-

行业资讯
INDUSTRY INFORMATION
【导读】 HR系统一旦瘫痪,影响的不只是“HR办事效率”,而是发薪、用工合规、组织稳定和外部信用。本文以业务连续性应急预案为主线,面向大型集团CHRO、CIO、共享中心负责人、HRIS团队与内控风控人员,给出一套可执行的“事前分级—事中响应—事后恢复—持续演进”方法。重点回答大型集团HR系统瘫痪怎么办:哪些业务先保、指标如何定、组织如何拉通、技术与流程怎样互为备份。
很多集团对“灾备”并不陌生,但一到真正宕机,现场往往仍是两类失控:其一,技术在修、业务在等,等到月底发薪才发现RTO并不等于“业务可交付”;其二,临时用Excel顶上去,却在数据口径、审批链、权限合规上引出更大的二次风险。2026年的现实是:HR系统已经深度耦合财务、门禁考勤、主数据、OA/流程、银行代发、社保公积金等外部接口,单点故障会被放大为跨域中断。要解决的不是“能不能恢复系统”,而是“中断期间业务是否可控”。
一、理念重塑——从应急管理迈向业务连续性
HR系统瘫痪的处置,不能只靠IT抢修的“救火”,而要以业务为中心重建业务连续性管理(BCM)逻辑:先明确关键业务交付,再倒推组织与技术保障。把“系统恢复”当目标,常常会把“业务损失”留到最后才结算。
1. 概念辨析:应急管理解决当下,业务连续性保证交付
从实践看,很多集团把“应急预案”理解为故障处理SOP:谁接电话、谁重启、谁通知。但这更接近应急管理的“响应动作”,而不是业务连续性强调的“持续交付能力”。
- 应急管理更关注:事件发生后如何快速反应、降低即时损害(例如止损、隔离、抢修、通报)。
- 业务连续性管理(BCM)更关注:在既定可接受的时间与数据损失范围内,关键业务如何不停摆或快速恢复(例如发薪不延、用工不违规、关键审批不断档)。
两者不是二选一,而是层级关系:应急管理是BCM的一段“冲刺”,BCM则把冲刺前的训练、装备、路线都准备好。对大型集团而言,尤其要警惕一种反例:系统当天恢复了,但由于数据回滚、接口未对齐、审批链断裂,导致补发薪、补缴社保、劳动争议与审计整改在随后数周集中爆发——这类“滞后损失”往往比停机时长更贵。提醒一句:如果你的预案只写到“系统恢复”,基本等同于没有覆盖HR业务连续性。
表格1:应急管理与业务连续性管理对比
| 对比维度 | 应急管理 | 业务连续性管理(BCM/BCMS) |
|---|---|---|
| 目标 | 快速响应、控制事态 | 关键业务持续交付或按指标恢复 |
| 时间跨度 | 以小时/天为主 | 覆盖事前-事中-事后全周期、持续改进 |
| 关注对象 | 事件处置动作、现场协同 | 业务影响、优先级、资源与能力底座 |
| 关键产出 | 处置流程、通知机制 | BIA、RTO/RPO、连续性策略、演练与审计证据 |
| 主要责任 | 多由IT/安服牵头 | CHRO+CIO+内控风控+业务共同责任 |
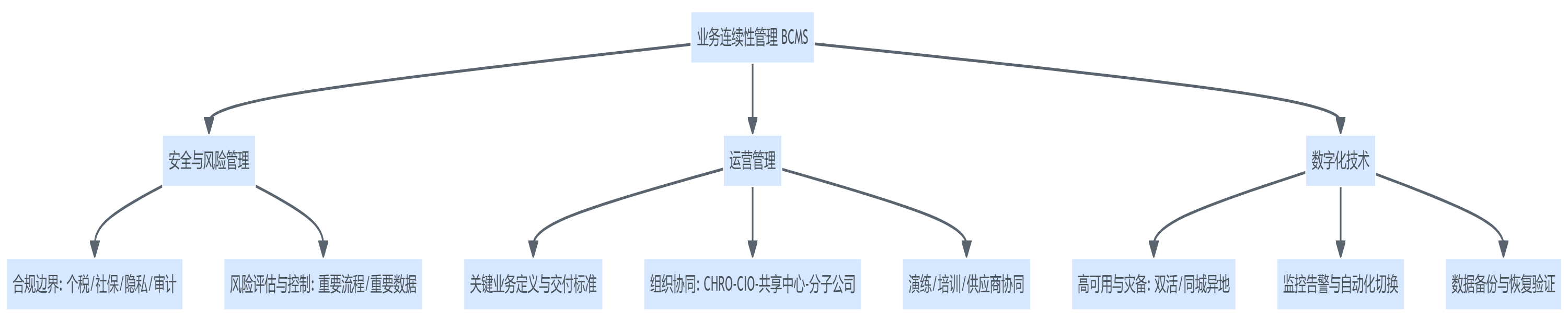
2. 三大支柱:风险与安全、运营管理、数字化技术必须同频
把HR系统瘫痪当成单纯技术故障,会忽略两个“决定能不能扛住”的变量:运营机制与风险边界。我们更建议用“三大支柱”理解集团级HR连续性:
