-

行业资讯
INDUSTRY INFORMATION
【导读】 快速扩张期的科技公司,最怕的不是“系统偶尔卡”,而是关键人事流程在关键时点失灵:算薪延迟、入职无法办理、组织架构变更引发权限错乱。本文从人才战略系统售后服务体系出发,用5个可落地的SLA指标,把“服务承诺”转化为“业务连续性保障能力”。适合HRBP负责人、HRSSC/COE负责人、数字化/HRIT团队与采购评审人员,尤其关注“快速扩张的科技公司如何用5个SLA指标保障业务连续性?”这一现实问题的读者。文章价值在于给出一套指标—机制—运营闭环,既能写进合同与验收,也能用于日常治理与复盘。
扩张期的人力资源系统,表面上是“工具选型与上线”,实质上是组织运行方式的重构:流程被重新定义、权限被重新分配、数据开始成为管理依据。现实矛盾也往往出现在这里——业务线追求速度与规模,HR体系却常以“经验驱动 + 临时响应”支撑。只要组织增速超过服务能力的爬坡速度,售后服务就会从“问题处理”演变为“连续性风险”。
从实践看,SLA(服务等级协议)并不只是运维团队的KPI,它是跨部门协作的契约:什么问题算“业务中断”,谁来判定优先级,多久响应、多久恢复,恢复到什么状态算达标。把这些说清楚,是扩张期公司避免“关键月份翻车”的第一步。
一、扩张期的隐形危机——为何传统HR运维模式失效?
扩张越快,越需要把“靠人扛”的售后服务,升级为“靠规则与数据驱动”的人才战略系统售后服务体系;否则,故障不是偶发事件,而会变成周期性风险。
1. 业务连续性的脆弱点
在不少科技公司,人才战略系统承载的不仅是人事信息,更是“业务动作的执行链”:招聘推进、Offer发放、入职建档、试用转正、调岗调薪、绩效校准、算薪发薪、社保个税、离职结算。扩张期这些动作高频发生,任何一个环节的系统不可用或数据异常,都可能在短时间内放大为业务停摆。
典型脆弱点通常集中在三类时点:
- 月度/季度关键节点:算薪、个税申报、社保增减员、绩效截止日。此时系统负载上升、操作集中,且容错空间极小。延迟几小时可能意味着财务对账推迟、员工投诉增加,进而影响用工稳定。
- 组织结构频繁调整期:新事业部设立、并购整合、区域拆分。组织架构、岗位序列、审批链与权限一并变化,最常见的事故不是“系统宕机”,而是权限与流程配置错误导致业务无法推进。
- 大规模入离职波峰:校招入职季、项目裁撤、合同到期集中续签。数据写入与关联对象(合同、薪资、账户、权限)数量激增,异常更容易出现。
