密集型企业如何选择简历解析工具?用“三段式闭环”把选型从采购动作变成运营能力
回答“招聘密集型企业如何选择简历解析工具?”时,我们更建议把问题拆为三段:上线前验证、上线中治理、上线后运营。这样才能把工具能力转化为组织能力。
1. 上线前:用真实样本压测,而不是用演示简历做决策
很多企业选型失败不是产品不行,而是压测方法失真。可执行的压测建议是:从最近3个月真实简历中抽样(不同渠道、不同格式、不同岗位层级),形成压测包,至少包含:
- 标准Word、平台导出PDF、扫描件、双栏排版、中英混排各一部分;
- 高并发岗位与合规岗位各选2-3个;
- 设定“字段可信度”验收,而不是只看“解析成功率”。
验收时把指标写清楚:例如联系方式字段≥99%、最近岗位与公司≥95%、证书字段(对合规岗)≥98%,并约定“低于阈值的处置方式”(是否支持人工修正回写、是否保留原件与日志等)。这些条款应进入合同附件或验收标准,而不是停留在口头承诺。
2. 上线中:把“规则与词库”纳入版本管理,避免各部门各配一套
招聘密集型企业常见的上线混乱是:不同事业部自己配关键词、自己设门槛,导致同一岗位在不同地区出现不同筛选口径,候选人体验与用工风险同时上升。
更稳妥的治理方式是设立“规则委员会”(不必复杂,但要有责任主体),至少包含HR、业务代表、合规/法务(若涉敏感岗位)。规则管理要做到三件事:
- 版本号:每次修改留存版本与生效范围;
- 变更理由:是业务变化、误筛反馈还是渠道格式变化;
- 回滚机制:发现误筛率上升时可快速回退。
提醒一句:对多地多主体的集团公司,规则治理的难点不是技术,而是组织协同;若没有“谁有权改规则”的制度,系统最终会被当作各自为政的工具箱,反而增加管理成本。
3. 上线后:用“误筛成本”评估ROI,而不是只看HR节省了多少时间
招聘密集型企业更应该关注两类成本:
- 显性成本:HR处理时长、简历录入人力、渠道费用。
- 隐性成本:误淘汰导致的补招、关键岗位空缺损失、候选人申诉与雇主品牌损失、以及不合规操作的整改成本。
建议把ROI指标设计成可对账的口径,例如:
- “异常简历平均处理时长”是否下降;
- “关键岗位到岗周期”是否缩短;
- “面试通过但系统评分低”的比例是否下降(代表规则与业务一致性提高);
- “渠道A的字段缺失率”是否在治理后回落(代表格式兼容与渠道协同有效)。
当企业能用这些指标稳定运营时,解析工具才真正从“买回来的一套系统”变成“可持续改进的流程能力”。
结语
回到开篇问题:招聘密集型企业如何选择简历解析工具?答案不是选一款“最聪明”的工具,而是建立一套让工具输出可被校准、可被复核、可被审计的机制。围绕2026年最常见的三类误区,本文给出5条可直接执行的建议:
- 用真实简历做压测:按渠道与格式抽样,验收看“关键字段可信度阈值”,不要只看演示准确率。
- 把胜任力做成能力锚点:用“行为动词+对象范围+结果指标”改造关键词库,季度更新并有版本记录。
- 设定触发式人工复核:关键字段缺失、置信度不足、合规高风险、异常模式四类触发器必须制度化。
- 建立偏差审计例行机制:用分布与离散度找系统性偏差,让规则迭代有数据依据。
- 用误筛成本衡量ROI:把补招、空缺损失与合规整改纳入评估,避免只算HR省时导致的“假收益”。