- 安全与风险管理:界定哪些数据/流程不能以“临时Excel”替代,哪些替代会触发合规风险(个税、社保、劳动用工、隐私与重要数据、审计追踪)。
- 运营管理:把“谁做什么、做到什么程度算交付”写清楚,尤其是共享中心、分子公司HR、财务、法务、工会、外包服务商之间的协作边界。
- 数字化技术:高可用、灾备、双活、监控与自动化切换,决定RTO/RPO是否可达;但技术指标必须映射到业务指标,否则就是“指标很美、交付不可用”。
这里有一个常见误区:技术团队把RTO定义为“服务器恢复时间”,HR把RTO理解为“员工能正常打卡/提交报销/看到工资条”。两者差了一个“端到端链路”。把这条链路画出来,才是集团级预案的起点。
图表1:业务连续性三大支柱结构图
3. 标准与监管框架:用ISO 22301把“可控”落到可审计
集团级业务连续性,最终要能经得起三类检查:内控审计、外部监管/检查、重大事件复盘。ISO 22301提供的价值不在“拿证”,而在于把连续性能力拆成可验证的管理要素:范围、角色职责、BIA、策略、计划、演练、持续改进。
同时,很多行业监管(尤其金融等)对连续性建设有更细的要求:例如关键业务识别、恢复能力证明、演练频率、证据留存。即使你不在强监管行业,也建议借鉴其“证据链”思路:预案是否可执行,不靠口头承诺,而靠演练记录、指标达成、问题关闭率来证明。提醒一句:如果集团内部对“谁有权宣布进入应急状态”“谁能批准业务降级”没有制度授权,宕机时的指挥链会天然失效。
二、事前准备——风险评估与资源底座
在HR系统瘫痪这类事件里,真正决定损失上限的往往不是故障当天的操作,而是事前是否完成BIA、设定RTO/RPO并准备好可替代流程与技术底座。越是大型集团,越不能指望“临场发挥”。
1. 业务影响分析(BIA):先分级,再谈恢复
BIA的核心不是写一份报告,而是把“业务重要性”转化为可操作的三个结果:优先级、指标、替代方案。建议以“业务场景”而不是“系统模块”做识别,因为同一模块在不同时间窗口的重要性不同(例如考勤在月末、发薪前的重要性陡增)。
可参考的集团HR关键业务清单(按常见影响链路):
- 发薪链路:薪资核算→审批→银行代发→个税申报→工资条发布→差异处理
- 用工合规链路:入转调离→合同/续签→社保公积金增减员→工时与加班→劳动争议证据
- 组织主数据链路:组织架构→岗位/编制→人员主数据→权限与成本中心→下游系统同步
- 管理与激励链路:绩效周期→奖金核算→股权/长期激励→预算与成本归集
- 招聘交付链路:Offer→背调→入职→账号与权限开通(与ITSM/门禁联动)
BIA落地时,需要把RTO/RPO从“技术词”翻译成“业务可接受范围”:
- RTO(恢复时间目标):业务最多允许中断多久(例如“发薪链路必须在T+0完成银行代发”)。
- RPO(恢复点目标):最多允许丢失多少数据(例如“入转调离不能丢单,RPO应接近0”)。
表格2:HR业务分级策略与RTO/RPO示例(可按集团实际改写)
| HR业务场景 | 关键等级 | 建议RTO | 建议RPO | 备用方案(示例) | 主要风险点 |
|---|---|---|---|---|---|
| 薪酬核算与代发 | P0 | 1-4小时(发薪日更短) | 接近0 | 冻结版本数据导出+手工校验+银行模板代发 | 口径错、重复发/漏发、审计追踪缺失 |