这些风险之所以隐蔽,是因为在低速增长期,靠人工补救能“遮住问题”:HR可以手工导入、财务可临时发放、IT可加班修复。但当组织从数百人冲到数千人,补救成本呈非线性上升,甚至会出现“补救本身造成二次事故”(例如手工更改导致数据不一致、版本冲突)。
为便于把“系统问题”翻译成“业务连续性语言”,我们用一张时序图把影响链路拆开,便于在后续定义SLA时划清边界与优先级。
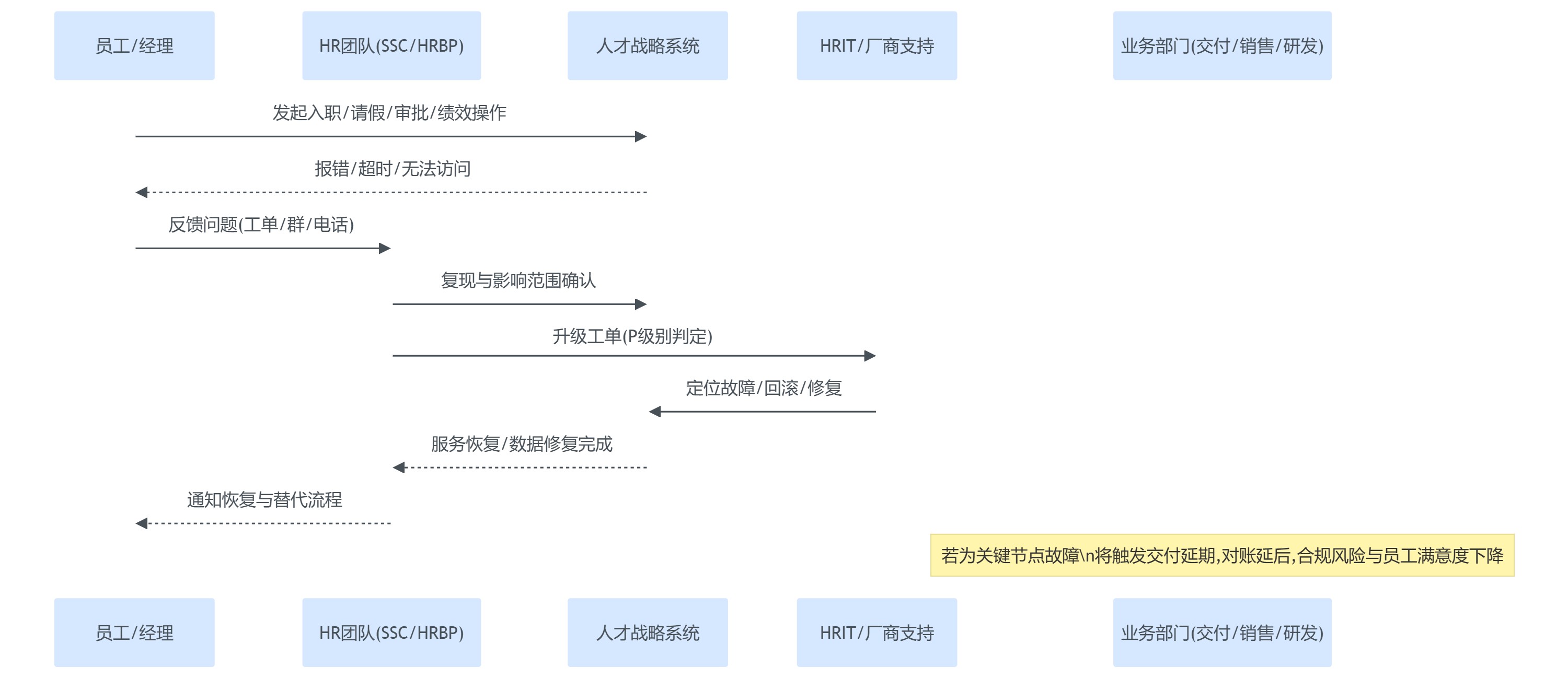
提醒:如果公司无法在“发现—分级—响应—恢复”的每一步形成可衡量承诺,那么所谓“保障连续性”往往只停留在口号层面。
2. 从“被动救火”到“主动防火”的转型
传统HR运维常见模式是:出了问题再协调资源处理,依赖个人经验判断优先级。这种模式在扩张期会出现三个结构性缺陷:
- 优先级争夺失控:业务线各自认为自己的问题最紧急,HR/IT被迫“谁声音大先处理”。结果是关键流程未必优先,资源被低价值诉求消耗。
- 响应口径不一致:同一类故障在不同人手里得到不同处理方式;对外沟通随意,导致业务对HR/厂商的信任持续折损。
- 复盘不成体系:故障处理结束就算“过去了”,没有清晰根因分类与改进动作沉淀;同一问题在下个关键节点复发。
SLA的作用,就是把“优先级争夺”和“口径不一致”转化为可执行的规则:什么算P1、谁负责确认、多久必须响应、多久必须恢复、恢复到何种状态算完成,并且把过程数据记录下来用于复盘。可以把它理解为扩张期的“服务仪表盘”——速度提升时,必须同步提升可控性(本模块仅此一处类比)。
3. SLA在人才战略中的定位
在人才战略语境下,SLA不是单纯运维指标,而是HR向业务交付能力的一部分。原因在于人才战略并不只关心“有没有系统”,更关心三类结果:
- 人才供给是否可预测:招聘、入职、调配能否按计划完成。
- 组织运行是否可控:组织架构、权限、审批链调整是否稳定。
- 员工体验是否可持续:关键服务在扩张中不塌陷,员工对组织的信任不被反复透支。
因此,SLA应当同时对“系统可用”“数据可恢复”“流程可按时完成”“问题可快速修复”“变更可控”给出承诺。只盯“系统在线率”,往往会出现反例:系统99.9%在线,但组织变更配置出错导致大批审批挂起,业务照样停。
二、核心模型——保障业务连续性的5个关键SLA指标
要把业务连续性真正管起来,指标不能多而散,而要覆盖关键风险面:在线、可恢复、流程时效、故障修复、变更成功率。这5个SLA指标的共同特点是:可定义、可计算、可写入合同、可用于日常运营。
1. 系统可用性SLA—— 业务在线的底线(快速扩张的科技公司如何用5个SLA指标保障业务连续性?)