| 社保公积金增减员 | P0/P1 | 4-24小时 | 接近0 | 临时台账+平台申报窗口预留 | 逾期罚款、劳动争议 |
| 入职办理与合同签署 | P1 | 24小时 | 0-少量 | 线下表单+电子签备通道 | 用工合规、信息泄露 |
| 考勤与工时 | P1 | 24-48小时 | 可容忍少量 | 门禁/考勤机本地数据留存+后补录 | 加班争议、薪资误差 |
| 招聘流程(非关键岗位) | P2 | 3-5天 | 可容忍 | 邮件/表单流转 | 体验下降、Offer流失 |
| 培训学习/员工自助查询 | P3 | 1-2周 | 可容忍 | 通知公告替代 | 影响较小但会放大舆情 |
边界条件也要写清楚:例如“手工发薪”并非总可行——当你存在多法人、多币种、多地个税口径、复杂津补贴与扣款规则时,手工核算会把风险从“系统不可用”转成“财务与合规不可控”。因此备用方案必须分层:能手工就手工,不能手工就必须依赖灾备系统或只读快照。提醒一句:BIA的难点不是识别P0,而是让业务负责人承认“可接受的中断与数据损失”,并在预算上为此买单。
2. 技术架构韧性:SDS/HCI、双活与“端到端链路”的现实差距
技术底座建设的关键,不在于采购某个“更高级”的架构名词,而在于它是否支撑你在BIA里承诺的RTO/RPO,并覆盖完整链路:应用、数据库、存储、网络、身份认证、接口、中间件、日志与监控。
常见的三类能力组合(按成熟度递进):
- 备份 + 冷备恢复:成本相对低,但RTO通常在小时到天级,且恢复过程对人员依赖大;适用于P2/P3或非发薪窗口。
- 同城双中心 + 热备/主备切换:RTO可降至分钟到小时,RPO可做小;但需要演练验证“切过去业务真的能跑”。
- 双活数据中心(同城/异地):追求更接近0的中断与数据丢失,但对应用改造、数据一致性、网络时延、运维能力要求高,成本与复杂度也更高。
SDS(软件定义存储)与HCI(超融合)在集团场景的价值,往往体现在两点:
- 缩短恢复链路:把存储、计算、虚拟化、备份编排更紧密地整合,减少“拼装式恢复”的人肉步骤。
- 提升可验证性:可以更标准化地做快照、复制、回滚与演练环境拉起。
但也要直面反例:如果你的HR系统是高度定制的单体应用、强状态会话、接口耦合严重,即便底座做了双活,也可能在切换后出现“系统可访问但业务不可用”(例如SSO失效、消息队列堆积、接口回调重放导致重复入账)。因此技术方案的评审必须加入业务侧验收:以“发一笔薪、走一次入职、同步一次主数据”为验收脚本,而不是只看CPU、主机存活。提醒一句:技术建设的最大浪费,是只验证“能切换”,不验证“切换后能交付”。
3. 预案制定与演练:把“人、流程、证据”写成可执行的剧本
预案不是一份文档,而是一套“可启动、可协同、可追责、可复盘”的剧本。建议至少包含以下要素(且要在集团层面统一模板):
- 触发条件:什么情况进入应急(例如“发薪窗口核心链路不可用超过15分钟”)。
- 分级机制:P0/P1/P2如何定义,对应的响应时限与授权。
- 组织与角色:建议采用CHRO+CIO双组长(或业务负责人+技术负责人)模式,确保“业务降级决策”有人拍板,“技术切换动作”有人负责。
- 通信机制:内部公告模板、关键联系人清单、外部机构(银行、社保平台、服务商)沟通口径。
- 替代流程:手工发薪/线下审批/数据导出与冻结规则、权限与留痕要求。
- 演练计划:桌面推演、局部切换、全链路演练各自频率;演练必须产出问题清单与关闭证据。
演练要避免“只演技术、不演业务”。真正有效的演练,至少包含一个业务压力点:例如在发薪日前48小时模拟中断,要求共享中心在限定时间内完成“数据冻结—核算—审批—代发—反馈处理”的闭环,并输出审计可用的留痕。提醒一句:没有演练记录与问题闭环,预案在审计视角里等同于未建立。
三、事中响应——基于四阶段模型的应急实操
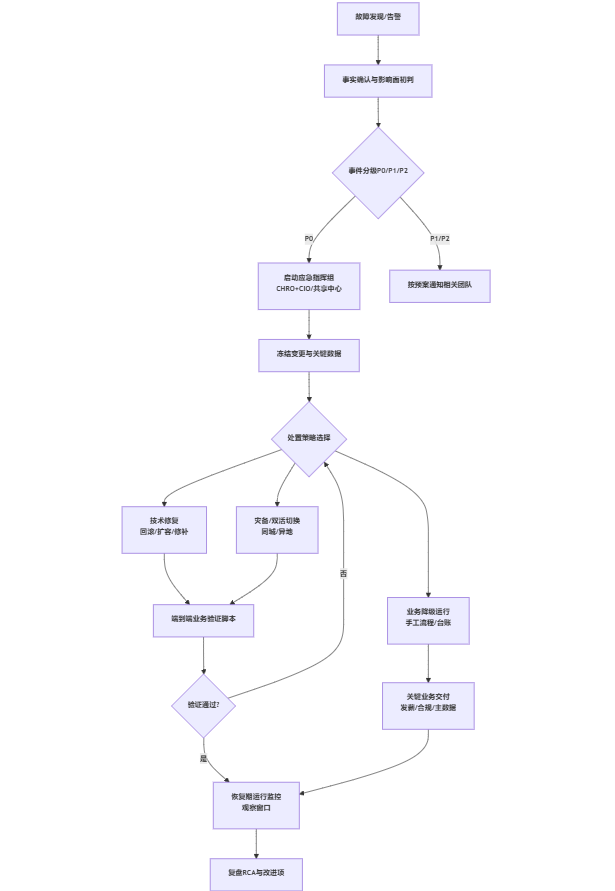
当系统真的瘫痪,最怕的不是忙,而是忙而无序:重复沟通、反复猜测、无授权决策、无边界扩散。用“减缓—准备—响应—恢复”的四阶段模型,可以把混乱压缩到可控范围内;其中“响应阶段”的黄金30分钟,决定了后续一天的工作量。
1. 减缓与准备:监控预警 + 指挥体系先跑起来
这里的“减缓”不是事发后才做,而是事发那一刻先把损害扩散控制住;“准备”则是立即进入战时组织状态。
建议的第一步不是开会,而是同步完成三件事:
- 确认事实:是应用不可用、数据库异常、网络故障、SSO/权限故障,还是第三方接口瘫痪?用监控与日志说话,避免“口口相传”的误判。
- 定级与宣布:由授权人(通常是应急指挥组长或其授权代理)宣布事件等级,启动对应预案。
- 冻结变更:立即冻结HR系统相关变更发布与配置调整(除非变更本身是修复方案的一部分),防止“修复叠加新故障”。
组织上建议采用“一条指挥链、两条作战线”:
- 指挥链:CHRO/CIO/共享中心负责人进入应急群(明确主指挥与记录官)。
- 技术线:HRIS/基础架构/安全/网络/数据库/供应商。
- 业务线:薪酬、SSC、分子公司HRBP、财务、法务合规、沟通负责人。
如果你只能记住一个方法:把“讨论原因”与“保证交付”分开并行。技术线可以继续做根因定位,但业务线必须立刻推进“业务降级是否启动、哪些链路先保”。提醒一句:在P0事件里,根因未明不妨碍先止损。
2. 响应与处置:大型集团HR系统瘫痪怎么办(黄金30分钟清单)
这部分直接回答检索问题:大型集团HR系统瘫痪怎么办。我们建议把行动拆成“技术侧动作”和“业务侧动作”,并用时间盒约束。
(1)0-10分钟:止损与影响面界定
- 技术侧:快速健康检查(应用/DB/存储/网络/认证/中间件);必要时隔离异常节点,防止扩散。
- 业务侧:确认是否处在关键窗口(发薪、报税、社保申报、集中入职日);拉出P0业务Owner进入指挥群。
- 决策点:是否触发“业务降级模式”(例如启动手工发薪准备)。
(2)10-30分钟:路径选择——修复、切换、降级三选一或组合
- 修复优先:适用于单点故障且预计在RTO内修复(例如某服务崩溃可快速回滚)。
- 切换优先:适用于基础设施级故障或预计修复超时(例如主中心存储/数据库故障),直接切至灾备/双活中心。
- 降级优先:适用于切换也无法保证端到端链路(例如外部银行接口故障、SSO体系故障),必须启动线下替代交付。
这三者常常要组合:例如先切换保障系统可用,同时启动业务降级确保发薪不受影响。