定义与计算口径
系统可用性通常以周期内“可正常提供服务的时间占比”衡量。关键在于先把“可用”定义清楚:能登录不等于可用,至少应包括关键页面可访问、核心接口可调用、关键流程可提交并产生正确状态。
- 常见计算口径:
可用性 =(统计周期总时长 - 不可用时长)/ 统计周期总时长 - 需要提前约定:不可用时长是否包含计划内维护窗口、是否区分核心模块与非核心模块、是否以监控探针还是用户体验为准。
为什么它直接关系业务连续性
扩张期的系统使用人群从“HR少数人”变成“全员+经理层+跨地区管理者”。当系统不可用发生在关键节点,替代流程往往意味着大量人工沟通与数据补录,且会制造后续对账成本。更现实的问题是:一旦员工对系统稳定性失去信任,使用行为会回退到线下,数据质量随之下降,人才决策就会失去依据。
落地建议与边界条件
- 建议把可用性拆分为两层:
1)平台可用性(登录、首页、基础服务)
2)关键流程可用性(入职、算薪、审批、绩效提交等)
这样能避免“平台在线但业务流程不可用”的统计盲区。 - 边界条件:如果企业存在大量离线审批、纸质签批或非系统化环节,可用性提升并不会立刻转化为业务连续性提升;此时需并行做流程线上化与权限治理。
提醒:可用性指标设得再高,也替代不了对“关键流程”的单独SLA约束,后者决定真实业务是否能跑。
2. 数据安全与恢复SLA(RPO/RTO)—— 组织资产的保险箱
定义:RPO与RTO分别管“丢多少”和“停多久”
- RPO(恢复点目标):可接受的数据丢失上限,通常以时间衡量(例如“最多丢失最近15分钟数据”)。
- RTO(恢复时间目标):从故障发生到恢复服务所需的最长时间(例如“2小时内恢复可用”)。
在人力资源系统中,数据不仅是管理资产,很多还是合规与履约数据:劳动合同、薪资、个税申报、社保基数、考勤记录等。RPO/RTO没有约定清楚,遇到灾难性故障时会出现三类“无法谈判的成本”:
- 数据无法完整恢复,补录成本巨大且难以校验;
- 工资延迟发放引发投诉与劳动争议风险;
- 关键人事凭证缺失造成审计/合规压力。
机制:恢复能力来自“架构与演练”,不是写在纸面上
RPO/RTO的达成依赖备份策略、异地容灾、数据库复制、恢复演练,以及恢复后数据一致性校验。很多公司只在合同里写数值,但没要求“演练频率与验收方式”,最终变成不可验证承诺。
实施要点与反例提示
- 实施要点:在SLA里写明
- 备份频率与保留周期
- 恢复演练频率(例如季度/半年)与演练报告输出
- 恢复验收标准(核心表、核心流程、关键报表)
- 反例提示:若公司采用多系统拼装(招聘、考勤、薪资各一套),只约定单系统RPO/RTO并不足够;需要额外约束跨系统数据同步的恢复顺序与一致性校验,否则“系统恢复了,但数据对不上”同样会中断业务。
提醒:把RPO/RTO写进合同只是开始,真正的成本差异来自演练与验收是否做到了可重复。
3. 关键流程响应SLA—— 人才供给的加速器
定义:用“流程完成时效”替代“感觉很快”
扩张期业务最在意的是:新员工何时入职可用、关键岗位何时到岗、组织调整何时生效。仅靠工单响应并不能回答这些问题,所以需要把SLA直接落在关键流程上,例如:
- 招聘环节:Offer审批完成时效、Offer发放时效、背调结果回传时效
- 入职环节:入职材料校验时效、账号/权限开通时效、试用期流程触发时效
- 薪酬环节:月度算薪出结果时效、异常校验完成时效、发薪前冻结点时效
- 组织与权限:组织架构变更生效时效、权限变更生效时效、审批链更新时效
这里的关键不是把所有流程都纳入SLA,而是找出对业务连续性“有断点效应”的流程:一旦卡住就无法继续推进的那几个。
为什么它是扩张期的关键指标
快速扩张的组织,本质上是在提高“人才流入速度”和“组织变更频率”。流程响应SLA能够把这些变化变成可预测的节奏:业务能按节奏排期,HR能按节奏配置人手,IT/厂商能按节奏安排变更窗口。
落地方式:从端到端拆为可度量节点
建议用“端到端流程SLA + 关键节点SLA”两层结构:
- 端到端:例如“从提交入职到完成账号开通≤X小时/天”
- 关键节点:例如“材料校验≤4小时”“权限开通≤2小时”
边界条件:流程时效会受到“业务方配合度”的影响(如经理不审批、候选人材料不齐)。因此SLA应区分:系统/服务方可控部分与业务方责任部分,并约定“暂停计时”规则,否则会引发扯皮。
提醒:流程响应SLA若不配套“责任分界与暂停计时”,很容易在跨部门协作中失真。
4. 服务请求解决SLA(MTTR)—— 用户体验的稳定器
定义:用MTTR把“修得快”量化
MTTR(平均修复时间)常用于衡量故障从确认到修复的平均耗时。扩张期更建议采用“按故障等级设定响应与解决时限”的方式,因为不同故障的业务影响差异巨大:
- P1:核心业务中断(例如算薪无法运行、全员无法登录)
- P2:关键功能受损但有替代方案
- P3:局部影响或低频影响
- P4:咨询类、优化类需求
在SLA中通常需要同时写明:
- 首次响应时间(多久有人接单并开始处理)
- 解决/恢复时间(多久恢复服务或提供可行替代方案)
- 升级机制(多久未恢复自动升级到更高响应层级)
- 通知机制(面向谁、以何种频率同步进展)
为什么它能降低扩张期的“组织摩擦成本”
扩张期最昂贵的不是一次故障本身,而是故障引发的沟通成本:群里反复@、不同说法、重复提交、业务方绕开系统走线下,最后形成“系统不可依赖”的集体认知。MTTR类SLA把故障处理变成可预期流程,能显著降低内部摩擦与情绪损耗。
实施要点与副作用提示
- 实施要点:把“恢复服务”与“根因消除”拆开承诺。很多故障需要先恢复业务,再在48小时/5个工作日内输出根因报告与永久修复计划。
- 副作用提示:如果只考核MTTR,可能诱发“快速恢复但不彻底修”的行为,导致同类故障反复出现。建议同时配套“重复故障率/同类事件复发率”作为内部运营指标(不一定写入对外SLA,但要写进运营看板)。
提醒:修复快不等于修复好,扩张期更需要把“复发控制”纳入复盘机制。
5. 迭代与变更成功率SLA—— 敏捷组织的助推器
定义:变更多时,成功率比次数更重要
很多公司在扩张期频繁进行:组织架构调整、审批链重构、绩效口径更新、薪酬规则调整、权限模型变化、接口字段扩展。系统“能改”不代表“改得稳”,因此需要用SLA约束变更质量:
- 变更成功率:按计划上线且未引发重大回滚/事故的比例
- 回滚时效:出现重大问题时,恢复到稳定版本的最长时间
- 变更窗口与冻结期:关键节点(如发薪前)限制上线,避免引发业务事故
- 变更验收标准:回归测试覆盖哪些关键流程、关键报表与接口
业务关联:组织变得快,但不能变得乱