(3)30分钟后:按链路交付与风险控制
- 发薪链路:
- 冻结数据版本(明确冻结时点、冻结范围、冻结人)。
- 导出核算数据并进行双人复核(防止导出缺字段、口径漂移)。
- 与财务确认代发资金路径与审批替代(必要时走应急审批)。
- 出具员工沟通口径:发薪是否延迟、工资条何时补发、差异如何申诉。
- 用工合规链路:
- 入转调离先走“登记后补录”机制,保留证据(纸质/电子签/邮件)并控制权限。
- 社保申报窗口若临近截止,优先保障申报数据与凭证生成。
- 主数据链路:
- 禁止在多个台账同时维护同一人主数据,必须指定唯一台账与维护人。
- 对下游系统同步采取“暂停自动同步—恢复后补偿”的策略,避免产生大量脏数据。
这里必须强调一个合规底线:临时Excel不等于可以随便传。应急期间也要做到最小权限、加密传输、留痕与存储生命周期管理,否则系统恢复后,你会面对新的信息安全事件。提醒一句:降级运行不是“降低要求”,而是“用更少的系统能力维持同样的合规边界”。
图表2:HR系统瘫痪应急响应全流程
3. 沟通与协同:把“信息不对称”当作风险源来管理
宕机期间,沟通不是“发通知”,而是风险控制。建议建立“三层沟通”:
- 指挥层沟通(每30-60分钟一次):只讨论三件事——当前状态、下一步决策、风险与资源需求,避免技术细节淹没决策。
- 业务方沟通(按链路):发薪、社保、入职等关键Owner拿到明确“可交付承诺”(例如“代发不延迟/延迟到何时/差异处理通道”)。
- 全员沟通:越简短越好,核心是确定性:发生了什么、影响什么、员工要做什么、不用做什么、下一次更新时间。
外部协同同样关键:银行代发、社保平台、外包服务商、云厂商/软件供应商都需要有“应急联系人与升级路径”。反例是:供应商工单按普通优先级排队,集团内部却以P0在熬夜,最终卡在“对方不升级”。因此预案里必须写明:重大事件的SLA、升级人、备援通道。提醒一句:沟通的目标不是解释技术原因,而是让每个角色知道下一步怎么做、由谁承担。
图表3:四阶段模型时间轴与关键动作

四、事后恢复与未来演进——构建2026数字化韧性
系统恢复并不等于事件结束。对大型集团而言,真正的“尾声”是:数据是否一致、补偿动作是否完成、预案是否更新、组织是否吸取教训。否则下一次同类故障只会更快重演。
1. 复盘与改进:恢复后的第一要务是数据完整性与可追溯
恢复阶段建议按“三步走”:
- 业务验收优先于技术验收:用端到端脚本验收发薪、入职、社保申报、主数据同步等关键链路,确保“可交付”。
- 数据校验与差异补偿:对比宕机前后关键表/关键接口消息,确认是否存在回滚、重复写入、漏写;对差异采取补偿任务(补发、补缴、补录)并留存证据。
- 根因分析(RCA)+整改闭环:RCA要区分触发原因、扩散原因、检测失败原因、响应迟缓原因四类,否则只会得到“服务器坏了”这种无效结论。
建议把复盘输出固定为四类资产,方便内控审计与持续改进:
- 时间线(谁在何时做了何事)
- 决策记录(为什么选择修复/切换/降级)
- 指标达成(实际RTO/RPO、业务损失与补偿量)
- 整改清单(责任人、完成时间、验证方式)