在并购整合、新业务线孵化、区域扩张时,组织与权限变更往往是第一波动作。若变更失败造成审批链断裂、权限错配、数据口径混乱,会直接影响管理动作的执行,甚至造成敏感数据越权访问风险。变更成功率SLA把“敏捷”放进可控边界内:可以变,但要在可验证的流程下变。
边界条件:需要明确配置与开发的责任划分
人才战略系统常见两类变更:
- 配置型(流程、表单、审批、权限、字段映射)
- 开发型(接口、复杂规则、报表、二开)
两者的风险与周期完全不同。若SLA不区分,会出现两种极端:要么把配置变更当开发走审批拖慢速度,要么把开发变更当配置上线引发事故。
提醒:变更类SLA必须与“变更分级 + 回归测试清单”绑定,否则很难真正保障业务连续性。
表格1:5个关键SLA指标详解表(建议口径与业务影响)
| 维度 | 指标名称 | 建议基准值(参考范围) | 计算/判定要点 | 业务影响场景 |
|---|---|---|---|---|
| 稳定性 | 系统可用性SLA | 99.9%(关键模块可更高) | 明确是否含维护窗口;关键流程需单列可用性 | 月末算薪、绩效提交、全员自助高峰 |
| 安全性/可恢复 | 数据恢复SLA(RPO/RTO) | RPO:分钟级~小时级;RTO:小时级 | 需写明演练频率、验收标准与一致性校验 | 勒索病毒/机房故障/重大误操作 |
| 响应性 | 关键流程响应SLA | 以“端到端 + 节点”设定 | 约定暂停计时规则与责任边界 | 入职开通、组织变更生效、算薪出数 |
| 体验与效率 | 服务请求解决SLA(MTTR) | P1分钟级响应、小时级恢复(按公司容忍度) | 区分响应/恢复/根因修复;配套升级与通知机制 | 全员无法登录、关键报表异常、接口中断 |
| 成长性/可控变更 | 迭代与变更成功率SLA | 成功率目标(如≥95%)+回滚时效 | 绑定变更分级、回归测试与冻结期 | 并购整合、规则调整、接口字段扩展 |
三、落地路径——如何建立基于SLA的售后服务运营体系
SLA落地的难点不在“写指标”,而在把指标变成可执行的分级、监控、预警与复盘机制;一旦形成闭环,售后服务就能从成本项转为业务连续性的基础设施。
1. 差异化分级策略(P1-P4)(快速扩张的科技公司如何用5个SLA指标保障业务连续性?)
扩张期最常见的管理失误,是把所有问题都当“紧急问题”处理,导致真正的紧急问题没有资源保障。P1-P4分级的意义在于:用统一判据把资源调度制度化,避免靠情绪与关系决策。
分级建议遵循两条判据:
- 影响范围:全员/全公司 vs 单部门/单人
- 影响性质:是否阻断关键流程,是否影响合规与资金发放(工资、个税、社保)
此外,要把“谁有权定级”写清楚:一般由HRSSC/HRIT作为定级牵头人,业务方提供影响描述,厂商/IT提供技术确认。若由业务方单方面定级,P1会被滥用;若由技术方单方面定级,业务影响会被低估。
表格2:故障等级定义与响应时效对照表(P1-P4示例)
| 故障等级 | 定义描述 | 首次响应时间(示例) | 恢复/解决时间(示例) | 通知方式 |
|---|---|---|---|---|
| P1 | 核心业务阻断/全员不可用/影响发薪或合规 | 15分钟内 | 2小时内先恢复;24-72小时内根因修复计划 | 电话+群+邮件,按30-60分钟同步 |
| P2 | 关键功能受损,影响多个部门但可绕行 | 30-60分钟内 | 4-8小时内恢复或给出替代方案 | 群+邮件,按2小时同步 |
| P3 | 局部影响/低频问题/不影响关键节点 | 4小时内 | 1-3个工作日内 | 工单系统更新 |
| P4 | 咨询、体验优化、需求建议 | 1个工作日内 | 按迭代节奏排期 | 工单系统更新 |
注意:以上时效需结合公司规模、系统复杂度与供应商支持能力调整;更关键的是把“恢复服务”和“根因修复”拆开承诺,避免用同一时限要求全部动作。
提醒:分级策略一旦确定,就要配套“越级与滥用”的纠偏机制,否则P级别会逐步失效。
2. 全链路监控与预警机制
没有监控的SLA,最终会沦为“事后争论”。扩张期建议至少构建三层监控:
- 基础可用性监控:登录、关键页面、关键接口的探针监控;结合地域与网络条件,避免单点监测误报。
- 业务流程监控:关键流程的吞吐、排队、失败率、平均耗时;例如“入职提交成功率”“算薪计算成功率”“组织变更生效率”。
- 体验与工单监控:工单量、P级别分布、首次响应耗时、恢复耗时、重复故障率;并跟踪“关键节点前工单堆积”预警。
预警机制要解决两个问题:
- 提前量:不要等到SLA违约后才告警,而要在接近阈值时预警(例如可用性连续下降、失败率升高、MTTR超出历史分位)。
- 责任到人:预警触发后由谁确认、谁升级、谁对外沟通,要形成标准动作清单。
从实践看,“监控大屏”不是为了展示漂亮数据,而是为了让跨部门对齐同一事实。否则,业务说“系统又不行了”,技术说“我这里都正常”,扯皮成本会持续吞噬组织效率(本模块仅此一处类比:大屏更像统一度量尺)。
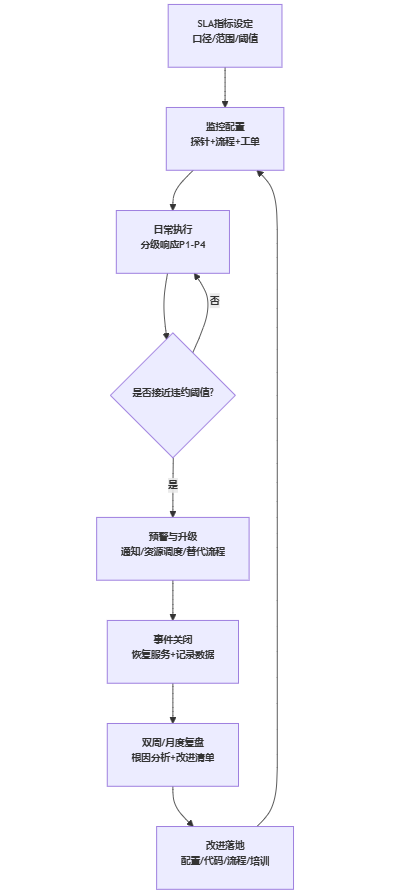
提醒:监控的覆盖面要与5个SLA指标一致,否则会出现“只监控在线率、不监控流程失败率”的结构性盲区。
3. 双周/月度SLA复盘机制
复盘机制决定SLA能否形成“持续改进”,而不是“持续救火”。扩张期推荐把复盘拆成两种节奏:
- 双周复盘(偏运营):聚焦工单与故障趋势、P级别分布、重复故障、关键节点风险。产出应是“下一周期要压下去的三类问题”与明确责任人。
- 月度复盘(偏治理):聚焦SLA达成率、重大事件根因、变更成功率、流程响应SLA的瓶颈段。产出应是“结构性改进项目”(如权限模型重构、流程节点合并、接口稳定性提升)。
根因分析(RCA)建议至少覆盖四类:
- 产品缺陷/性能容量问题
- 配置与权限治理问题
- 变更管理问题(测试不足、窗口选择错误)
- 组织协作问题(责任边界不清、沟通链路过长)
边界条件:如果公司没有授权复盘会对供应商/内部团队形成约束(例如不能推动版本修复、不能调整资源),复盘会迅速形式化。建议把复盘结论与采购付款节点、续费谈判、内部绩效/OKR挂钩,但要避免“一次事件一票否决”导致供应商保守不迭代。
图表3:SLA复盘会议与改进计划执行甘特图(季度示例)

提醒:复盘会的核心产出不是“会议纪要”,而是能被追踪的改进行动与验收标准。
四、价值验证——SLA体系对业务连续性的显性贡献
当SLA从合同条款变成运营闭环,它对业务连续性的贡献会从“感受”变成“可量化的管理结果”:风险可控、体验稳定、变更可预测,扩张节奏才不会被反复打断。
1. 风险量化与规避
没有SLA的风险管理,往往停留在“担心出事”;有SLA的风险管理,则可以回答三个可检查的问题:
- 出现最坏情况时,我们最多丢多少数据(RPO)?