常见副作用提醒:很多团队复盘会陷入“追责会”,导致下次事件大家更倾向于隐瞒问题、延迟上报。更有效的做法是把追责与改进分层:对流程违规、越权操作可以追责;对能力缺口(监控盲区、容量不足、预案不全)则用预算与项目解决。提醒一句:复盘要追“机制”,不要只追“人”。
2. 组织韧性提升:把远程办公能力、心理安抚与岗位备份纳入预案
业务连续性不只是系统韧性,还包括组织韧性。2026年的集团组织更分布式:共享中心集中、分子公司分散、外包与远程协作常态化。一旦宕机,人的因素会被放大:
- 岗位备份:发薪、个税、社保等关键岗位必须有AB角与交叉培训,否则一旦关键人员请假或同时被占用,降级流程也跑不动。
- 远程办公与替代工作区(WAR):当事件伴随办公楼断网/断电/不可进入时,预案要能切到远程处理(含VPN/零信任接入、授权审批、紧急通讯)。
- 员工情绪与信任管理:发薪相关事件最敏感,沟通要以确定性与可兑现承诺为主;对投诉通道与差异处理要给出明确SLA。
这里可以做一个非常实用的制度化动作:把“发薪承诺”写成集团级服务目录(类似IT服务目录),明确责任人、交付标准、异常窗口与补偿规则。它不是口号,而是一份能在宕机时直接引用的“交付契约”。提醒一句:组织韧性建设往往不贵,贵在长期不做。
3. 2026技术展望:从“能恢复”走向“可预防、可自愈”
未来趋势很明确:连续性能力会从“灾备工程”走向“韧性工程”。但要避免把“AI自愈”当万能药,建议聚焦三类更现实的演进路径:
- 可观测性(Observability)补齐:把关键链路的指标(接口成功率、消息堆积、关键批处理耗时、登录成功率)与业务窗口(发薪日、申报截止日)绑定告警策略,让告警能直接指向业务影响。
- 自动化编排:把切换、回滚、扩容、降级开关尽量脚本化、平台化,减少“人肉操作”的不确定性;但自动化必须有审批与回滚机制,避免自动化扩大事故。
- 云原生与微服务的“可隔离”能力:将单体故障隔离在局部服务,配合熔断、限流与灰度发布,降低全站瘫痪概率。反例是:服务拆得很碎但没有治理(链路追踪、统一鉴权、配置中心),故障定位反而更慢。
技术演进的落脚点仍然是业务:你要先能回答“哪些链路必须接近0中断、哪些链路可容忍延迟”,才知道该投入双活、该投入自动化,还是先把BIA与演练补齐。提醒一句:技术先进性不等于连续性能力,连续性能力取决于“指标可达+链路可验+组织可动”。
结语
回到开篇问题:大型集团HR系统瘫痪怎么办?答案不是某个工具或某个团队的“单点能力”,而是一套以业务连续性应急预案为核心的系统工程:先分清关键业务与指标,再准备可验证的技术底座与可执行的降级流程,最后用演练与复盘把能力固化成组织习惯。
给出4条可直接落地的行动建议(可作为集团2026年度专项):
- 立刻做一次HR全链路BIA:以“发薪、用工合规、主数据同步”为三条主线,明确P0/P1清单与对应RTO/RPO,并由业务负责人签字确认。
- 把预案写成“剧本”而不是“制度”:补齐触发条件、授权边界、指挥链、沟通模板、降级流程与证据留存要求,并将供应商升级路径写入合同或补充协议。
- 每半年做一次端到端演练:至少覆盖一次“发薪窗口宕机”情景,演练要输出指标达成与问题关闭证据,纳入内控审计。
- 用可观测性与自动化缩短不确定性:把业务窗口绑定告警,把切换/回滚/降级开关平台化,但所有自动化动作必须可审批、可回滚、可审计。