- 业务最多停多久(RTO/恢复时限)?
- 如果发生P1事件,我们的响应链路是否可重复执行(分级与升级机制)?
扩张期的价值在于:风险被量化后,资源投入就有了决策依据。比如,是否需要额外购买容灾、是否需要在发薪前设置变更冻结期、是否要对关键流程做压测与容量评估。这些投入如果没有量化指标支撑,会被视为“成本”;一旦能对应到连续性风险的降低,就变成“必要的保险费”。
反例提示:如果公司业务本身对时点不敏感(例如研发型组织、无固定发薪压力的外包模式),过高的RTO/RPO投入可能并不经济;此时应把SLA重点放在变更成功率与流程响应上,而不是一味追求极致容灾。
2. 内部客户满意度提升
员工与经理层对HR系统的满意度,通常由两件事决定:
- 关键时刻是否可靠(发薪、绩效、入职)
- 出问题时是否可预期(多久恢复、是否有替代方案、沟通是否一致)
SLA体系把“可预期”写进了制度:
- P1事件有固定通知节奏与替代流程
- 工单有首次响应承诺
- 复盘有改进行动与复发控制
从实践看,满意度提升往往不是因为系统功能更炫,而是因为“不确定性减少”。当业务知道“遇到什么情况会触发P1、多久能恢复、谁来对接”,冲突就会显著下降,HR与IT也更容易从被动应付回到主动治理(本模块仅此一处类比:满意度更像稳定供给,而不是一次性促销)。
边界条件:如果企业内部需求入口混乱(微信群、私聊、口头插单),即便有SLA也会被绕开。建议在组织层面统一入口(工单系统/服务台),并用制度明确“非入口请求不纳入SLA统计”,否则指标会失真。
3. 支撑战略敏捷性
扩张期的战略动作往往很“硬”:并购整合、新业务线成立、组织从单一产品转多产品矩阵、从单城转多地。SLA体系在这些动作中提供三种能力:
- 变更可控:迭代与变更成功率SLA让上线更有纪律,减少“边跑边修”对业务的干扰。
- 复制可预测:关键流程响应SLA让新区域、新事业部的入职、权限、算薪节奏可复制,避免每次扩张都重走弯路。
- 协作可对齐:分级策略与MTTR机制把跨部门协作从“人情协调”变成“流程协同”,降低组织复杂度上升带来的管理成本。
副作用提示:SLA会强化流程纪律,但也可能让组织过度依赖“按条款办事”,对探索性需求不够友好。建议保留一条“创新通道”:对试点业务给更灵活的变更窗口与验收方式,但必须明确试点范围与退出条件,避免试点变成长期例外。
结语
回到开篇问题:快速扩张的科技公司如何用5个SLA指标保障业务连续性?关键不在“把指标写得更漂亮”,而在于用可用性、RPO/RTO、关键流程时效、MTTR分级、变更成功率这五类指标,把服务承诺固化为可执行的运营闭环,并在关键节点经得起检验。
可直接落地的建议(按优先级):
- 先选5个指标里的“关键流程响应SLA + 分级MTTR”做起:扩张期最能立刻减少摩擦与事故的,往往是流程时效与分级响应,而不是单纯追求更高在线率。
- 把RPO/RTO写成“可演练、可验收”的条款:明确演练频率、演练报告、恢复验收清单,避免灾难发生时才发现承诺不可验证。
- 建立统一入口与统一口径:工单系统/服务台是SLA统计与改进的基础;同时明确P1判定权与升级机制,防止级别滥用。
- 用“冻结期 + 变更分级 + 回归测试清单”守住关键节点:发薪前、绩效截止前、组织大调整期,宁可少改,也不要冒险上线。
- 让复盘结论能推动资源与版本:把SLA达成率与续费谈判、内部绩效或项目预算挂钩,但保留合理的例外与试点机制,避免僵化。
如果你的公司正处在从“能用”走向“可持续扩张”的阶段,人才战略系统售后服务体系的成熟度,往往就是业务连续性韧性的上限。